[css-text] Add new CSS text-transform values for math #3745
Comments
|
After discussing this with @fred-wang and @mrego, I think that we agree that we probably want the values list to be just That's more in keeping with what is there today, it's one less character to type, and it doesn't get us into a whole host of other questions about why is it a function, what does the function produce and so on. Ultimately this is really just a name that identifies the transform, I think, and unless we want to start tackling the thing at the end of section 2
And try explaining these in terms of those then I don't think there is a need for more. But, I also don't think that's necessary or maybe even desirable because of what/where this sits? |
|
I think this is a good idea. In addition to their use in math typesetting, these characters have gained some notoriety as faux-fonts & it would be nice to have a way to use them without destroying the meaning of the text content. (It wouldn't get rid of the underlying reason they became popular: social media that supports full Unicode but not rich text formatting. But, it would mean that a conscientious web developer working an a CSS environment could recreate that visual effect in an accessible way.) I agree with Brian about using keywords instead of a function notation, since the Some other thoughts:
|
I did have a go at it a while back. If someone wants to revive / refine / debug this, let me know: https://specs.rivoal.net/css-custom-tt/ |
Thanks for the feedback! About keeping the meaning of the text content, from the math point of view, a A with fraktur style should have the same meaning as the transformed character MATHEMATICAL FRAKTUR CAPITAL A' (U+1D504). Or at least a11y tools should find some way to indicate that it is a fraktur A and not a normal A. Not sure if that's the case currently for text-transform, see for example https://groups.google.com/a/chromium.org/forum/#!msg/chromium-accessibility/enk1PBjEfRc/InWurOYUg0EJ
Yes, sorry that was a misunderstanding on my side. I thought the CSS WG had requested to change my initial proposal to use
AFAIK not with current CSS capability. It's not "mi with no children" but "mi with a unique text node which itself has a single character" (e.g.
I personally don't know math use cases for that. At least for MathML, accents (https://en.wikibooks.org/wiki/LaTeX/Special_Characters#Math_mode) are generally placed in a separate
I think Brian's grammar does not allow mixing math-* values with others (if I understand correctly https://drafts.csswg.org/css-values-4/#component-combinators). That was the initial intention since I'm not sure there is a clear use case for that (again from the math point of view). However, I agree that mixing math-* values with capitalize, uppercase or lowercase has obvious interpretation and could be acceptable, at least for latin letters. If so, I believe the grammar should be something like
But maybe we just want to allow to mix everything and ignore transforms that don't make sense, so that the grammar is just
|
That's a good point, and is different from how we want assistive text to expose text-transform changes to case. It doesn't mean it isn't do-able, it just means that the accessible version of the transformed text needs to be clearly defined. You'd want to get input from people who work on tools that expose math to screen readers and Braille display and so on, to find out how they implement it. |
As a screen-reader developer, my preference is that the transformed/rendered text is what gets exposed via the platform accessibility APIs. For instance if the DOM text is "foo", but that gets CSS transformed into rendered text of "FOO", Screen readers, as a general rule, want to present the content sighted users see. Exactly how it got rendered is, more often than not, irrelevant.* Furthermore, it's a drag for an AT to have to take every single bit of accessible text, retrieve some additional property "just in case", and occasionally do additional work to transform it. The render tree already contains the final/displayed version, so please share that with me. 😄 *But if any ATs might have a need, exposing the transform property as an attribute on the accessible object shouldn't hurt anything and should be relatively easy to implement within the user agent. |
|
@joanmarie, I am genuiely curious, can you explain a bit more about why you'd want the transform to be preserved in general? How do screen readers read words in all uppercase? For instance, if text-transform:uppercase is applied to a first line, how does that get read out? |
Because one of the primary functions of a screen reader is to present (in speech and in braille) what is on the screen. If sighted users see capital letters and blind users see lower-case letters, the latter group is missing out on information. And at least some of them -- if not many of them -- would report it as a bug in the screen reader.
