Dev: 1. Code Layout
This page describes the various namespaces in Asami, to help developers who may want to understand Asami's structure. The descriptions here are conversational rather than formal.
asami.coreasami.storageasami.memory-
asami.query asami.plannerasami.graph-
asami.index -
asami.multi-graph asami.common-indexasami.analyticsasami.internalasami.datomasami.entitiesasami.durable
This namespace provides the public APIs for users to talk to Asami.
The majority of code in this namespace is to wrap Asami in an API that looks like datomic.api. It is still a work in progress.
Most of the code is a relatively thin wrapper, with the exception of transactions that contain entities. This code is getting complex enough that it may need to move into its own namespace.
This describes protocols for Connection and Database. These are datatypes being managed by asami.core, and can be extended by various storage implementations.
This namespace implements the Connection and Database protocols in asami.storage for the in-memory graphs.
These are managed by keeping all old databases in a list inside the Connection. The db function can just get the most recent database from that list, while the as-of/as-of-t and since/since-t functions can search through the list looking for the requested database. This is done with the find-index function at the top of the namespace, which performs a binary search for a database with the desired time.
Each Database also keeps its history. Structurally, this is the same list that the Connection uses, without the latest Database at the start (this avoids a reference loop, which can't be done with immutable data). The structure for this is shown here:
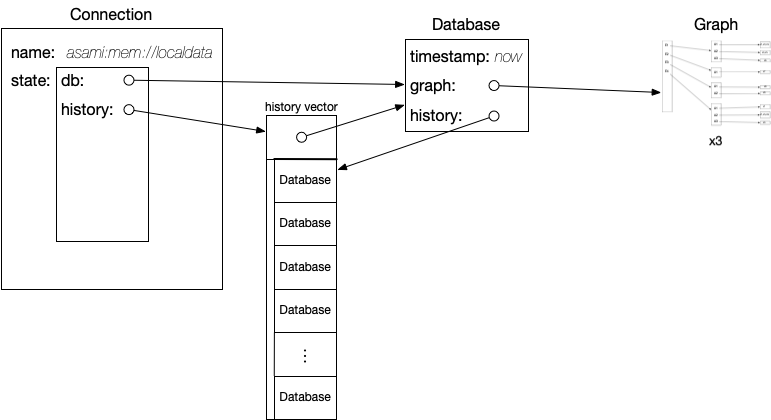
The remaining functions are mostly relatively light wrappers around the code that actually does the work in other namespaces. transact-data is probably the most complex of these, as it modifies the history list on a connection.# asami.datom
This defines the Datom type. It's not really important to Asami, but it helps in presenting data in a Datomic-compatible way. Datoms implement protocols so that they behave like a vector, but unlike a vector they are printed using their own toString operation, and can only be 5 elements long.
This is the code that executes queries.
Note that some of the code can use varying vocabulary for the same things. In particular, what Datomic called "Entity/Attribute/Value" is sometimes referred to in the code as "Entity/Property/Value" or EPV. There are also sections that may use the RDF terms "Subject/Predicate/Object"/
The bottom of the namespace does some of the work setting up queries. This means things like parsing the query and transforming it into a canonical form, and reading the parameters and setting them up in a form ready for processing. Example of this are:
- Converting patterns like
[_ :type "Person"]to use anonymous vars like[?__1234 :type "Person"] - Expanding short patterns such as
[:entity :attribute]to use anonymous vars:[:entity :attribute ?__1235] - Reading the
:inclause and converting parameters into bindings for appropriate variables, and setting up the default database.
The query is then run through the planner before execution. This is done in two parts. The first is to detect and plan for aggregate queries. If the query is not an aggregate, then the main planner is run. This can be defined by the user, or else it will use the standard planner.
Just above this, is the code for aggregate queries.
Aggregates try to be efficient by separating the parts of the query that form groups, and executing that as a single query (thereby creating each group). It then iterates through these groups, executing the remainder of the query for each one. The aggregate is calculated against each of these subquery results.
It's currently not perfect at pulling out subqueries like this, but it's close.
This is the main part of the query code.
