在使用过采样或欠采样处理类别不均衡的数据后,如何正确的做交叉验证? #1909
Conversation
|
校对认领 @sqrthree |
|
@lsvih 好的呢 🍺 |
|
|
||
| A couple of weeks ago I read [this post about cross-validation done wrong](http://www.alfredo.motta.name/cross-validation-done-wrong/). During cross-validation, we are typically trying to understand how well our model can generalize, and how well it can predict our outcome of interest on unseen samples. The author of the blog post makes some good points, especially about feature selection. It is indeed common malpractice to perform feature selection **before** we go into cross-validation, something that should however be done **during** cross-validation, so that the selected features are only derived from training data, and not from pooled training and validation data. | ||
| 几个星期前我阅读了一篇[交叉验证的技术文档(Cross Validation Done Wrong)](http://www.alfredo.motta.name/cross-validation-done-wrong), 在交叉验证的过程中,我们希望能够了解到我们的模型的泛化性能,以及它是如何预测感兴趣的未知样本。基于这个出发点,作者提出了很多好的观点,尤其是关于特征选择的。我们的确经常在进行交叉验证之前进行特征选择,但是需要注意的是我们在特征选择的时候,不能将验证集的数据加入到特征选择这个环节中去。 |
There was a problem hiding this comment.
以及它是如何预测感兴趣的未知样本
-> 以及它是如何预测我们感兴趣的未知样本的
这样可能通顺一点
|
|
||
| A couple of weeks ago I read [this post about cross-validation done wrong](http://www.alfredo.motta.name/cross-validation-done-wrong/). During cross-validation, we are typically trying to understand how well our model can generalize, and how well it can predict our outcome of interest on unseen samples. The author of the blog post makes some good points, especially about feature selection. It is indeed common malpractice to perform feature selection **before** we go into cross-validation, something that should however be done **during** cross-validation, so that the selected features are only derived from training data, and not from pooled training and validation data. | ||
| 几个星期前我阅读了一篇[交叉验证的技术文档(Cross Validation Done Wrong)](http://www.alfredo.motta.name/cross-validation-done-wrong), 在交叉验证的过程中,我们希望能够了解到我们的模型的泛化性能,以及它是如何预测感兴趣的未知样本。基于这个出发点,作者提出了很多好的观点,尤其是关于特征选择的。我们的确经常在进行交叉验证之前进行特征选择,但是需要注意的是我们在特征选择的时候,不能将验证集的数据加入到特征选择这个环节中去。 |
There was a problem hiding this comment.
作者提出了很多好的观点,尤其是关于特征选择的
-> 作者提出了很多好的观点(尤其是关于特征选择的)
|
|
||
| I recently came across two papers [1, 2] predicting term and preterm deliveries using Electrohysterography (EHG) data. The authors used one single cross-sectional EHG recording (capturing the electrical activity of the uterus) and claimed near perfect accuracy in discriminating between the two classes (**AUC value of 0.99** [2], compared to AUC = 0.52-0.60 without oversampling). | ||
| 我最近无意中发现两篇关于早产预测的文章,他们是使用 Electrohysterography 数据来做预测的。作者只使用了一个单独的 EHG 横截面数据(通过捕获子宫电活动获得)训练出来的模型就声称在预测早产的时候具备很高的精度 ( [2], 对比没有使用过采样时的 AUC = 0.52-0.60,他的模型的**AUC 可以达到 0.99**). |
|
|
||
|  | ||
|
|
||
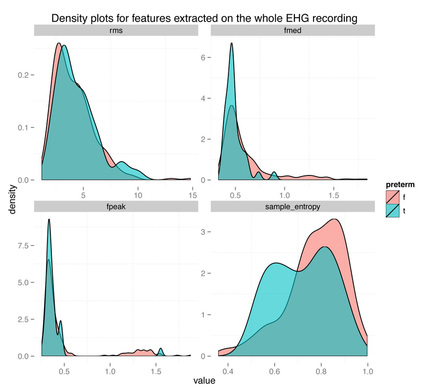
| The density plots above show the feature's distribution for four features over the two classes, term and preterm (f = false, the delivery was not preterm, in light red, t = true, the delivery was preterm, in light blue). As we can see there is really not much discriminative power here between conditions. The extracted features are **completely overlapping between the two classes** and** **we might have a "garbage in, garbage out" issue, more than a "this is not enough data" issue. | ||
| 这四张密度图表示的是他所用到的四个特征的在两个类别上的分布,这两个类别为正常分娩与早产(f = false,表示正常分娩,使用红色的线表示,t = true, 则表示为早产,用蓝色的线表示)。我们从图中可以看到这四个特征并没有很强的区分两个类别的能力。他所提取出来的特征在两个特征上的分布基本上就是重叠的。我们可以认为这是一个无用输入,无用输出的例子,而不是说这个模型缺少数据。 |
There was a problem hiding this comment.