That depends on two things: 1) The screen reader and 2) User preference. For instance some screen readers have options like:
The user can then pick which option(s) work best, and often configure the options on a per-app basis. For the braille display, the indication would be based on the braille code being used. For instance, in the U.S. each capitalized word would be preceded by two dot-6 cells. |
|
Thanks for the insights, @joanmarie. This is very different from the "common sense" (but I guess outdated) advice I'd been given — that one should always use For the math use case, it does greatly simplify things if the proper accessibility practice is to expose the formatted text. It doesn't help the accessibility issues of decorative-characters, though, but I think that's beside the point, since this is already an accessibility issue without |
|
FWIW, user agents are already exposing the rendered (transformed) text. Below are three screenshots, the first from Firefox Nightly, the second from Epiphany (WebKitGtk), and the third a locally-built Chrome. All three are from Linux. I can grab macOS next in case that would be helpful. In the meantime, what you'll see in each is that I've:
So the good news is that I'm already getting what I'd expect/want. 😄 Assuming this is the same on other platforms (my guess is that it is, with one caveat I'll come back to momentarily), it really doesn't matter if you type a literal all-caps or use CSS to transform it into all caps -- as far as the end user is concerned -- because the end user will wind up with the same result regardless of whether or not he/she happens to be sighted. The caveat I mentioned is this: Some (Windows) screen readers historically have had virtual buffers or other recreations of the content. For any that still do: If they are grabbing the text from the DOM rather than from the accessibility tree, then one might indeed see differences in what the end user gets.
|
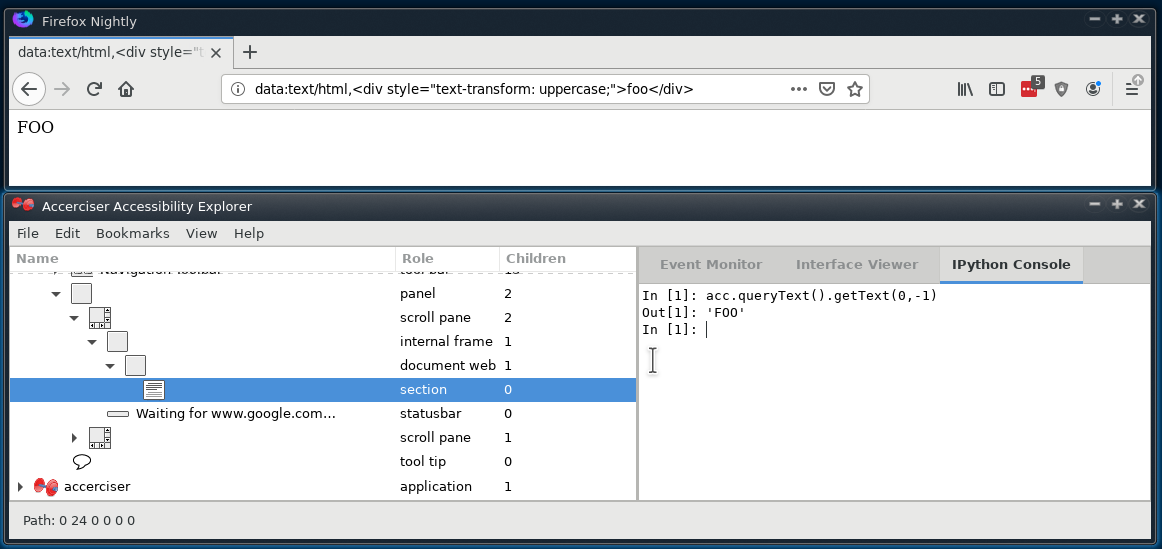
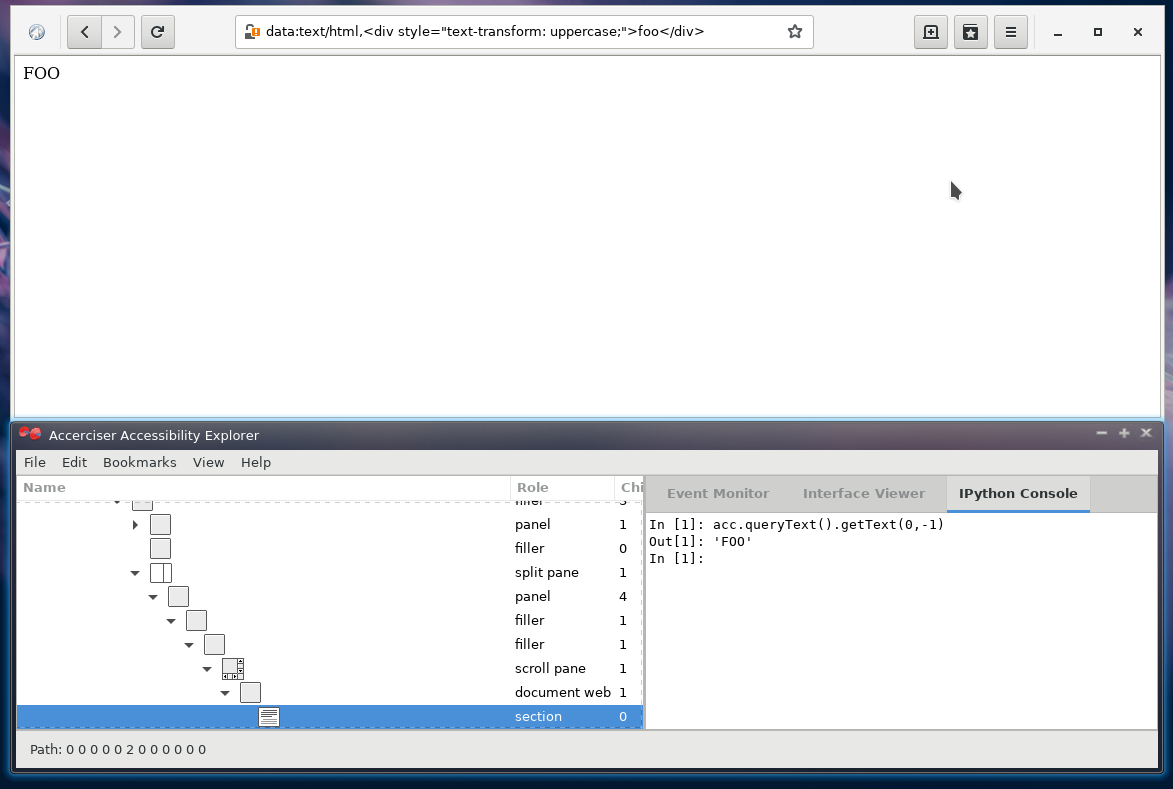

|
Update: On the Mac, I just performed the same experiment using Chrome Canary and Safari Technology Preview. And I got the same results, namely the accessible value obtained by inspecting the element with XCode's Accessibility Inspector is the all-caps, rendered "FOO." |
|
@joanmarie (disclaimer: you clearly know what you're talking about. I am not dismissing your expertise, but trying to understand it, as it doesn't quite mesh with my own sense of how this is supposed to work). This is a bit counter intuitive to me, as I'd expect an upper-casing text transform to be the stylistic in the same way as a font-feature or a color change would be, and therefore that it should not be preserved, to avoid having Also, only having access to the post-transform text seems to play poorly of the i18n oriented values:
All in all, I'd definitely expect the styling information to be available to the screen reader so that it can do something useful with it and inform the user of notable styling features that are deemed relevant (such as, as you mentioned, playing some tone, changing the voice pitch, displaying two dot-6 cells on a braille display, or whatever is appropriate), but I'd expect the text itself to be the untransformed text. If we don't have that, I don't really understand what the point of having text-transform in CSS instead of doing some server side preprocessing change to the document content itself (or the same DOM change in js/react/vue/… for people who're more fashionable than me). |