- Step 1 is to get the query planner and run it against the query (see #asami.planner)
- Start with a set of bound data. If bound data is provided (via the
:inclause) then use this. If not, then get the first element of the planned query, and retrieve the data for this. It should be an entity/attribute/value pattern, which is a simple index lookup. If not, then the planner has a bug! This creates a "bindings" sequence. That's a sequence of individual bindings. A "bindings" here means a set of values that are mapped to variables. We usually think of this as a "row" of data. - Step through the remaining elements of the
:whereclause, joining them to the accumulated result. Each type of element has a different function:- entity/attribute/value patterns perform an inner join with the current result. This takes the current row (bindings) and uses it to set any shared variables with the pattern. The resulting pattern is then searched for in the index, and the results used to expand the current row: No results, means no row in the output. A single result just adds any new variables to the end of the row. Multiple results will return the original row multiple times, with each one expanded for the new variables.
-
oroperations will perform an inner join against each of their constituent parts, with their results beingconcat-ted together. -
andoperations should only exist inside anoroperations. These are executed, and the result becomes part of the outer expression's result. -
notoperations runs each row of the current results through a filter. The filter executes thenotclause as a subquery, and only those without a result are allowed through. -
optionalis a left-outer join. It's almost the same as an inner join (which can add a new binding to each row), but if there is no match then it just returns the incoming row. - Filters performs a standard
clojure.core/filterbased on an expression built from the query syntax. As each binding from the results is being filtered, the bindings are used in the expression as given. At one point this was done usingeval, allowing the expressions to have arbitrary complexity, butevalhas proven to be inconsistent in ClojureScript so the code now only allows simple expressions. - New bindings are performed in a similar way to filters, except instead of using
filterthey usemapwith the result being a new value in each row.
Because the process starts with a single result, which is then updated for each element of the :where clause in the query, the entire query is calculated with a reduce operation.
This takes a query and attempts to figure out an effective way to execute it. The final plan may not be perfect, but it should be good.
The general principle is based on the idea that the result of an inner join is usually no larger than the smaller of the two sides of the join. This may not be the case if the join describes a many:many relationship, as these can form an outer product, but these relationships are relatively rare in queries. In practice, an inner join will reduce the size of accumulated results.
Based on this assumption, conjunctions (the default operation, also defined by the and operation) are searched to find the element that will return the smallest result. The next element to be added will be one of an element that shares one or more variables with the variables already described. If more than one such element exists, then it select the first one that results in the smallest result.
Result sizes for expressions are based on:
-
Entity/Attribute/Value patterns: a
countoperation from the index. These should be fast. -
andoperations: The minimum size of all the component result sizes. -
oroperations: The sum of all the component result sizes. -
optionaloperations: Same asand.
Filter and binding operations are considered differently. As each element is added, the binding and filter operations are checked to see if the requisite incoming variables have been bound. If they have been, then the appropriate operation is added immediately. This means that filtering will occur as soon as possible, reducing the accumulating result as much as possible. It also means that bindings are available very early on in the process, making more inner joins and filters accessible at each step.
The end of the planner namespace is the code that identifies aggregate queries and splits them into inner and outer terms. This code also attempts to rewrite the terms into sum-of-products form. For these operations, a "Sum" is a Disjunction operation, which is specified by the or operation. A "Product" is a Conjunction operation, which is the default operation for elements in a :where clause, and is also specified by the and operation.
This provides the protocol for implementing a Graph. This is basis for all storage in Asami.
The Graph protocol is relatively simple, and requires the following:
- A function to create an empty version of the the current graph (
new-graph) - Functions for inserting and removing triples (
graph-add,graph-delete,graph-transact) - A function for finding entities that have changed from one graph to another (
graph-diff). This is optional. - A function for doing lookups in the graph, using a pattern of entity/attribute/value. (
resolve-triple) - A function for counting the resolution of a lookup. (
count-triple). This can be implemented by callingcounton the result ofresolve-triple, but most implementations will have a much faster mechanism.
There are also a couple of small helper functions in this namespace.
This is the primary in-memory implementation of the Graph protocol. It is implemented as 3 maps. Each map is a 3 level nested map, with the bottom level being a set.
This code was built using the RDF vocabulary of subject/predicate/object, so there are lots of references to SPO, etc.
The 3 indexes are:
- map of Subject to {map of Predicate to #{set of Objects}}
- map of Predicate to {map of Object to #{set of Subjects}}
- map of Object to {map of Subject to #{set of Predicate}}
Using the plumatic.schema notation for types, this looks like:
-
{Subject {Predicate #{Object}}}SPO -
{Predicate {Object #{Subject}}}POS -
{Object {Subject #{Predicate}}}OSP
The reason for these 3 indexes is that they permit any combination of subject, predicate and object to be looked up. To find all property/values for a subject, provide that subject to the SPO index and all of the predicate/object pairs are returned. To find all connections between a subject and an object, provide those values to the OSP index, and all of the predicate values can be returned. These indexes provide full coverage.
