

Welcome to the BEAD Inspector, presented by the University of Chicago's Data Science Institute and Internet Equity Initiative.
As part of the NTIA BEAD Challenge process, eligible entities are required to submit a specific set of data deliverables to the NTIA. The purpose of this package is to validate NTIA BEAD challenge process data (against the official specification and Notices of Changes to Process) and provide feedback that helps Eligible Entities identify errors in their submittable CSVs.
More information on the BEAD Challenge process can be found:
Importantly, this is not an official package supported by the NTIA. The authors of this package present this without any warranty or guarantees.
This package requires knowledge of the command line and a computer installed with Python and pip. The code has been tested on both Windows PCs and Macs.
This package focuses on a set of data quality issues that are easy to overlook when submitting your challenge results. This package will check the following files for the following issues:
|
Quality Checks
|
|---|
- Availability / Fabric Validation: This package does not check locations against the FCC Fabric or FCC Availability Data.
- Correctness of open text fields: There are a number of open text fields (such as
resolutionin thechallenges.csvfile. BEAD INSPECTOR checks to make sure that these fields are not empty, but does not check to verify the correctness of the content.
This python package is installed via pip and can be used directly from the command line following the instructions below. Refer to the advanced usage section for non-command line use.
Make sure that you computer has access to Python and Pip. You can do this by going to the command line and typing pip --version and python --version. Both of these should return version numbers. The Python version needs to be greater than 3.7. As with all third party packages, we recommend using a virtual environment, but it is not required.
This package can be installed via python's package manager, pip, by typing pip install bead_inspector at the command line.
-
Put all files that you wish to have checked in a single directory, noting the location. Make sure that all filenames conform to the NTIA standard filenames. If you wish to only check a subset of the files, put that subset inside the directory. Bead Inspector will only analyze files that it finds in the specified location. See here for NTIA standards
-
Once files are copied, enter the following at the command line, making sure to put a full path location.
> bead_inspector /path_to_files -
Note that running the command may take a few minutes, depending on the size of the files.
-
Once the command is complete two files will be generated:
path_to_files/reports/BEAD_Data_Validation_Report_{DATE}_{TIME}.htmlpath_to_files/logs/validation_issue_logs_{DATE}_{TIME}.json
The html file in the reports subdirectory is a human readable version of the report. For most users this is the file that should be used to evaluate the quality of the reports. The json file is presented in case you wish to programatically interpret the resulting files.
Within our report we denote two different levels of checks:
- Errors: Checks which are errors are extremely likely to need to be fixed before submission. Examples of this would include required fields missing, etc.
- Info: Our Info level are checks which may or may not need to be fixed, depending on the circumstances of your submissions. For example if an eligible entity has submitted area challenges then, per NOTCP 07/002, the
challengerfield in thechallenges.csvfile should be left empty, which is in contrast to the original policy notice. As such we generate an "Info" level issue as this may need to be fixed depending on the specific challenge requirements for your state.
When a report is generated there are three sections:
|
|
The header material consists of a Title, which states the date that the report was run and summary information. The summary information is broken out by Errors and Info level issues. The first column is the data format, which is the name of the CSV that is being analyzed. The second column specifies the level of the issue. The third column specifies the number of issues of this level found in the file. Finally the last column in the table specifies the total number of rows found in that file. |
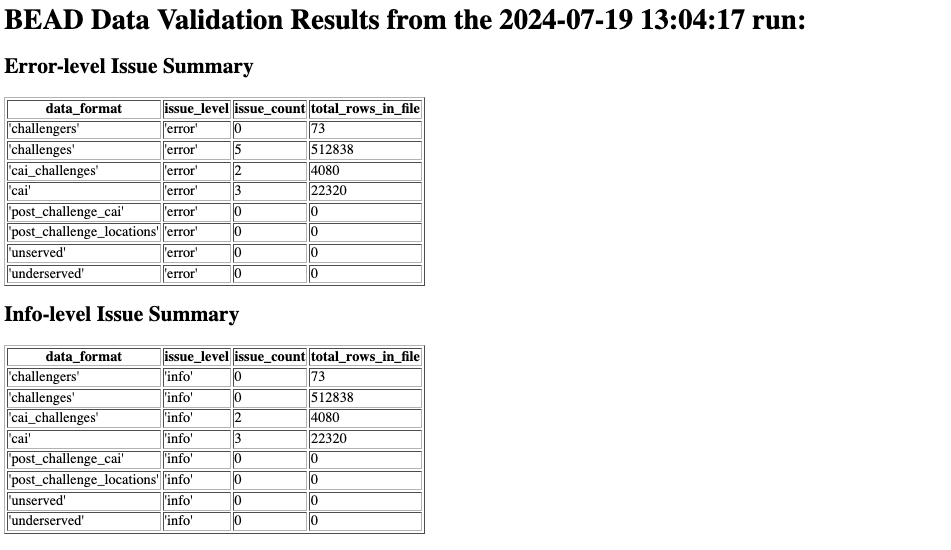
|
|
The Table of Contents contains a list with links to specific issues found, organized by the level of the issue found (Info / Error). They are numbered, in order, starting from one and the issue name is of the format: {File where issue was found} :: Name of Issue :: [Optional: Type of Issue] |

|
|
Detailed information regarding the specific issue can be found in this section. There are a few new fields that were not previously discussed:
|

| Where does the report go? Does the NTIA see this? What about UChicago? |
|---|
| NOPE! You can look at the code in this repository and see that nothing is reported to NTIA or the University of Chicago. This is simply a tool to identify potential problems. What you do with the report is up to you! |
| Some of the issues seem to duplicate, why? |
|---|
| Some of the checks that we have in place do overlap with other issues. Missing and nulls, for example, can run afoul of multiple NTIA rules. |
| What if I only want to have some of the files to check? |
|---|
| BEAD Inspector only checks the files which 1) are present in the target directory that 2) follow the NTIA file naming conventions. If a file is missing, a warning will be issued, but the tool will check all files present in the target directory |
| There is a rule that I think BEAD Inspector should check that it is not checking. |
|---|
| Please add an issue to the issue page. |
| I found a bug! |
|---|
| Please file an issue using the issue page. We will do our best to fix it as soon as we have time. If you are more technically skilled and know how to fix the issue please put in a pull request. |
If you find a bug or wish to highlight an issue, please use the github tools above. If you wish to help with development of this project, please submit a pull request which describes the code changes that you are making and why.
You can programmatically access BEAD inspector by importing the package and passing it a directory containing the files.
from pathlib import Path
import bead_inspector
bcdv = bead_inspector.validator.BEADChallengeDataValidator(
data_directory=Path("path/to/dir/containing/csvs"),
single_error_log_limit=5,
)You can also generate a report from an existing log file, such as in the example below.
from pathlib import Path
import bead_inspector
issues_file_path=Path("path/to/logs_dir/validation_issue_logs_date_time.json")
reporter = bead_inspector.reporting.ReportGenerator(issues_file_path)This will output a report file (HTML) to the /reports/ directory parallel to /logs/ directory containing the .json file of issues.
The directory of CSVs (/output_csv/ in the above example) should look like this now (with a new .json file and .html file being added each time BEADChallengeDataValidator() is run).
$ cd output_csv/
$ tree
.
├── logs
│ └── validation_issue_logs_20240714_113216.json
├── reports
│ └── validation_issue_logs_20240714_113216.html
├── cai_challenges.csv
├── cai.csv
├── challengers.csv
├── challenges.csv
├── post_challenge_cai.csv
├── post_challenge_locations.csv
├── underserved.csv
└── unserved.csv