|
Also, picking form the explainer:
That seems like an argument for having it in markup rather than via CSS. If it's in CSS, this nformation would get discarded as stylistic for example when displaying in reader mode, or when the same content is picked up by a web crawler… |
|
Exposing 𝕸, as "M" rather than "mathematical bold fraktur capital M" is wrong. It's very common in math text to use the same letter with different "style" to convey different meanings, so we really want all users to be able to distinguish them. That was the rationale for proposing these new characters to the Unicode standard and the reason why they were accepted. Arguably, people who rely on these in social networks for purely stylistic purpose are doing misappropriate use, they should rather keep the original ASCII letters with a different font (which as said above is not easy/possible in social networks). This text-transform proposal is based on the MathML @mathvariant attribute. Originally, the idea for this MathML attribute was to help systems that do not support non-BMP characters very well while still trying to preserve the semantic. It turned out that it is also useful for bottom-to-top LaTeX-to-MathML converters (e.g. fast ones generated LALR parsers) or other MathML generators. The MathML CG has been discussing deprecating/removing this attribute (since it actually duplicates direct use of transformed character) but unfortunately it seems it is still widely used ( w3c/mathml#77 ). Hence we still need one implementation. For browser implementation, experience has shown that we want to implement mathvariant by relying on CSS inheritance (rather than implementing a MathML-specific inheritance like in WebKit or older Gecko versions) and to do the character transform at the same place as text-transform (otherwise we get limited and hacky support like in WebKit or older Gecko versions). Since WebKit (and Chromium?) does not have this notion of "internal" CSS property and since text-transform is very similar, this proposal tries to rely on this existing support to make implementation easy. To make things more complicate, there is this "math-auto" value to render variables with a math italic (that is visually different from CSS italic) and is provided by math fonts in the math italic unicode range. This is instrumental to get beautiful rendering of math equations but does not really convey semantics, so should not be exposed to assistive technologies so the spec should probably mention it. Authors won't use the transformed characters in that case. I guess in any case the spec should be amended to say how the characters are exposed to assistive technologies. math and Asian examples mentioned above suggests it could depend on text-transform values. |
|
In school and university, I was exposed to several approaches to styling vectors, all of them conventionally using a single lowercase roman letter:
There are probably other customs as well. As an author, I would expect to have all of these choices in a single location or in a unicorn way:
CSS is obviously hardly concerned with the first of these three options and best suited for the third one. It can be used as the (overridable) backbone for the second variant as well. The first variant, Unicode, has all cases covered, either using the infamous math alphabets from SMP or combining diacritics like U+20D7 and U+0331. I guess that makes sense, but also constitutes an argument to make |