It is possible to skip the OSP index, and instead calculate its values from the SPO index, particularly since the list of predicates is typically short. However, this scheme is easy to maintain and very fast.
Also worth noting is that a 4th element can be introduced if desired (though this is not covered in the Graph protocol). If complete coverage were required, this would take the requirements of full coverage to 6 indexes. If the 4th column is labeled T for "Transaction", then these indexes would be:
- SPOT
- POST
- OSPT
- TSPO
- TPOS
- TOSP
Other combinations are also possible, but this combination of indexes includes the SPOT and TSPO indexes, which are the natural ordering for those values. 6 indexes is a lot, but fortunately, there is no real need for all of these, so the last 2 can be dropped. That means that finding patterns for a particular transaction would require a lookup for the pattern match, and then filtering for just the required transactions. This should be relatively cheap, because related statements don't usually appear in many different transactions, and ordered indexes can use binary search techniques to search for transactions more quickly than linear filtering.
Queries can also be made with the predicate set to be transitive. These are handled in the asami.common-index namespace, but are dispatched from resolve-triple and count-triple.
This is a protocol for describing basic nodes in a graph, and returns the labels of some special predicates. These are required for building and maintaining entities. That work is done in another project, called Zuko.
This namespace is identical to the asami.index namespace, with the exception that it handles multiple identical edges. This is done by storing a count of the edges of that type. The indices therefore look like this:
-
{Subject {Predicate {Object {:count Num}}}}SPO -
{Predicate {Object {Subject {:count Num}}}}POS -
{Object {Subject {Predicate {:count Num}}}}OSP
To avoid the need to call graph-add multiple times, the multi-graph-add function is provided, which can specify the number of times an edge is to be added. This will set the :count value for a triple directly.
We have not been expecting to store a transaction ID for in-memory graphs, but if they are included in the future then this index can do that by adding the value to the map containing :count.
This namespace calculates transitive operations for nested-map indexes as found in asami.index and asami.multi-graph.
The top functions support testing predicates to see if the request was for a transitive operation, possibly updating the predicate name to its non-transitive form, if needed. This is because one mechanism for indicating transitivity is to put a + or * character on the end of the predicate (whether it be an atomic value, or a variable). The other test is to see if a lookup pattern has metadata with a :trans property.
The operations for getting transitive patterns are oriented around nested maps, but they are still relatively general purpose and can be ported to other index types (specifically, the durable types currently under development).
This namespace is specifically for graph analytics utilities. This is similar to the code in common-index, and is currently focused on nested-map implementations.
For now, the only operations available are subgraphs and subgraph-from-node.
The subgraph-from-node function starts at a node and walks out around the graph to find all connected nodes (both incoming and outgoing). It does not traverse literal values, so if two distinct subgraphs refer to the number 5, or to the string "Hello" then they will still be considered distinct. "Blank Node" objects will also not be traversed, even if they appear in both graphs, since the use case for this is entities that appear in subgraphs together.
The subgraphs function finds all disconnected subgraphs in the graph, and returns them as a sequence. It does this by selecting a node, and then walking out the graph from there. Once it has built this subgraph, it continues through the index looking at subject nodes, until it finds one that is not in a subgraph, and creates the next subgraph from that node. When all the subject nodes have been identified as belonging to known subgraphs, then the list of subgraphs is returned.
The Zuko project requires a couple of implementation-specific functions to be available during projection. This namespace defines that. It used to contain more code that has since been sent to Zuko, so it may now be small enough to merge into another namespace (most likely asami.core).
This namespace declares the Datom datatype. The primary purpose of this datatype is to report the pieces of data that have been given to the database. Unlike other databases, Datoms are not stored directly in Asami. Instead, they get rebuilt from the indices.
The majority of this namespace is devoted to making Datoms behave like 5 element vectors, with each column associatively named with the keys:
:e :a :v :tx :added
This namespace converts transactions with entities (nested map objects) into transactions of triples. It uses the asami.entity.writer namespace for converting entities into statements for storage, and the asami.entity.reader namespace for reading statements to convert them back into entities. It also performs queries to identify existing entities that are being modified, and how those modifications need to occur.
This is not a namespace, but rather a directory for a number of namespaces that are a TODO item for this page.
The asami.durable section contains implementations of the Connection and Database protocols in asami.storage for durable graphs (see asami.durable.store). At this point, the only implementation uses memory-mapped files, but it is on the roadmap to create other implementations as well.