的线表示,t = true, 则表示
-> 的线表示;t = true, 则表示
|
|
||
| Just thinking about the problem domain, should also raise some doubts, when we see results as high as auc = 0.99. The term/preterm distinction is almost arbitrary, set to 37 weeks of pregnancy. **If you deliver at 36 weeks and 6 days, you are labeled preterm. On the other hand, if you deliver at 37 weeks and 1 day, you are labeled term**. Obviously, there is no actual difference due to being term or preterm between two people that deliver that close, it's just a convention, and as such, prediction results will always be affected and most likely very inaccurate around the 37 weeks threshold. | ||
| 只要稍微思考一下该问题所在的区域,我们就会对 auc=0.99 这个结果提出质疑。因为区分正常分娩和早产没有一个很明确的区分。假设我们设置 37 周就为正常的分娩时间。**那么如果你在第36周后的第6天分娩,那么我们则标记为早产。反之,如果在 37 周后 1 天妊娠,我们则标记为在正常的妊娠期内。**很明显,这两种情况下区分早产和正常分娩是没有意义的。因此,对于分娩时间在 37 周左右的样本则会非常不精确。 |
|
|
||
| On Physionet, you can find even the raw data for this study, however to keep things even simpler, for this analysis I will be using another file the authors provided, where data has already been filtered in the relevant frequency for EHG activity, and features have already been extracted. We have four features (root mean square of the EHG signal, median frequency, frequency peak and sample entropy, again [have a look at the paper](http://physionet.mit.edu/pn6/tpehgdb/tpehgdb.pdf) here for more information on how these features are computed). According to the researchers that collected the dataset, the most informative channel is channel 3, probably due to it's position, and therefore I will be using precomputed features extracted from channel 3. The exact data is also on [github](https://github.com/marcoalt/Physionet-EHG-imbalanced-data). As classifiers, I used a bunch of common classifiers, logistic regression, classification trees, SVMs and random forests. I won't do any feature selection, but use all the four features we have. | ||
| 在 Physionet 上,你可以找到所有关于该研究的数据,但是为了让下面的实验不那么复杂,我们用到的是作者提供的另外一份数据来进行分析,这份数据中包含的特征是从原始数据中筛选出来的,筛选的条件是根据特征与 EHG 活动之间的相关频率。我们有四个特征(EHG信号的均方根,中值频率,频率峰值和样本熵,[这里](http://physionet.mit.edu/pn6/tpehgdb/tpehgdb.pdf)有关如何计算这些特征值的更多信息)。根据收集数据集的研究人员,大部分有价值的信息都是来自于渠道 3,因此我将使用从渠道 3 预提取出来的特征。详细的数据集也在 [github](https:// github.com/marcoalt/Physionet-EHG-imbalanced-data)可以找到。因为我们是要训练分类器分类器,所以我使用了一些常见的训练分类器的算法,逻辑回归,分类树,SVM 和随机森林。在博客中我不会做任何特征选择,而是将所有的数据都用来训练模型。 |
|
|
||
| On Physionet, you can find even the raw data for this study, however to keep things even simpler, for this analysis I will be using another file the authors provided, where data has already been filtered in the relevant frequency for EHG activity, and features have already been extracted. We have four features (root mean square of the EHG signal, median frequency, frequency peak and sample entropy, again [have a look at the paper](http://physionet.mit.edu/pn6/tpehgdb/tpehgdb.pdf) here for more information on how these features are computed). According to the researchers that collected the dataset, the most informative channel is channel 3, probably due to it's position, and therefore I will be using precomputed features extracted from channel 3. The exact data is also on [github](https://github.com/marcoalt/Physionet-EHG-imbalanced-data). As classifiers, I used a bunch of common classifiers, logistic regression, classification trees, SVMs and random forests. I won't do any feature selection, but use all the four features we have. | ||
| 在 Physionet 上,你可以找到所有关于该研究的数据,但是为了让下面的实验不那么复杂,我们用到的是作者提供的另外一份数据来进行分析,这份数据中包含的特征是从原始数据中筛选出来的,筛选的条件是根据特征与 EHG 活动之间的相关频率。我们有四个特征(EHG信号的均方根,中值频率,频率峰值和样本熵,[这里](http://physionet.mit.edu/pn6/tpehgdb/tpehgdb.pdf)有关如何计算这些特征值的更多信息)。根据收集数据集的研究人员,大部分有价值的信息都是来自于渠道 3,因此我将使用从渠道 3 预提取出来的特征。详细的数据集也在 [github](https:// github.com/marcoalt/Physionet-EHG-imbalanced-data)可以找到。因为我们是要训练分类器分类器,所以我使用了一些常见的训练分类器的算法,逻辑回归,分类树,SVM 和随机森林。在博客中我不会做任何特征选择,而是将所有的数据都用来训练模型。 |
There was a problem hiding this comment.