|
Wrt accessibility, agreed 100% with @frivoal's comment in #3745 (comment) The entire point of 'text-transform' is to alter visual styling without changing the underlying content as it is read aloud or presented in alternative ways (e.g. alternate styling, reader mode, etc.). If AT is exposing these transformations when reading text aloud, this means we have no way to make these visual transformations without distorting the text for AT. I think @frivoal's examples of ::first-line capitalization and full-size-kana show why dissociating the visual and AT texts is sometimes appropriate and useful. Currently Which brings us back to the original point: should we add these values to better support MathML. I'm not entirely clear on the problem we're trying to solve here and why this would be the right approach. If math wants to shift visual styling to better reflect semantics already in the document, that would be inherent even if CSS is turned off, then that's one thing. But if this request is because it is more convenient to do the transformation in CSS than in a preprocessor even though it should be done in a preprocessor, then I don't think that's a good justification for adding it to CSS. (If the concern is just about fallbacks between glyphs assigned to these math Unicode codepoints vs font variations, we can talk about how to solve that at the glyph selection level.) Are there fundamental use cases other than supporting the mathvariant attribute that we need to solve? |
|
Regarding accessibility, the line between content, semantics and styling is not as clear-cut as one might hope. Puristically, it's tempting to say that CSS is purely for styling and nothing else. In reality, that isn't entirely true any more in the real world. Two examples which demonstrate this clearly:
On the flip side, we've come to realise that we do not want to reflect CSS display: block on tables, display: contents, etc. for accessibility. text-transform is a grey area, IMO. On one hand, it can cause weirdness for speech. On the other, if someone chose to render something a certain way visually in a particular view of the text, they clearly did that for a reason. Braille in particular tries to provide a mapping to prevalent visual text features. Braille has indicators for capitalisation, bold, italics, etc. You'll note that these are not called emphasis, strong emphasis, etc.; they are not purely semantic. When we talk about accessibility, we cannot think about speech alone. Finally, there's a technical concern. We absolutely must support things like |
In that case, the difference should be preserved even when css isn't applied, and so it should be in the document itself, not in its CSS. Removing css from a document is a thing that happens (bad network, reader mode, search engine crawler, same data in an RSS feed…), and it should not modify document semantics. Authors should not rely on css for document semantics. So the question is not whether "𝕸" should be read as "M", but whether "M" should be read as "M" when it's been styled to look like "𝕸". When authors actually mean 𝕸 and not "M styled to look like 𝕸", they should put 𝕸 in the document. Just because CSS has selectors and selectors are a convenient generic mechanism doesn't make CSS into the right mechanism for solving all kinds of problems.
