

Zincbase is a batteries-included kit for building knowledge bases. It exists to do the following:
- Extract facts (aka triples and rules) from unstructured data/text
- Store and retrieve those facts efficiently
- Build them into a graph
- Provide ways to query the graph, including via bleeding-edge graph neural networks.
Zincbase exists to answer questions like "what is the probability that Tom likes LARPing", or "who likes LARPing", or "classify people into LARPers vs normies":
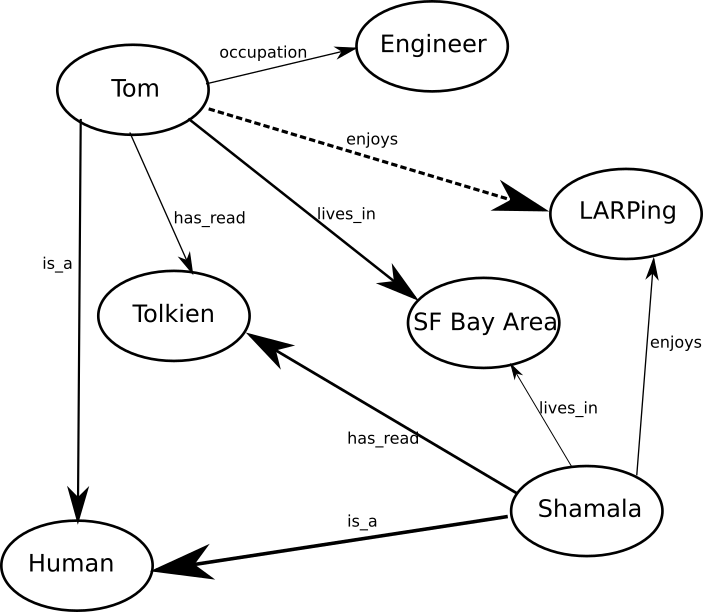
It combines the latest in neural networks with symbolic logic (think expert systems and prolog) and graph search.
View full documentation here.
from zincbase import KB
kb = KB()
kb.store('eats(tom, rice)')
for ans in kb.query('eats(tom, Food)'):
print(ans['Food']) # prints 'rice'
...
# The included assets/countries_s1_train.csv contains triples like:
# (namibia, locatedin, africa)
# (lithuania, neighbor, poland)
# Note that it won't be included if you pip install, only if you git clone.
kb = KB()
kb.from_csv('./assets/countries.csv')
kb.build_kg_model(cuda=False, embedding_size=40)
kb.train_kg_model(steps=2000, batch_size=1, verbose=False)
kb.estimate_triple_prob('fiji', 'locatedin', 'melanesia')
0.8467
- Python 3
- Libraries from requirements.txt
- GPU preferable for large graphs but not required
pip install zincbase
This won't get you the examples or the assets (except those which are automatically downloaded as needed, such as the NER model.) Advanced users may instead wish to:
git clone https://github.com/tomgrek/zincbase.git
pip install -r requirements.txt
Note: Requirements might differ for PyTorch depending on your system. On Mac OSX
you might need to brew install libomp first.
python -m doctest zincbase/zincbase.py
python test/test_main.py
python test/test_graph.py
python test/test_lists.py
python test/test_nn_basic.py
python test/test_nn.py
python test/test_neg_examples.py
python test/test_truthiness.py
"Countries" and "FB15k" datasets are included in this repo.
There is a script to evaluate that ZincBase gets at least as good performance on the Countries dataset as the original (2019) RotatE paper. From the repo's root directory:
python examples/eval_countries_s3.py
It tests the hardest Countries task and prints out the AUC ROC, which should be ~ 0.95 to match the paper. It takes about 30 minutes to run on a modern GPU.
There is also a script to evaluate performance on FB15k: python examples/fb15k_mrr.py.
From docs/ dir: make html. If something changed a lot: sphinx-apidoc -o . ..
From the repo's root dir:
python setup.py sdist
twine upload dist/*
- Add documentation
- to_csv method
- utilize postgres as backend triple store
- The to_csv/from_csv methods do not yet support node attributes.
- Add relation extraction from arbitrary unstructured text
- Add context to triple - that is interpreted by BERT/ULM/GPT-2 similar and put into an embedding that's concat'd to the KG embedding.
- Reinforcement learning for graph traversal.
L334: Computational Syntax and Semantics -- Introduction to Prolog, Steve Harlow
Open Book Project: Prolog in Python, Chris Meyers
Prolog Interpreter in Javascript
If you use this software, please consider citing:
@software{zincbase,
author = {{Tom Grek}},
title = {ZincBase: A state of the art knowledge base},
url = {https://github.com/tomgrek/zincbase},
version = {0.1.1},
date = {2019-05-12}
}
See CONTRIBUTING. And please do!