所以我使用了一些常见的训练分类器的算法,逻辑回归,分类树,SVM 和随机森林
-> 所以我使用了一些常见的训练分类器的算法:逻辑回归、分类树、SVM 和随机森林
|
|
||
| - Repeat *n* times, where *n* is your number of samples (if doing leave one participant out cross-validation). | ||
| 显然,分析结果并不意味着利用 EHG 数据检测是否早产是不可能的。只能说明一个横截面记录和这些基本特征并不够用来区分早产。这里最可能需要的是多重生理信号的纵向记录(如EHG、ECG、胎儿心电图、hr/hrv等)以及有关活动和行为的信息。多参数纵向数据可以帮助我们更好地理解这些信号在怀孕结果方面的变化,以及对个体差异的建模,类似于我们在其他复杂的应用中所看到的,从生理学的角度来看,这是很不容易理解的。在 [Bloom](http://www.bloom.life/),我们正致力于更好地建模这些变量,以有效地预测早产风险。然而,这一问题的内在局限性,仅仅是因为参考的定义(例如,在37周内几乎是任意的阈值),因此需要小心地分析近乎完美的分类,正如我们在这篇文章中所看到的那样。 |
|
翻译的好好!有两个问题想和您探讨一下: 一个是这个标题虽然符合文意,但是和原标题差的有点远,是否要改改。。比如《使用过采样、欠采样及正确的交叉验证处理类别不均衡数据》 还有一个是文中的 Specificity 应该是“灵敏度”吧? |
| @@ -359,25 +358,28 @@ Specificity** | |||
|
|
|||
| [](/uploads/1/3/2/3/13234002/9325217_orig.jpg?402) | |||
|
|
|||
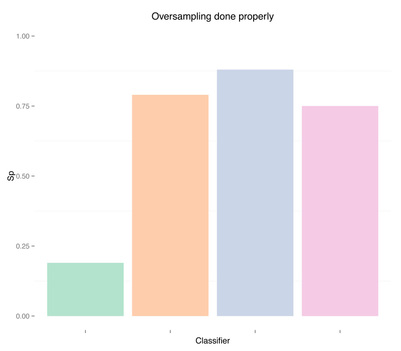
| As we can see oversampling properly (fourth plots) is not much better than undersampling (second plots), for this dataset. | |||
| 正如我们所看到,分别使用合适的过采样(第四张图)和欠采样(第二张图)在这个数据集上训练出来的模型差距并不是很大。 | |||
|
|
|||
| ## summary | |||
|
|
||
| Obviously, this analysis does not mean that detecting term and preterm recordings with EHG data is not possible. It simply means that one single cross-sectional recording and these basic features do not seem to be sufficient. Most likely what is needed here are longitudinal recordings of multiple physiological signals (e.g. EHG, ECG, fetal ECG, HR/HRV, etc.) as well as information about activity and behavior. Multi-parameter longitudinal data can help better understanding variations in such signals with respect to pregnancy outcomes as well as modeling individual differences, similarly to what we see in other complex applications which are poorly understood from a physiological point of view. At [Bloom](http://www.bloom.life/) we're working at better modeling these variables to effectively predict preterm birth risk. However, intrinsic limitations to this problem are present, simply because of how the reference is defined (i.e. an almost arbitrary threshold at 37 weeks), and therefore claims of near-perfect classification should be analyzed with care, as we've seen in this post. | ||
|
|
||
| ## references |
|
@edvardHua 一般我们把 recall 叫做召回率.....看到您这儿全写的是”回召率“比较疑惑。😆 |
|
@lsvih 阿西吧,这个是我写错了。 |
|
校对认领 @sqrthree |
|
@lileizhenshuai 妥妥哒 🍻 |
|
|
||
| However, the article doesn’t touch a problem that is a major issue in most clinical research, i.e. **how to properly cross-validate when we have imbalanced data**. As a matter of fact, in the context of many medical applications, we have datasets where we have two classes for the main outcome; **normal** samples and **relevant** samples. For example in a cancer detection application we might have a small percentages of patients with cancer (relevant samples) while the majority of samples might be healthy individuals. Outside of the medical space, this is true (even more) for the case for example of fraud detection, where the rate of relevant samples (i.e. frauds) to normal samples might be even in the order of 1 to 100 000. | ||
| 但是,这篇文章并没有涉及到我们在实际应用经常出现的问题。譬如说,如何在不均衡的数据上合理的进行交叉验证。在医疗领域,我们所拥有的数据集一般只包含两种类别的数据,**正常**样本和**相关**样本。譬如说在癌症检查的应用我们可能只有很小一部分病人患上了癌症(相关样本)而其余的大部分样本都是健康的个体。就算不在医疗领域,这种情况也存在,譬如欺诈识别,它们的数据集中的相关样本和正常样本的比例都有可能会是 1:100 000 |
There was a problem hiding this comment.
譬如说,如何在不均衡的数据上合理的进行交叉验证 -> 例如,如何在不均衡的数据上合理的进行交叉验证
|
|
||
| However, the article doesn’t touch a problem that is a major issue in most clinical research, i.e. **how to properly cross-validate when we have imbalanced data**. As a matter of fact, in the context of many medical applications, we have datasets where we have two classes for the main outcome; **normal** samples and **relevant** samples. For example in a cancer detection application we might have a small percentages of patients with cancer (relevant samples) while the majority of samples might be healthy individuals. Outside of the medical space, this is true (even more) for the case for example of fraud detection, where the rate of relevant samples (i.e. frauds) to normal samples might be even in the order of 1 to 100 000. | ||
| 但是,这篇文章并没有涉及到我们在实际应用经常出现的问题。譬如说,如何在不均衡的数据上合理的进行交叉验证。在医疗领域,我们所拥有的数据集一般只包含两种类别的数据,**正常**样本和**相关**样本。譬如说在癌症检查的应用我们可能只有很小一部分病人患上了癌症(相关样本)而其余的大部分样本都是健康的个体。就算不在医疗领域,这种情况也存在,譬如欺诈识别,它们的数据集中的相关样本和正常样本的比例都有可能会是 1:100 000 |
|
|
||