To me, this just means that braille terminals are capable of applying some styling, so they should look at CSS to decide what styling to apply. The point is not that styling is useless. It certainly isn't, and assistive technologies should style things to the extent they can given their particular constraints. But things that must remain even when styling is dropped should be in the document, not in css.
I'm not a purist about this. I think the line between style and not style is sometimes fuzzy, particularly around UI/UX things. But "if you don't apply this bit of CSS, the meaning of the document changes and becomes wrong or misleading" is a very strong sign that CSS is the wrong tool for the job. "It's hard to type" is an argument for a better IME or a better processor. Not for new features in CSS. |
That's what happens now. Braille terminals are not a browser. They are controlled by screen readers, which in turn get their information from browser accessibility APIs. And those APIs currently expose "text content". As explained in my previous comment, we expose "rendered" text because of |
|
Thank you everybody for the feedback. First let me do a small digression as I'd like to clarify the somewhat separate MathML thing, which is the main motivation for this proposal:
Now coming back to the CSS issue, I thought extending text-transform for these existing math characters is sensible and would be easy to implement and test (do everybody agree with that?). Igalia offers to implement it and we already have some similar tests for mathvariant, and it is important for native MathML implementations as I previously explained. In addition, it could be useful for people implementing "math polyfill" e.g. using some CSS stylesheet with Regarding the a11y issue, I believe a11y and CSS people should first agree on whether to expose the text-transform text as what the CSS spec says and the actual a11y implementations seem to differ. I don't see any consensus on this thread or https://groups.google.com/a/chromium.org/forum/#!msg/chromium-accessibility/enk1PBjEfRc/InWurOYUg0EJ. Probably this can be discussed in a separate GitHub issue and we can still add these math text-transforms in the meantime. Depending on the outcome, we would either have nothing to do to make mathvariant accessible (my personal preference) or keep doing the extra effort that we experimented in (5). |
|
On the question of whether semantically essential styling should be in the document (@frivoal's comments), I think a good comparison is HTML So if MathML supports ASCII text that gets upgraded to mathematical formatting using an attribute, that is still preserving the semantics in the document. But if it removes some of the "magic" of the rendering to describe the effect of that attribute through a CSS style, then keeping semantics in the document shouldn't be an objection to the style rule. |
|
What is essential is that different types of variables, e.g. scalars and vectors, be typographically distinct. However, the actual choice of appearance is a matter of style. Someone gave this example already: vectors in particular can be presented in many ways. That makes a text-transform a reasonable tool in defining how to render certain constructs in different environments (different documents). For accessibility, what should be passed on to the screen reader would ideally be the semantic value (e.g. vector) and not the raw choice of rendered value. Certainly, it would be more useful to hear "vector a" than "mathematical bold small a". That would presuppose that styling is associated in a logical way with semantic information somewhere, e.g. via a class=vector, perhaps. |
Ideally browsers' "Find in Page" feature would allow searching for the text pre-transform and post-transform. That way, for example, I could search for the variable 𝒙 on the page by searching for either "x" or "𝒙". Firefox's MathML implementation does this, for example. |
|
The CSS Working Group just discussed The full IRC log of that discussion<emilio> Topic: (css-text) Add new CSS text-transform values for math<emilio> Github: https://github.com//issues/3745 <emilio> fantasai: I really think this should be done with i18n experts <emilio> ... probably at tpac <emilio> Rossen: who added it to the agenda? <emilio> bkardell_: I did <emilio> Rossen: are we ready to discuss this? <emilio> bkardell_: there were very strong objections when I added it to the agenda but it seems that has been solved <emilio> bkardell_: I'd like to make some progress on that issue <emilio> astearns: what's the points you're talking about? <emilio> bkardell_: the philosophy of text-transforms and how it interacts with a11y <AmeliaBR> q+ <iank_> q+ <emilio> bkardell_: we have a new transform that prob. needs to do something different <emilio> ... the are at least two answers to the questions <emilio> florian: I think that's why we need other experts on the discussions <emilio> ... because whether text-transform affects the semantics is complicated <emilio> fantasai: I think text-transform, if we're stuck for compat with a11y for capitalization