| However, the article doesn’t touch a problem that is a major issue in most clinical research, i.e. **how to properly cross-validate when we have imbalanced data**. As a matter of fact, in the context of many medical applications, we have datasets where we have two classes for the main outcome; **normal** samples and **relevant** samples. For example in a cancer detection application we might have a small percentages of patients with cancer (relevant samples) while the majority of samples might be healthy individuals. Outside of the medical space, this is true (even more) for the case for example of fraud detection, where the rate of relevant samples (i.e. frauds) to normal samples might be even in the order of 1 to 100 000. | ||
| 但是,这篇文章并没有涉及到我们在实际应用经常出现的问题。譬如说,如何在不均衡的数据上合理的进行交叉验证。在医疗领域,我们所拥有的数据集一般只包含两种类别的数据,**正常**样本和**相关**样本。譬如说在癌症检查的应用我们可能只有很小一部分病人患上了癌症(相关样本)而其余的大部分样本都是健康的个体。就算不在医疗领域,这种情况也存在,譬如欺诈识别,它们的数据集中的相关样本和正常样本的比例都有可能会是 1:100 000 |
|
|
||
| The main motivation behind the need to preprocess imbalanced data before we feed them into a classifier is that typically classifiers are more sensitive to detecting the majority class and less sensitive to the minority class. Thus, if we don't take care of the issue, the classification output will be biased, in many cases resulting in always predicting the majority class. Many methods have been proposed in the past few years to deal with imbalanced data. This is not really my area of research, however since I [started working on preterm birth prediction](https://medium.com/40-weeks/37-772d7f519f9), I had to deal with the problem more often. Preterm birth refers to pregnancies shorter than 37 weeks, and results in about 6-7% of all deliveries in most European countries, and 11% of all deliveries in the U.S., therefore the data are quite imbalanced. | ||
| 因为分类器对数据中类别占比较大的数据比较敏感,而对占比较小的数据则没那么敏感,所以我们需要在进行交叉验证之前需要预处理不均衡数据。所以如果我们不处理类别不均衡的数据,分类器的输出结果就会存在偏差,也就是在预测过程中大多数情况下都会给出偏向于某个类别,这个类别是训练的时候占比较大的那个类别。这个问题并不是我的研究领域,但是自从我在[做早产预测的工作的时候](https://medium.com/40-weeks/37-772d7f519f9)经常会遇到这种问题。早产是指短于 37 周的妊娠,大部分欧洲国家的早产率约占 6-7%,美国的早产率为 11%,因此我们可以看到相关的样本所占的比例都很小。 |
There was a problem hiding this comment.
所以我们需要在进行交叉验证之前需要预处理不均衡数据 -> 所以我们需要在交叉验证之前对不均衡数据进行预处理
这样可能更顺畅
|
|
||
| The main motivation behind the need to preprocess imbalanced data before we feed them into a classifier is that typically classifiers are more sensitive to detecting the majority class and less sensitive to the minority class. Thus, if we don't take care of the issue, the classification output will be biased, in many cases resulting in always predicting the majority class. Many methods have been proposed in the past few years to deal with imbalanced data. This is not really my area of research, however since I [started working on preterm birth prediction](https://medium.com/40-weeks/37-772d7f519f9), I had to deal with the problem more often. Preterm birth refers to pregnancies shorter than 37 weeks, and results in about 6-7% of all deliveries in most European countries, and 11% of all deliveries in the U.S., therefore the data are quite imbalanced. | ||
| 因为分类器对数据中类别占比较大的数据比较敏感,而对占比较小的数据则没那么敏感,所以我们需要在进行交叉验证之前需要预处理不均衡数据。所以如果我们不处理类别不均衡的数据,分类器的输出结果就会存在偏差,也就是在预测过程中大多数情况下都会给出偏向于某个类别,这个类别是训练的时候占比较大的那个类别。这个问题并不是我的研究领域,但是自从我在[做早产预测的工作的时候](https://medium.com/40-weeks/37-772d7f519f9)经常会遇到这种问题。早产是指短于 37 周的妊娠,大部分欧洲国家的早产率约占 6-7%,美国的早产率为 11%,因此我们可以看到相关的样本所占的比例都很小。 |
There was a problem hiding this comment.
也就是在预测过程中大多数情况下都会给出偏向于某个类别 -> 也就是在预测过程中大多数情况下都会给出偏向于某个类别的结果
|
|
||
| The main motivation behind the need to preprocess imbalanced data before we feed them into a classifier is that typically classifiers are more sensitive to detecting the majority class and less sensitive to the minority class. Thus, if we don't take care of the issue, the classification output will be biased, in many cases resulting in always predicting the majority class. Many methods have been proposed in the past few years to deal with imbalanced data. This is not really my area of research, however since I [started working on preterm birth prediction](https://medium.com/40-weeks/37-772d7f519f9), I had to deal with the problem more often. Preterm birth refers to pregnancies shorter than 37 weeks, and results in about 6-7% of all deliveries in most European countries, and 11% of all deliveries in the U.S., therefore the data are quite imbalanced. | ||
| 因为分类器对数据中类别占比较大的数据比较敏感,而对占比较小的数据则没那么敏感,所以我们需要在进行交叉验证之前需要预处理不均衡数据。所以如果我们不处理类别不均衡的数据,分类器的输出结果就会存在偏差,也就是在预测过程中大多数情况下都会给出偏向于某个类别,这个类别是训练的时候占比较大的那个类别。这个问题并不是我的研究领域,但是自从我在[做早产预测的工作的时候](https://medium.com/40-weeks/37-772d7f519f9)经常会遇到这种问题。早产是指短于 37 周的妊娠,大部分欧洲国家的早产率约占 6-7%,美国的早产率为 11%,因此我们可以看到相关的样本所占的比例都很小。 |
There was a problem hiding this comment.
因此我们可以看到相关的样本所占的比例都很小 -> 因此我们可以看到数据是非常不均衡的
|
|
||
| I recently came across two papers [1, 2] predicting term and preterm deliveries using Electrohysterography (EHG) data. The authors used one single cross-sectional EHG recording (capturing the electrical activity of the uterus) and claimed near perfect accuracy in discriminating between the two classes (**AUC value of 0.99** [2], compared to AUC = 0.52-0.60 without oversampling). | ||
| 我最近无意中发现两篇关于早产预测的文章,他们是使用 Electrohysterography 数据来做预测的。作者只使用了一个单独的 EHG 横截面数据(通过捕获子宫电活动获得)训练出来的模型就声称在预测早产的时候具备很高的精度 ( [2], 对比没有使用过采样时的 AUC = 0.52-0.60,他的模型的**AUC 可以达到 0.99**). |
There was a problem hiding this comment.
他们是使用 Electrohysterography 数据来做预测的 -> 他们是使用 Electrohysterography (EHG)数据来做预测的
|
|
||
| Just thinking about the problem domain, should also raise some doubts, when we see results as high as auc = 0.99. The term/preterm distinction is almost arbitrary, set to 37 weeks of pregnancy. **If you deliver at 36 weeks and 6 days, you are labeled preterm. On the other hand, if you deliver at 37 weeks and 1 day, you are labeled term**. Obviously, there is no actual difference due to being term or preterm between two people that deliver that close, it's just a convention, and as such, prediction results will always be affected and most likely very inaccurate around the 37 weeks threshold. | ||
| 只要稍微思考一下该问题所在的区域,我们就会对 auc=0.99 这个结果提出质疑。因为区分正常分娩和早产没有一个很明确的区分。假设我们设置 37 周就为正常的分娩时间。**那么如果你在第36周后的第6天分娩,那么我们则标记为早产。反之,如果在 37 周后 1 天妊娠,我们则标记为在正常的妊娠期内。**很明显,这两种情况下区分早产和正常分娩是没有意义的。因此,对于分娩时间在 37 周左右的样本则会非常不精确。 |
There was a problem hiding this comment.
这两种情况下区分早产和正常分娩是没有意义的。因此,对于分娩时间在 37 周左右的样本则会非常不精确。
-> 这两种情况下区分早产和正常分娩是没有意义的,37 周只是一个惯例。因此,预测结果会大受影响并且对于分娩时间在 37 周左右的样本,结果会非常不精确。
|
|
||
| A few notes on what I will be using. The dataset was collected in Slovenia at the University Medical Centre Ljubljana, Department of Obstetrics and Gynecology, between 1997 and 2005. It consists of cross-sectional EHG data for non-at-risk singleton pregnancies. **The dataset is imbalanced with 38 out of 300 recordings that are preterm**. More information about the dataset can be found in [3]. To keep things simple, the main rationale behind this data is that EHG measures the electrical activity of the uterus, that clearly changes during pregnancy, until it results in contractions, labour and delivery. Therefore, the researchers speculated that by monitoring the activity of the uterus non-invasively early on, it could be possible to determine which pregnancies will result in preterm deliveries. | ||
| 我们使用的数据来自于卢布尔雅那医学中心大学妇产科,数据中涵盖了从1997 年到 2005 年斯洛维尼亚地区的妊娠记录。他包含了从正常怀孕的 EHG 截面数据。**这个数据是非常不均衡的,因为 300 个记录中只有 38 条才是早孕**。更加详细的信息可以在 [3] 中找到。简单来说,我们选择 EHG 截面的理由是因为 EHG 测量的是子宫的电活动图,而这个活动图在怀孕期间会不断的变化,直到子宫导致收缩分娩出孩子。因此,研究推断非侵入性情况下监测怀孕活动可以尽早的发现哪些孕妇会早产。 |
|
|
||
| On Physionet, you can find even the raw data for this study, however to keep things even simpler, for this analysis I will be using another file the authors provided, where data has already been filtered in the relevant frequency for EHG activity, and features have already been extracted. We have four features (root mean square of the EHG signal, median frequency, frequency peak and sample entropy, again [have a look at the paper](http://physionet.mit.edu/pn6/tpehgdb/tpehgdb.pdf) here for more information on how these features are computed). According to the researchers that collected the dataset, the most informative channel is channel 3, probably due to it's position, and therefore I will be using precomputed features extracted from channel 3. The exact data is also on [github](https://github.com/marcoalt/Physionet-EHG-imbalanced-data). As classifiers, I used a bunch of common classifiers, logistic regression, classification trees, SVMs and random forests. I won't do any feature selection, but use all the four features we have. | ||
| 在 Physionet 上,你可以找到所有关于该研究的数据,但是为了让下面的实验不那么复杂,我们用到的是作者提供的另外一份数据来进行分析,这份数据中包含的特征是从原始数据中筛选出来的,筛选的条件是根据特征与 EHG 活动之间的相关频率。我们有四个特征(EHG信号的均方根,中值频率,频率峰值和样本熵,[这里](http://physionet.mit.edu/pn6/tpehgdb/tpehgdb.pdf)有关如何计算这些特征值的更多信息)。根据收集数据集的研究人员,大部分有价值的信息都是来自于渠道 3,因此我将使用从渠道 3 预提取出来的特征。详细的数据集也在 [github](https:// github.com/marcoalt/Physionet-EHG-imbalanced-data)可以找到。因为我们是要训练分类器分类器,所以我使用了一些常见的训练分类器的算法,逻辑回归,分类树,SVM 和随机森林。在博客中我不会做任何特征选择,而是将所有的数据都用来训练模型。 |
There was a problem hiding this comment.
你可以找到所有关于该研究的数据 -> 你可以找到所有关于该研究的原始数据
|
|
||
| On Physionet, you can find even the raw data for this study, however to keep things even simpler, for this analysis I will be using another file the authors provided, where data has already been filtered in the relevant frequency for EHG activity, and features have already been extracted. We have four features (root mean square of the EHG signal, median frequency, frequency peak and sample entropy, again [have a look at the paper](http://physionet.mit.edu/pn6/tpehgdb/tpehgdb.pdf) here for more information on how these features are computed). According to the researchers that collected the dataset, the most informative channel is channel 3, probably due to it's position, and therefore I will be using precomputed features extracted from channel 3. The exact data is also on [github](https://github.com/marcoalt/Physionet-EHG-imbalanced-data). As classifiers, I used a bunch of common classifiers, logistic regression, classification trees, SVMs and random forests. I won't do any feature selection, but use all the four features we have. | ||
| 在 Physionet 上,你可以找到所有关于该研究的数据,但是为了让下面的实验不那么复杂,我们用到的是作者提供的另外一份数据来进行分析,这份数据中包含的特征是从原始数据中筛选出来的,筛选的条件是根据特征与 EHG 活动之间的相关频率。我们有四个特征(EHG信号的均方根,中值频率,频率峰值和样本熵,[这里](http://physionet.mit.edu/pn6/tpehgdb/tpehgdb.pdf)有关如何计算这些特征值的更多信息)。根据收集数据集的研究人员,大部分有价值的信息都是来自于渠道 3,因此我将使用从渠道 3 预提取出来的特征。详细的数据集也在 [github](https:// github.com/marcoalt/Physionet-EHG-imbalanced-data)可以找到。因为我们是要训练分类器分类器,所以我使用了一些常见的训练分类器的算法,逻辑回归,分类树,SVM 和随机森林。在博客中我不会做任何特征选择,而是将所有的数据都用来训练模型。 |
|
|
||
| ## imbalanced data | ||
| 我决定使用**留一法**来做交叉验证。这种技术在使用数据集时或者当欠采样时不会有任何错误的余地。但是,当过采样时,情况又会有点不一样,所以让我看下面的分析。 |
|
|
||
| ## ignoring the problem | ||
| 如果我们使用不均衡的数据来训练分类器,那么训练出来的分类器在预测数据的时候只要给出数据集中占比最大的数据所对应的类别即可。这样的分类器具备太大的偏差,下面是训练这样的分类器所对应的代码: |
There was a problem hiding this comment.
那么训练出来的分类器在预测数据的时候只要给出数据集中占比最大的数据所对应的类别即可 -> 那么训练出来的分类器在预测数据的时候总会返回数据集中占比最大的数据所对应的类别作为结果
|
|
||
|  | ||
|
|
||
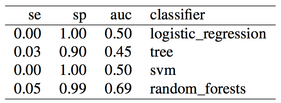
| As expected the classifier is biased, and sensitivity is zero or very close to zero, while specificity is one or very close to one, i.e. all or almost all recordings are detected as term, and therefore no or almost no preterm recordings are correctly identified. Let's move on to the next case, undersampling the majority class. | ||
| 如预期的那样,分类器的偏差太大,回召率为零或非常接近零,而真假例为1或非常接近于1,即所有或几乎所有记录被检测为会正常分娩,因此基本没有识别出早产的记录。下面的实验则使用了欠采样的方法。 |
|
|
||
|  | ||
|
|
||
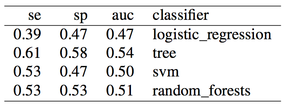
| By undersampling, we solved the class imbalance issue, and increased the sensitivity of our models. However, results are very poor. A reason could indeed be that we trained our classifiers using few samples. In general, the more imbalanced the dataset the more samples will be discarded when undersampling, therefore throwing away potentially useful information. The question we should ask ourselves now is, are we developing a poor classifier because we don’t have much data? Or are we simply relying on bad features with poor discriminative power, and therefore more data of the same type won’t necessary help? | ||
| 通过欠采样,我们解决了数据类别不均衡的问题,并且提高了模型的回召率,但是,模型的表现并不是很好。其中一个原因可能是因为我们用来训练模型的数据过少。一般来说,如果我们的数据集中的类别越不均衡,那么我们在欠采样中抛弃的数据就会越多,那么就意味着我们可能抛弃了一些潜在的并且有用的信息。现在我们应该这样问我们自己,我们是否训练了一个弱的分类器,而原因是因为我们没有太多的数据?还是说我们依赖了不好的特征,所以就算数据再多对模型帮助也没有好处? |
There was a problem hiding this comment.
所以就算数据再多对模型帮助也没有好处? -> 所以就算数据再多对模型也没有帮助?
|
|
||
| 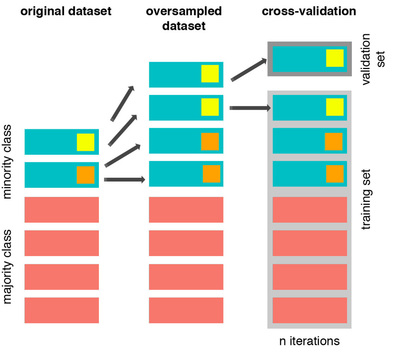 | ||
|
|
||
| From left to right, we start with the original dataset where we have a minority class with two samples. We duplicate those samples, and then we do cross-validation. At this point there will be iterations, such as the one showed, where **the training and validation set contain the same sample**, resulting in overfitting and misleading results. Here is how this should be done: | ||
| 最左边那列表示的是原始的数据,里面包含了少数类下的两个样本。我们拷贝这两个样本作为副本,然后再进行交叉验证。在迭代的过程,我们的训练样本和验证样本会包含相同的数据,如最右那张图所示,这种情况下会导致过拟合或舞蹈的结果,合适的做法应该如下图所示。 |
|
|
||
| This was a simple example, and better methods can be used to oversample. One of the most common being the **SMOTE** technique, i.e. a method that instead of simply duplicating entries creates entries that are **interpolations of the minority class**, as well as undersamples the majority class. Normally when we duplicate data points the classifiers get very convinced about a specific data point with small boundaries around it, as the only point where the minority class is valid, instead of generalizing from it. However, SMOTE effectively forces the decision region of the minority class to become more general,partially solving the generalization problem. There are some pretty neat visualizations in the original paper, so I would advice to have a look [here](https://www.jair.org/media/953/live-953-2037-jair.pdf). | ||
| 这是一个简单的例子,当然我们也可以使用更加好的方法来做过采样。其中一种使用的过采样方法叫做**SMOTE**方法,SMOTE 方法并不是采取简单复制样本的策略来增加少数类样本,**而是通过分析少数类样本来创建新的样本**的同事对多数类样本进行欠采样。正常来说当我们简单复制样本的时候,训练出来的分类器在预测这些复制样本时会很有信心的将他们识别出来,你为他知道这些复制样本的所有边界和特点,而不是以概括的角度来刻画这些少数类样本。但是,SMOTE 可以有效的强制让分类的边界更加的泛化,一定程度上解决了不够泛化而导致的过拟合问题。在 SMOTE 的[论文](https://www.jair.org/media/953/live-953-2037-jair.pdf)中用了很多图来进行解释这个问题的原理和解决方案,所以我建议大家可以去看看。 |
|
|
||
| 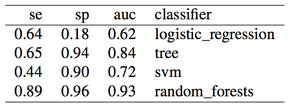 | ||
|
|
||
| Results are pretty good now. Especially for random forests, we obtained **auc = 0.93** without any feature engineering, simply using what was provided in the dataset, and without any parameter tuning for the classifier. Once again, apart from the differences in the two oversampling methods (replication of the minority class or SMOTE), the issue here is not even **which** method to use, but **when** to use it. Using oversampling before cross-validation we have now obtained almost perfect accuracy, i.e. **we overfitted** (even a simple classification tree gets auc = 0.84). | ||
| 结果相当不错。尤其是随机森林在没有做任何特征工程和调参的前提下 **auc 的值达到了 0.93**,但是与前面不同的是我们使用了 SMOTE 方法进行欠采样,现在这个问题的核心在于我们应该在什么时候使用恰当的方法,而不是使用什么方法。在交叉验证之前使用过采样的确获得很高的精度,但模型已经**过拟合**了。你看,就算是最简单的分类树都可以获得 0.84 的 AUC 值。 |
|
|
||
| ``` | ||
| 正确的在交叉验证中配合使用过拟合的方法很简单。就和我们在交叉验证中的每次循环中做特征选择一样,我们也要在每次循环中做过采样。**根据我们当前的少数类创建样本,然后选择一个样本作为验证,假装我们没有使用在训练集中的数据来作为验证样本,这是毫无意义的。**。这一次,我们在交叉验证循环中过采样,因为验证集已经从训练样本中移除了,因为我们只需要插入那些不用于验证的样本来合成数据,我们交叉验证的迭代次数将和样本数一样,如下代码所示: |
|
|
||
| To summarize, when cross-validating with oversampling, do the following to make sure your results are generalizable: | ||
| - 过采样少数类的样本,但不要选择已经排除掉的那些样本来过采样。 |
There was a problem hiding this comment.
过采样少数类的样本,但不要选择已经排除掉的那些样本来过采样。 -> 过采样少数类的样本,但不要选择已经排除掉的那些样本。
|
|
||
| - Inside the cross-validation loop, get a sample out and do not use it for anything related to features selection, oversampling or model building. | ||
| - 对少数类过采样和大多数类的样本混合在一起来训练模型,然后用已经排除掉的样本做为验证集 |
There was a problem hiding this comment.
用对少数类过采样和大多数类的样本混合在一起的数据集来训练模型,然后用已经排除掉的样本做为验证集
|
|
||
| - Repeat *n* times, where *n* is your number of samples (if doing leave one participant out cross-validation). | ||
| 显然,分析结果并不意味着利用 EHG 数据检测是否早产是不可能的。只能说明一个横截面记录和这些基本特征并不够用来区分早产。这里最可能需要的是多重生理信号的纵向记录(如EHG、ECG、胎儿心电图、hr/hrv等)以及有关活动和行为的信息。多参数纵向数据可以帮助我们更好地理解这些信号在怀孕结果方面的变化,以及对个体差异的建模,类似于我们在其他复杂的应用中所看到的,从生理学的角度来看,这是很不容易理解的。在 [Bloom](http://www.bloom.life/),我们正致力于更好地建模这些变量,以有效地预测早产风险。然而,这一问题的内在局限性,仅仅是因为参考的定义(例如,在37周内几乎是任意的阈值),因此需要小心地分析近乎完美的分类,正如我们在这篇文章中所看到的那样。 |
There was a problem hiding this comment.
仅仅是因为参考的定义(例如,在37周内几乎是任意的阈值)
-> 仅仅关乎参考值是如何定义的(例如,37周这个阈值是非常武断的)
|
校对完成 @sqrthree @edvardHua |
|
|
||
| *[For this analysis I used the term/preterm dataset that you can find on [Physionet](http://www.physionet.org/pn6/tpehgdb/). My data and code are also available on [github](https://github.com/marcoalt/Physionet-EHG-imbalanced-data)]* | ||
| *[关于我在这篇文章中使用的术语可以在 [Physionet](http://www.physionet.org/pn6/tpehgdb/) 网站中找到。 本篇博客中用到的代码可以在 [github](https://github.com/marcoalt/Physionet-EHG-imbalanced-data)中找到]* |
|
|
||
| However, the article doesn’t touch a problem that is a major issue in most clinical research, i.e. **how to properly cross-validate when we have imbalanced data**. As a matter of fact, in the context of many medical applications, we have datasets where we have two classes for the main outcome; **normal** samples and **relevant** samples. For example in a cancer detection application we might have a small percentages of patients with cancer (relevant samples) while the majority of samples might be healthy individuals. Outside of the medical space, this is true (even more) for the case for example of fraud detection, where the rate of relevant samples (i.e. frauds) to normal samples might be even in the order of 1 to 100 000. | ||
| 但是,这篇文章并没有涉及到我们在实际应用经常出现的问题。例如,如何在不均衡的数据上合理的进行交叉验证。在医疗领域,我们所拥有的数据集一般只包含两种类别的数据,**正常**样本和**相关**样本。譬如说在癌症检查的应用我们可能只有很小一部分病人患上了癌症(相关样本)而其余的大部分样本都是健康的个体。就算不在医疗领域,这种情况也存在(甚至更多),比如欺诈识别,它们的数据集中的相关样本和正常样本的比例都有可能会是 1:100 000 |
There was a problem hiding this comment.
『1:100 000』=>『1:100000 』还是符合中文的数字表达方式吧。另外还有句末的句号。
|
|
||
| Just thinking about the problem domain, should also raise some doubts, when we see results as high as auc = 0.99. The term/preterm distinction is almost arbitrary, set to 37 weeks of pregnancy. **If you deliver at 36 weeks and 6 days, you are labeled preterm. On the other hand, if you deliver at 37 weeks and 1 day, you are labeled term**. Obviously, there is no actual difference due to being term or preterm between two people that deliver that close, it's just a convention, and as such, prediction results will always be affected and most likely very inaccurate around the 37 weeks threshold. | ||
| 只要稍微思考一下该问题所在的领域,我们就会对 auc=0.99 这个结果提出质疑。因为区分正常分娩和早产没有一个很明确的区分。假设我们设置 37 周就为正常的分娩时间。**那么如果你在第36周后的第6天分娩,那么我们则标记为早产。反之,如果在 37 周后 1 天妊娠,我们则标记为在正常的妊娠期内。**很明显,这两种情况下区分早产和正常分娩是没有意义的,37 周只是一个惯例,因此,预测结果会大受影响并且对于分娩时间在 37 周左右的样本,结果会非常不精确。 |

|
|
||
| **Cross-validation technique** | ||
| I decided to cross-validate using **leave one participant out cross-validation**. This technique leaves no room for mistakes when using the dataset as it is or when undersampling. However, when oversampling, things are very different. So let's move on to the analysis. | ||
| **交叉验证**** |
|
|
||
| The easiest way to oversample is to re-sample the minority class, i.e. to duplicate the entries, or manufacture data which is exactly the same as what we have already. Now, if we do so before cross-validating, i.e. before we enter the leave one participant out cross-validation loop, we will be training the classifier using N-1 entries, leaving 1 out, **but including in the N-1 one or more instances that are exactly the same as the one being validated**. **Thus, defeating the purpose of cross-validation altogether**. Let's have a look at this issue graphically: | ||
| 最简单的过采样方式就是对占比类别较小下的样本进行重新采样,譬如说创建这些样本的副本,或者手动制造一些相同的数据。现在,如果我们在交叉验证之前做了过采样,然后使用留一法做交叉验证,也就是说我们在每次迭代中使用 N-1 份样本做训练,而只使用 1 份样本验证。**但是我们注意到在其实在 N-1 份的样本中是包含了那一份用来做验证的样本的。所以这样做交叉验证完全违背了初衷。**让我们用图形化的方式来更好的审视这个问题。 |

|
|
||
| ``` | ||
| 正确的在交叉验证中配合使用过拟合的方法很简单。就和我们在交叉验证中的每次循环中做特征选择一样,我们也要在每次循环中做过采样。**根据我们当前的少数类创建样本,然后选择一个样本作为验证样本,假装我们没有使用在训练集中的数据来作为验证样本,这是毫无意义的。**。这一次,我们在交叉验证循环中过采样,因为验证集已经从训练样本中移除了,因为我们只需要插入那些不用于验证的样本来合成数据,我们交叉验证的迭代次数将和样本数一样,如下代码所示: |
|
已经 merge 啦~ 快快麻溜发布到掘金专栏然后给我发下链接,方便及时添加积分哟。 |
@sqrthree 完成「在使用过采样或欠采样处理类别不均衡的数据后,如何正确的做交叉验证?」的翻译。