that's unfortunate, but we shouldn't introduce the same for math <fantasai> https://github.com//issues/3745#issuecomment-478206009 <emilio> florian: once we have the markup communicate the semantics, we probably want text-transform to affect some of the presentation but not a11y <emilio> bkardell_: my understanding is that we'd encourage putting it in the markup, but there's a bunch of legacy content which is what would make this necessary <emilio> AmeliaBR: I think florian's point is that you could have a presentation transform but the accessibility stuff should be in the markup <emilio> bkardell_: I'd like to get some kind of checkpoint on this <emilio> AmeliaBR: the question is: "for math-variant to be exposed and accessible, does it need to be exposed through text-transform transforming the text-content, or via an attribute that gets passed to the a11y tree, which _also_ gets a UA rule to make the presentation change' <emilio> fantasai: I think that's the right way to go, and gives you the ability to give more accurate info to a11y that doing unicode transformation <emilio> ... unicode transformation doesn't contain math semantics <emilio> ... that needs to be in the markup, if that information is in the content it should be given to a11y that way, rather than via text-transform <emilio> ... a11y doesn't say "Bold", it uses the fact that you're on <strong> <emilio> AmeliaBR: actually that's not true, a11y is trying to introduce roles for <strong> and similar, authors don't distinguish <i> or <em> <emilio> ... if there's an italic <span> in a header it'd be called out depending on the verbosity level <emilio> Rossen: it calls out format stops <AmeliaBR> s/a11y/ARIA WG/ <emilio> bkardell_: there's a similarity here with html's kinda-weak semantics, a11y tools get mostly plain text with other hints, for math a11y my understanding is that some tools use the unicode information <emilio> Rossen: we don't support mathml in Edge <emilio> bkardell_: well, Edge does parse mathml as XML content <emilio> ... which is why mathml is a kinda weird place <emilio> Rossen: [describes how a11y works in Edge and how screen readers can poke at the DOM / render tree in non-Edge (Chromium / Firefox)] <emilio> Rossen: Edge doesn't allow third-party processes in its process <emilio> bkardell_: please fact-check me :) <emilio> florian: I think this is a topic for TPAC, since different a11y experts have diverging oppinions <emilio> Rossen: are we going to make any progress? <Rossen_> q? <emilio> bkardell_: do we have some specific questions/ <emilio> *? <astearns> ack AmeliaBR <astearns> ack iank_ <emilio> AmeliaBR: I think my point was previously said, so to wrap up: We're saying that the specific proposal is to take it back to see if we can decouple the style and the markup a11y, and defer for TPAC? <emilio> bkardell_: yeah <Rossen_> ack iank_ <emilio> iank_: seems like the people objecting about text-transform is just about a11y, is that correct? <emilio> AmeliaBR: yeah, it's about whether it sees the characters for a11y before or after transform <emilio> florian: it's not just about a11y but more generally the semantics, like what would happen in reader mode and such? <emilio> iank_: another point is that mathml has a lot of legacy content, and mathml does this in a very magic way. We don't want to get in a situation where other math libraries cannot opt-in to this power <emilio> Rossen_: let's stop here for now |
|
This point relates to the comment @tabatkins made in #3746 (comment) If we're in situation (1), then this isn't needed, but it is if we're in the others. Personally, my feeling is that the mathml mathvariant attribute should continue to be the main way that such variant letters are selected, and this attribute should be the thing that causes the accessibility tree to carry the transformed variant. In addition, it seems reasonable to also have the text-transform values, but these would not cause the text in the AT to be transformed (although there could/should an annotation in the AT indicating that the text has been transformed, separately from the text itself). These text transforms could certainly be used in the UA stylesheet as the mean by which the visual rendition is achieved though. This way:
If we wish to generalize the ability to character transform that affect the AT (and readermode) outside of mathml, what we should do is generalize the mathvariant attribute and allow it on arbitrary markup. But again, this depends on the answer to #3746 (comment) |
|
Sounds good. The new issue links to this discussion so we're not losing it. |
cc @mrego @emilio @rwlbuis @bfgeek
The proposal is to introduce new values for the text-transform properties in order to map alphanumeric text to equivalent Mathematical Alphanumeric Symbols. For details, see the explainer from the MathML Refresh CG repository.
Tentative tests:
web-platform-tests/wpt#16922
All the tests pass in Igalia's
chromium-mathmlbuild.Draft:
https://mathml-refresh.github.io/mathml-core/#new-text-transform-values
The text was updated successfully, but these errors were encountered: