A curated list of recent diffusion models for video generation, editing, restoration, understanding, nerf, etc.


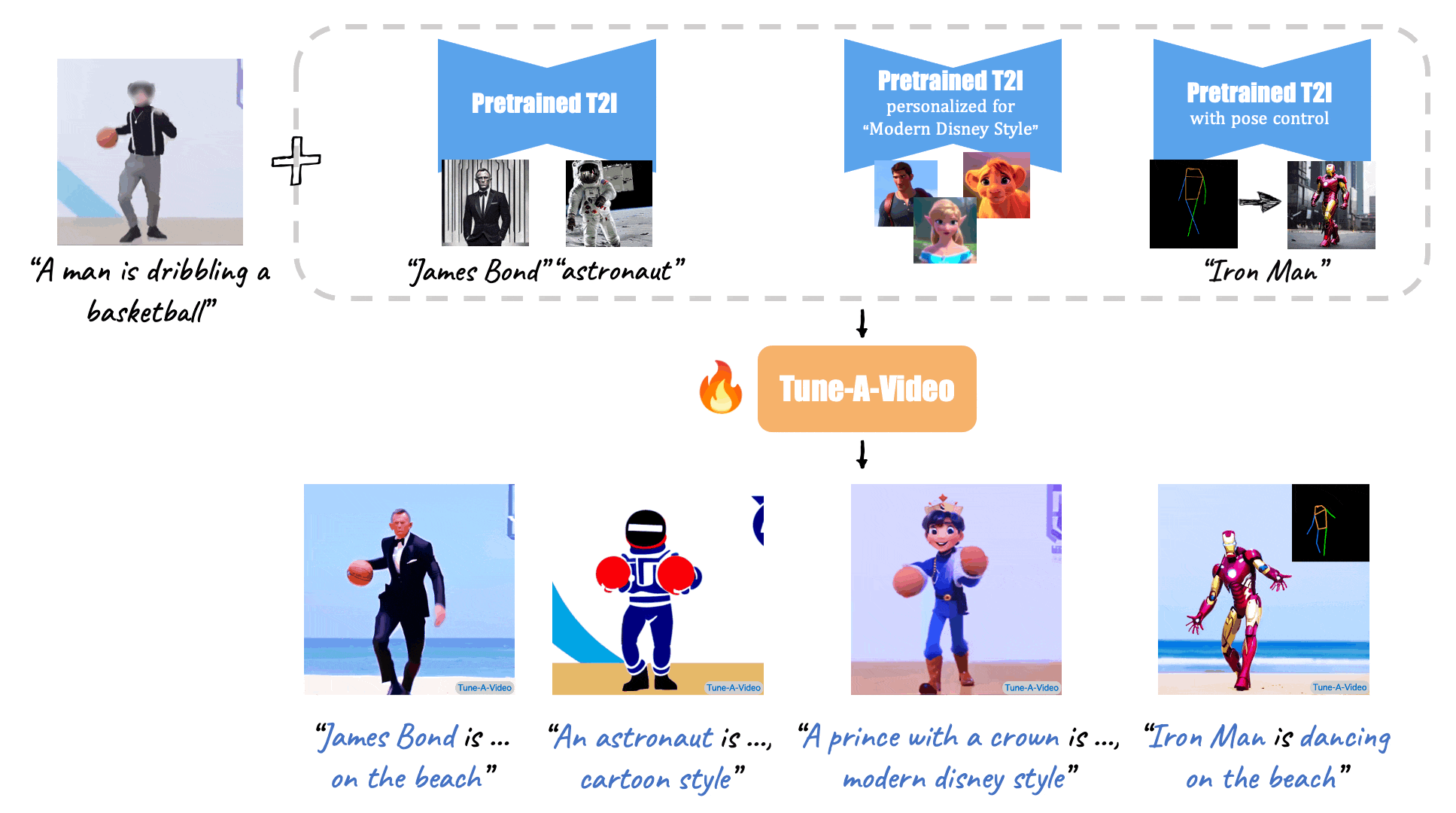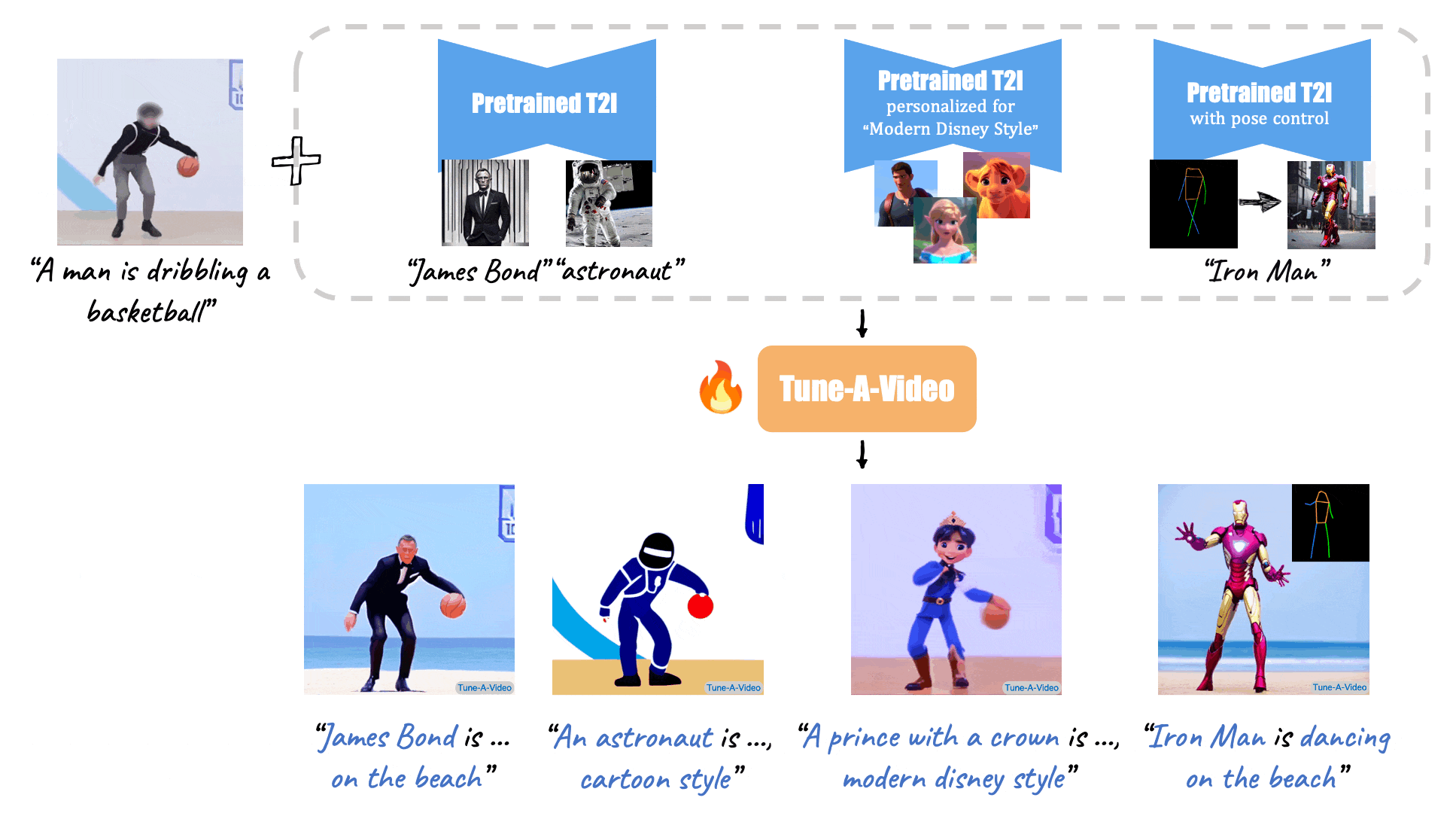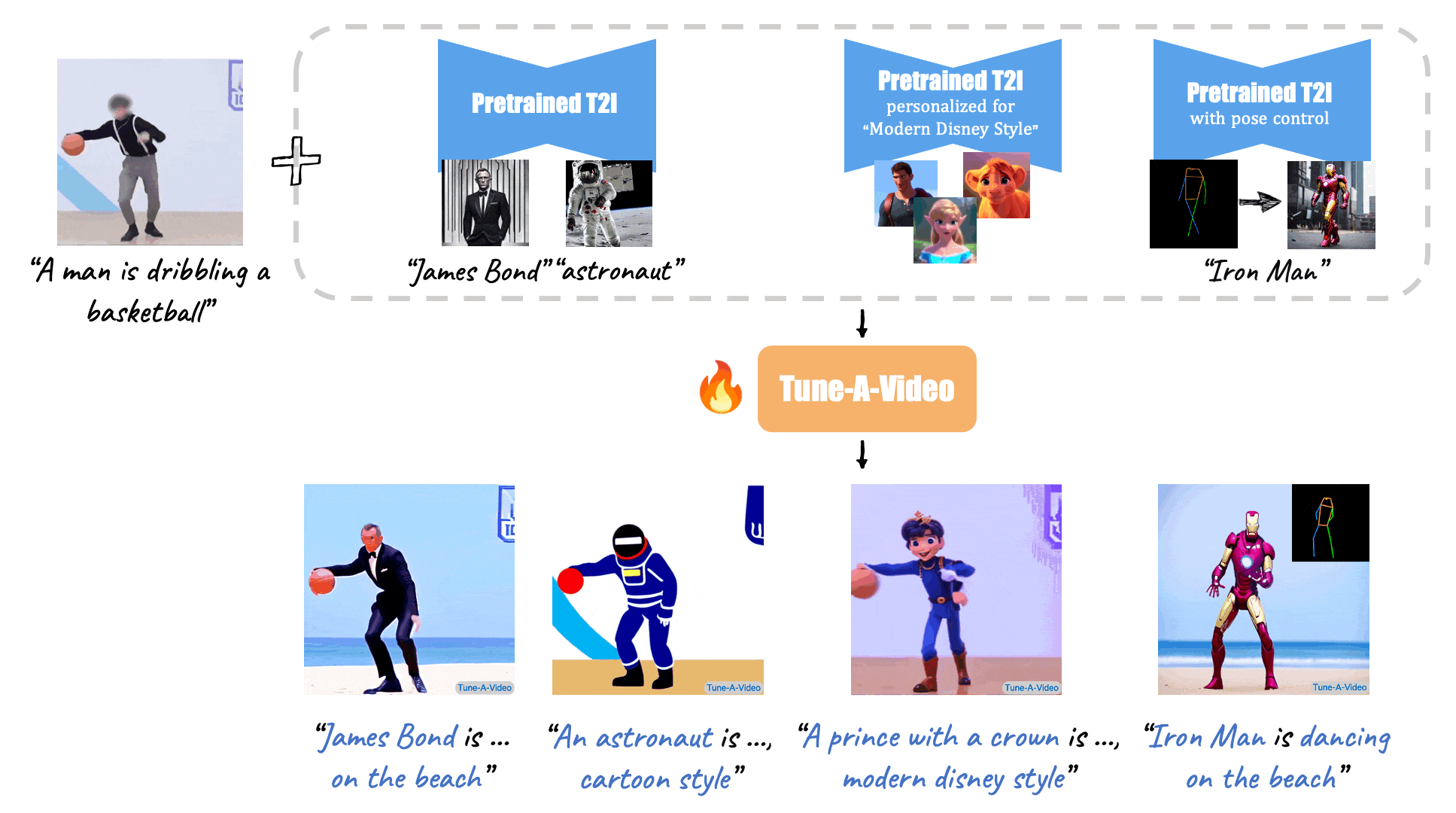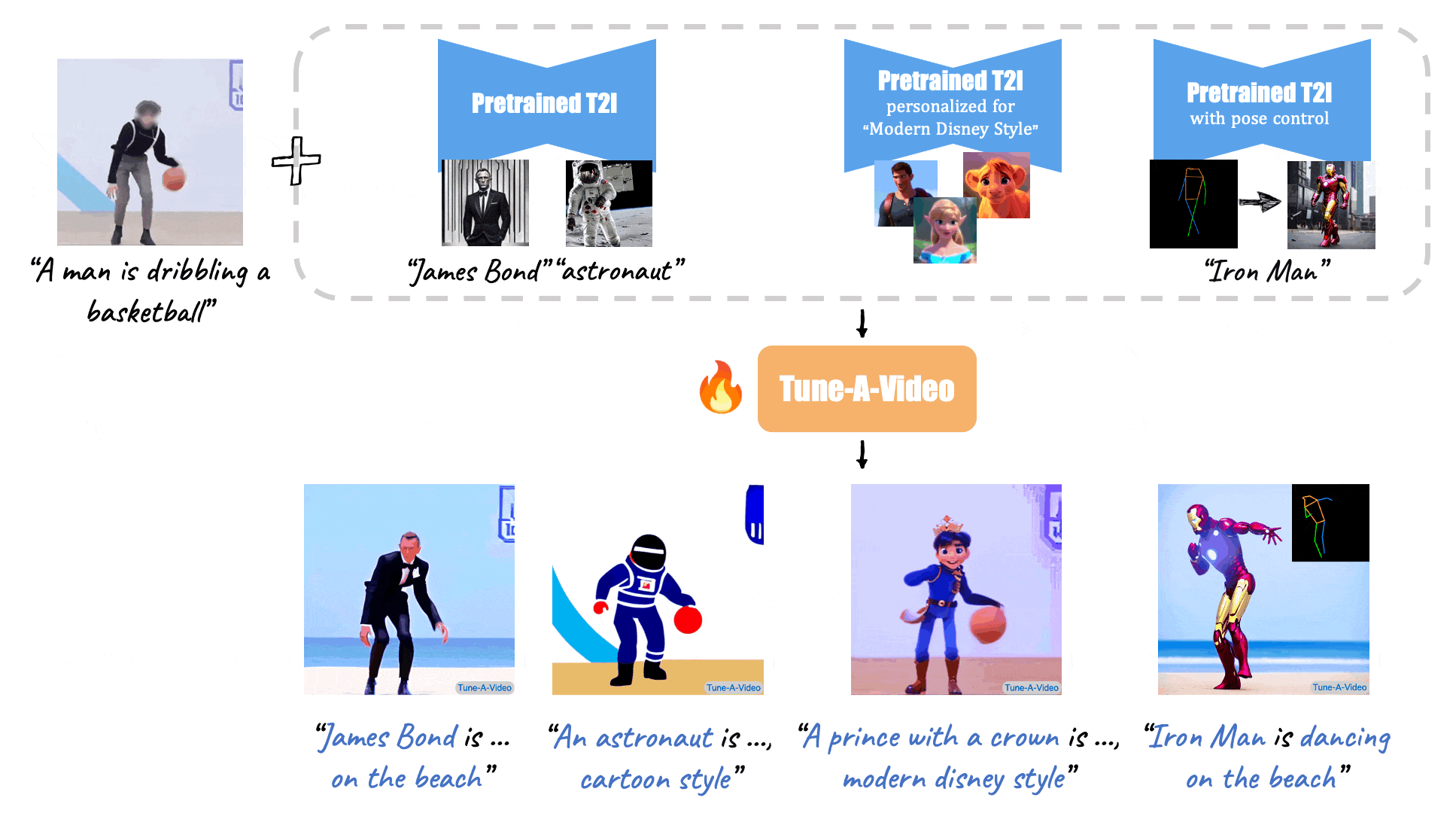


(Source: Make-A-Video, Tune-A-Video, and Fate/Zero.)
- Open-source Toolboxes and Foundation Models
- Evaluation Benchmarks and Metrics
- Video Generation
- Controllable Video Generation
- Video Editing
- Long-form Video Generation and Completion
- Human or Subject Motion
- Video Enhancement and Restoration
- 3D / NeRF
- World Model
- Video Understanding
- Healthcare and Biology









-
ChronoMagic-Bench: A Benchmark for Metamorphic Evaluation of Text-to-Time-lapse Video Generation (Jun., 2024)
-
PEEKABOO: Interactive Video Generation via Masked-Diffusion (CVPR, 2024)
-
T2VScore: Towards A Better Metric for Text-to-Video Generation (Jan., 2024)
-
VBench: Comprehensive Benchmark Suite for Video Generative Models (Nov., 2023)
-
FETV: A Benchmark for Fine-Grained Evaluation of Open-Domain Text-to-Video Generation (Nov., 2023)
-
EvalCrafter: Benchmarking and Evaluating Large Video Generation Models (Oct., 2023)
-
VidProM: A Million-scale Real Prompt-Gallery Dataset for Text-to-Video Diffusion Models (May., 2024)







-
Identifying and Solving Conditional Image Leakage in Image-to-Video Diffusion Model (Jun., 2024)
-
Video-Infinity: Distributed Long Video Generation (Jun., 2024)
-
MotionBooth: Motion-Aware Customized Text-to-Video Generation (Jun., 2024)
-
Text-Animator: Controllable Visual Text Video Generation (Jun., 2024)
-
UniAnimate: Taming Unified Video Diffusion Models for Consistent Human Image Animation (Jun., 2024)
-
T2V-Turbo: Breaking the Quality Bottleneck of Video Consistency Model with Mixed Reward Feedback (May, 2024)
-
Collaborative Video Diffusion: Consistent Multi-video Generation with Camera Control (May, 2024)
-
Human4DiT: Free-view Human Video Generation with 4D Diffusion Transformer (May, 2024)
-
FIFO-Diffusion: Generating Infinite Videos from Text without Training (May, 2024)
-
Vidu: a Highly Consistent, Dynamic and Skilled Text-to-Video Generator with Diffusion Models (May, 2024)
-
StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation (May, 2024)
-
TI2V-Zero: Zero-Shot Image Conditioning for Text-to-Video Diffusion Models (CVPR 2024)
-
ID-Animator: Zero-Shot Identity-Preserving Human Video Generation (Apr., 2024)
-
AnimateZoo: Zero-shot Video Generation of Cross-Species Animation via Subject Alignment (Apr., 2024)
-
MagicTime: Time-lapse Video Generation Models as Metamorphic Simulators (Apr., 2024)
-
TRIP: Temporal Residual Learning with Image Noise Prior for Image-to-Video Diffusion Models (CVPR 2024)
-
StreamingT2V: Consistent, Dynamic, and Extendable Long Video Generation from Text (Mar., 2024)
-
Intention-driven Ego-to-Exo Video Generation (Mar., 2024)
-
VideoElevator: Elevating Video Generation Quality with Versatile Text-to-Image Diffusion Models (Mar., 2024)
-
Snap Video: Scaled Spatiotemporal Transformers for Text-to-Video Synthesis (Feb., 2024)
-
One-Shot Motion Customization of Text-to-Video Diffusion Models (Feb., 2024)
-
Magic-Me: Identity-Specific Video Customized Diffusion (Feb., 2024)
-
ConsistI2V: Enhancing Visual Consistency for Image-to-Video Generation (Feb., 2024)
-
Direct-a-Video: Customized Video Generation with User-Directed Camera Movement and Object Motion (Feb., 2024)
-
Video-LaVIT: Unified Video-Language Pre-training with Decoupled Visual-Motional Tokenization (Feb., 2024)
-
Boximator: Generating Rich and Controllable Motions for Video Synthesis (Feb., 2024)
-
Lumiere: A Space-Time Diffusion Model for Video Generation (Jan., 2024)
-
ActAnywhere: Subject-Aware Video Background Generation (Jan., 2024)
-
WorldDreamer: Towards General World Models for Video Generation via Predicting Masked Tokens (Jan., 2024)
-
CustomVideo: Customizing Text-to-Video Generation with Multiple Subjects (Jan., 2024)
-
UniVG: Towards UNIfied-modal Video Generation (Jan., 2024)
-
VideoCrafter2: Overcoming Data Limitations for High-Quality Video Diffusion Models (Jan., 2024)
-
360DVD: Controllable Panorama Video Generation with 360-Degree Video Diffusion Model (Jan., 2024)
-
RAVEN: Rethinking Adversarial Video Generation with Efficient Tri-plane Networks (Jan., 2024)
-
Latte: Latent Diffusion Transformer for Video Generation (Jan., 2024)
-
MagicVideo-V2: Multi-Stage High-Aesthetic Video Generation (Jan., 2024)
-
VideoDrafter: Content-Consistent Multi-Scene Video Generation with LLM (Jan., 2024)
-
FlashVideo: A Framework for Swift Inference in Text-to-Video Generation (Dec., 2023)
-
I2V-Adapter: A General Image-to-Video Adapter for Video Diffusion Models (Dec., 2023)
-
A Recipe for Scaling up Text-to-Video Generation with Text-free Videos (Dec., 2023)
-
PIA: Your Personalized Image Animator via Plug-and-Play Modules in Text-to-Image Models (Dec., 2023)
-
VideoPoet: A Large Language Model for Zero-Shot Video Generation (Dec., 2023)
-
InstructVideo: Instructing Video Diffusion Models with Human Feedback (Dec., 2023)
-
VideoLCM: Video Latent Consistency Model (Dec., 2023)
-
PEEKABOO: Interactive Video Generation via Masked-Diffusion (Dec., 2023)
-
FreeInit: Bridging Initialization Gap in Video Diffusion Models (Dec., 2023)
-
Photorealistic Video Generation with Diffusion Models (Dec., 2023)
-
Upscale-A-Video: Temporal-Consistent Diffusion Model for Real-World Video Super-Resolution (Dec., 2023)
-
DreaMoving: A Human Video Generation Framework based on Diffusion Models (Dec., 2023)
-
MotionCrafter: One-Shot Motion Customization of Diffusion Models (Dec., 2023)
-
AnimateZero: Video Diffusion Models are Zero-Shot Image Animators (Dec., 2023)
-
AVID: Any-Length Video Inpainting with Diffusion Model (Dec., 2023)
-
MTVG : Multi-text Video Generation with Text-to-Video Models (Dec., 2023)
-
DreamVideo: Composing Your Dream Videos with Customized Subject and Motion (Dec., 2023)
-
Hierarchical Spatio-temporal Decoupling for Text-to-Video Generation (Dec., 2023)
-
GenTron: Delving Deep into Diffusion Transformers for Image and Video Generation (CVPR 2024)
-
GenDeF: Learning Generative Deformation Field for Video Generation (Dec., 2023)
-
F3-Pruning: A Training-Free and Generalized Pruning Strategy towards Faster and Finer Text-to-Video Synthesis (Dec., 2023)
-
DreamVideo: High-Fidelity Image-to-Video Generation with Image Retention and Text Guidance (Dec., 2023)
-
LivePhoto: Real Image Animation with Text-guided Motion Control (Dec., 2023)
-
Fine-grained Controllable Video Generation via Object Appearance and Context (Dec., 2023)
-
VideoBooth: Diffusion-based Video Generation with Image Prompts (Dec., 2023)
-
StyleCrafter: Enhancing Stylized Text-to-Video Generation with Style Adapter (Dec., 2023)
-
MicroCinema: A Divide-and-Conquer Approach for Text-to-Video Generation (Nov., 2023)
-
ART•V: Auto-Regressive Text-to-Video Generation with Diffusion Models (Nov., 2023)
-
Smooth Video Synthesis with Noise Constraints on Diffusion Models for One-shot Video Tuning (Nov., 2023)
-
VideoAssembler: Identity-Consistent Video Generation with Reference Entities using Diffusion Model (Nov., 2023)
-
MotionZero:Exploiting Motion Priors for Zero-shot Text-to-Video Generation (Nov., 2023)
-
MagicAnimate: Temporally Consistent Human Image Animation using Diffusion Model (Nov., 2023)
-
FlowZero: Zero-Shot Text-to-Video Synthesis with LLM-Driven Dynamic Scene Syntax (Nov., 2023)
-
Sketch Video Synthesis (Nov., 2023)
-
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets (Nov., 2023)
-
Decouple Content and Motion for Conditional Image-to-Video Generation (Nov., 2023)
-
FusionFrames: Efficient Architectural Aspects for Text-to-Video Generation Pipeline (Nov., 2023)
-
Fine-Grained Open Domain Image Animation with Motion Guidance (Nov., 2023)
-
GPT4Motion: Scripting Physical Motions in Text-to-Video Generation via Blender-Oriented GPT Planning (Nov., 2023)
-
MagicDance: Realistic Human Dance Video Generation with Motions & Facial Expressions Transfer (Nov., 2023)
-
MoVideo: Motion-Aware Video Generation with Diffusion Models (Nov., 2023)
-
Make Pixels Dance: High-Dynamic Video Generation (Nov., 2023)
-
Emu Video: Factorizing Text-to-Video Generation by Explicit Image Conditioning (Nov., 2023)
-
Optimal Noise pursuit for Augmenting Text-to-Video Generation (Nov., 2023)
-
VideoDreamer: Customized Multi-Subject Text-to-Video Generation with Disen-Mix Finetuning (Nov., 2023)
-
SEINE: Short-to-Long Video Diffusion Model for Generative Transition and Prediction (Oct., 2023)
-
FreeNoise: Tuning-Free Longer Video Diffusion Via Noise Rescheduling (Oct., 2023)
-
DynamiCrafter: Animating Open-domain Images with Video Diffusion Priors (Oct., 2023)
-
LAMP: Learn A Motion Pattern for Few-Shot-Based Video Generation (Oct., 2023)
-
Show-1: Marrying Pixel and Latent Diffusion Models for Text-to-Video Generation (Sep., 2023)
-
MotionDirector: Motion Customization of Text-to-Video Diffusion Models (Sep., 2023)
-
LAVIE: High-Quality Video Generation with Cascaded Latent Diffusion Models (Sep., 2023)
-
Diverse and Aligned Audio-to-Video Generation via Text-to-Video Model Adaptation (Sep., 2023)
-
Free-Bloom: Zero-Shot Text-to-Video Generator with LLM Director and LDM Animator (Sep., 2023)
-
Hierarchical Masked 3D Diffusion Model for Video Outpainting (Sep., 2023)
-
Reuse and Diffuse: Iterative Denoising for Text-to-Video Generation (Sep., 2023)
-
VideoGen: A Reference-Guided Latent Diffusion Approach for High Definition Text-to-Video Generation (Sep., 2023)
-
MagicAvatar: Multimodal Avatar Generation and Animation (Aug., 2023)
-
Empowering Dynamics-aware Text-to-Video Diffusion with Large Language Models (Aug., 2023)
-
SimDA: Simple Diffusion Adapter for Efficient Video Generation (Aug., 2023)
-
ModelScope Text-to-Video Technical Report (Aug., 2023)
-
Dual-Stream Diffusion Net for Text-to-Video Generation (Aug., 2023)
-
InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation (Jul., 2023)
-
Animate-A-Story: Storytelling with Retrieval-Augmented Video Generation (Jul., 2023)
-
AnimateDiff: Animate Your Personalized Text-to-Image Diffusion Models without Specific Tuning (Jul., 2023)
-
DisCo: Disentangled Control for Referring Human Dance Generation in Real World (Jul., 2023)
-
Learn the Force We Can: Enabling Sparse Motion Control in Multi-Object Video Generation (Jun., 2023)
-
VideoComposer: Compositional Video Synthesis with Motion Controllability (Jun., 2023)
-
Probabilistic Adaptation of Text-to-Video Models (Jun., 2023)
-
Make-Your-Video: Customized Video Generation Using Textual and Structural Guidance (Jun., 2023)
-
Gen-L-Video: Multi-Text to Long Video Generation via Temporal Co-Denoising (May, 2023)
-
Cinematic Mindscapes: High-quality Video Reconstruction from Brain Activity (May, 2023)
-
Any-to-Any Generation via Composable Diffusion (May, 2023)
-
VideoFactory: Swap Attention in Spatiotemporal Diffusions for Text-to-Video Generation (May, 2023)
-
Preserve Your Own Correlation: A Noise Prior for Video Diffusion Models (May, 2023)
-
LaMD: Latent Motion Diffusion for Video Generation (Apr., 2023)
-
Align your Latents: High-Resolution Video Synthesis with Latent Diffusion Models (CVPR 2023)
-
Text2Performer: Text-Driven Human Video Generation (Apr., 2023)
-
Generative Disco: Text-to-Video Generation for Music Visualization (Apr., 2023)
-
Latent-Shift: Latent Diffusion with Temporal Shift (Apr., 2023)
-
DreamPose: Fashion Image-to-Video Synthesis via Stable Diffusion (Apr., 2023)
-
Follow Your Pose: Pose-Guided Text-to-Video Generation using Pose-Free Videos (Apr., 2023)
-
Physics-Driven Diffusion Models for Impact Sound Synthesis from Videos (CVPR 2023)
-
Seer: Language Instructed Video Prediction with Latent Diffusion Models (Mar., 2023)
-
Text2video-Zero: Text-to-Image Diffusion Models Are Zero-Shot Video Generators (Mar., 2023)
-
Conditional Image-to-Video Generation with Latent Flow Diffusion Models (CVPR 2023)
-
Decomposed Diffusion Models for High-Quality Video Generation (CVPR 2023)
-
Video Probabilistic Diffusion Models in Projected Latent Space (CVPR 2023)
-
Learning 3D Photography Videos via Self-supervised Diffusion on Single Images (Feb., 2023)
-
Structure and Content-Guided Video Synthesis With Diffusion Models (Feb., 2023)
-
Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation (ICCV 2023)
-
Mm-Diffusion: Learning Multi-Modal Diffusion Models for Joint Audio and Video Generation (CVPR 2023)
-
Magvit: Masked Generative Video Transformer (Dec., 2022)
-
VIDM: Video Implicit Diffusion Models (AAAI 2023)
-
Efficient Video Prediction via Sparsely Conditioned Flow Matching (Nov., 2022)
-
Latent Video Diffusion Models for High-Fidelity Video Generation With Arbitrary Lengths (Nov., 2022)
-
SinFusion: Training Diffusion Models on a Single Image or Video (Nov., 2022)
-
MagicVideo: Efficient Video Generation With Latent Diffusion Models (Nov., 2022)
-
Imagen Video: High Definition Video Generation With Diffusion Models (Oct., 2022)
-
Make-A-Video: Text-to-Video Generation without Text-Video Data (ICLR 2023)
-
Diffusion Models for Video Prediction and Infilling (TMLR 2022)
-
McVd: Masked Conditional Video Diffusion for Prediction, Generation, and Interpolation (NeurIPS 2022)
-
Video Diffusion Models (Apr., 2022)
-
Diffusion Probabilistic Modeling for Video Generation (Mar., 2022)










































































-
FreeTraj: Tuning-Free Trajectory Control in Video Diffusion Models (Jun., 2024)
-
Champ: Controllable and Consistent Human Image Animation with 3D Parametric Guidance (Mar., 2024)
-
TrailBlazer: Trajectory Control for Diffusion-Based Video Generation (Jan., 2024)
-
Motion-Zero: Zero-Shot Moving Object Control Framework for Diffusion-Based Video Generation (Jan., 2024)
-
Moonshot: Towards Controllable Video Generation and Editing with Multimodal Conditions (Jan., 2024)
-
MotionCtrl: A Unified and Flexible Motion Controller for Video Generation (Dec., 2023)
-
Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation (Nov., 2023)
-
SparseCtrl: Adding Sparse Controls to Text-to-Video Diffusion Models (Nov., 2023)
-
Control-A-Video: Controllable Text-to-Video Generation with Diffusion Models (May, 2023)
-
Motion-Conditioned Diffusion Model for Controllable Video Synthesis (Apr., 2023)
-
ControlVideo: Training-free Controllable Text-to-Video Generation (May, 2023)
-
DragNUWA: Fine-grained Control in Video Generation by Integrating Text, Image, and Trajectory (Aug., 2023)
-
DragAnything: Motion Control for Anything using Entity Representation (Mar., 2024)
-
CameraCtrl: Enabling Camera Control for Video Diffusion Models (Apr., 2024)
-
Training-free Camera Control for Video Generation (Jun., 2024)
-
Customizing Motion in Text-to-Video Diffusion Models (Dec., 2023)
-
MotionClone: Training-Free Motion Cloning for Controllable Video Generation (Jun., 2024)









-
Unified Editing of Panorama, 3D Scenes, and Videos Through Disentangled Self-Attention Injection (May, 2024)
-
I2VEdit: First-Frame-Guided Video Editing via Image-to-Video Diffusion Models (May, 2024)
-
Looking Backward: Streaming Video-to-Video Translation with Feature Banks (May, 2024)
-
ReVideo: Remake a Video with Motion and Content Control (May, 2024)
-
Slicedit: Zero-Shot Video Editing With Text-to-Image Diffusion Models Using Spatio-Temporal Slices (May, 2024)
-
ViViD: Video Virtual Try-on using Diffusion Models (May, 2024)
-
Edit-Your-Motion: Space-Time Diffusion Decoupling Learning for Video Motion Editing (May, 2024)
-
GenVideo: One-shot target-image and shape aware video editing using T2I diffusion models (Apr., 2024)
-
EVA: Zero-shot Accurate Attributes and Multi-Object Video Editing (Mar., 2024)
-
Spectral Motion Alignment for Video Motion Transfer using Diffusion Models (Mar., 2024)
-
AnyV2V: A Tuning-Free Framework For Any Video-to-Video Editing Tasks (Mar., 2024)
-
CoCoCo: Improving Text-Guided Video Inpainting for Better Consistency, Controllability and Compatibility (Mar., 2024)
-
DreamMotion: Space-Time Self-Similarity Score Distillation for Zero-Shot Video Editing (Mar., 2024)
-
Video Editing via Factorized Diffusion Distillation (Mar., 2024)
-
FastVideoEdit: Leveraging Consistency Models for Efficient Text-to-Video Editing (Mar., 2024)
-
UniEdit: A Unified Tuning-Free Framework for Video Motion and Appearance Editing (Feb., 2024)
-
Object-Centric Diffusion for Efficient Video Editing (Jan., 2024)
-
VASE: Object-Centric Shape and Appearance Manipulation of Real Videos (Jan., 2024)
-
FlowVid: Taming Imperfect Optical Flows for Consistent Video-to-Video Synthesis (Dec., 2023)
-
Fairy: Fast Parallelized Instruction-Guided Video-to-Video Synthesis (Dec., 2023)
-
RealCraft: Attention Control as A Solution for Zero-shot Long Video Editing (Dec., 2023)
-
MaskINT: Video Editing via Interpolative Non-autoregressive Masked Transformers (Dec., 2023)
-
VidToMe: Video Token Merging for Zero-Shot Video Editing (Dec., 2023)
-
A Video is Worth 256 Bases: Spatial-Temporal Expectation-Maximization Inversion for Zero-Shot Video Editing (Dec., 2023)
-
Neutral Editing Framework for Diffusion-based Video Editing (Dec., 2023)
-
DiffusionAtlas: High-Fidelity Consistent Diffusion Video Editing (Dec., 2023)
-
RAVE: Randomized Noise Shuffling for Fast and Consistent Video Editing with Diffusion Models (Dec., 2023)
-
SAVE: Protagonist Diversification with Structure Agnostic Video Editing (Dec., 2023)
-
MagicStick: Controllable Video Editing via Control Handle Transformations (Dec., 2023)
-
VideoSwap: Customized Video Subject Swapping with Interactive Semantic Point Correspondence (CVPR 2024)
-
DragVideo: Interactive Drag-style Video Editing (Dec., 2023)
-
Drag-A-Video: Non-rigid Video Editing with Point-based Interaction (Dec., 2023)
-
BIVDiff: A Training-Free Framework for General-Purpose Video Synthesis via Bridging Image and Video Diffusion Models (Dec., 2023)
-
VMC: Video Motion Customization using Temporal Attention Adaption for Text-to-Video Diffusion Models (CVPR 2024)
-
FLATTEN: optical FLow-guided ATTENtion for consistent text-to-video editing (ICLR 2024)
-
MotionEditor: Editing Video Motion via Content-Aware Diffusion (Nov., 2023)
-
Motion-Conditioned Image Animation for Video Editing (Nov., 2023)
-
Space-Time Diffusion Features for Zero-Shot Text-Driven Motion Transfer (CVPR 2024)
-
Cut-and-Paste: Subject-Driven Video Editing with Attention Control (Nov., 2023)
-
LatentWarp: Consistent Diffusion Latents for Zero-Shot Video-to-Video Translation (Nov., 2023)
-
Fuse Your Latents: Video Editing with Multi-source Latent Diffusion Models (Oct., 2023)
-
DynVideo-E: Harnessing Dynamic NeRF for Large-Scale Motion- and View-Change Human-Centric Video Editing (Oct., 2023)
-
Ground-A-Video: Zero-shot Grounded Video Editing using Text-to-image Diffusion Models (ICLR 2024)
-
CCEdit: Creative and Controllable Video Editing via Diffusion Models (Sep., 2023)
-
MagicProp: Diffusion-based Video Editing via Motion-aware Appearance Propagation (Sep., 2023)
-
MagicEdit: High-Fidelity and Temporally Coherent Video Editing (Aug., 2023)
-
StableVideo: Text-driven Consistency-aware Diffusion Video Editing (ICCV 2023)
-
CoDeF: Content Deformation Fields for Temporally Consistent Video Processing (CVPR 2024)
-
TokenFlow: Consistent Diffusion Features for Consistent Video Editing (ICLR 2024)
-
INVE: Interactive Neural Video Editing (Jul., 2023)
-
VidEdit: Zero-Shot and Spatially Aware Text-Driven Video Editing (Jun., 2023)
-
Rerender A Video: Zero-Shot Text-Guided Video-to-Video Translation (SIGGRAPH Asia 2023)
-
ControlVideo: Adding Conditional Control for One Shot Text-to-Video Editing (May, 2023)
-
Make-A-Protagonist: Generic Video Editing with An Ensemble of Experts (May, 2023)
-
Soundini: Sound-Guided Diffusion for Natural Video Editing (Apr., 2023)
-
Zero-Shot Video Editing Using Off-the-Shelf Image Diffusion Models (Mar., 2023)
-
Edit-A-Video: Single Video Editing with Object-Aware Consistency (Mar., 2023)
-
FateZero: Fusing Attentions for Zero-shot Text-based Video Editing (Mar., 2023)
-
Pix2video: Video Editing Using Image Diffusion (Mar., 2023)
-
Video-P2P: Video Editing with Cross-attention Control (Mar., 2023)
-
Dreamix: Video Diffusion Models Are General Video Editors (Feb., 2023)
-
Shape-Aware Text-Driven Layered Video Editing (Jan., 2023)
-
Speech Driven Video Editing via an Audio-Conditioned Diffusion Model (Jan., 2023)
































-
MCVD: Masked Conditional Video Diffusion for Prediction, Generation, and Interpolation (NeurIPS 2022)
-
NUWA-XL: Diffusion over Diffusion for eXtremely Long Video Generation (Mar., 2023)
-
Flexible Diffusion Modeling of Long Videos (May, 2022)


-
Hallo: Hierarchical Audio-Driven Visual Synthesis for Portrait Image Animation (Jun., 2024)
-
Avatars Grow Legs: Generating Smooth Human Motion from Sparse Tracking Inputs with Diffusion Model (CVPR 2023)
-
InterGen: Diffusion-based Multi-human Motion Generation under Complex Interactions (Apr., 2023)
-
ReMoDiffuse: Retrieval-Augmented Motion Diffusion Model (Apr., 2023)
-
Human Motion Diffusion as a Generative Prior (Mar., 2023)
-
Can We Use Diffusion Probabilistic Models for 3d Motion Prediction? (Feb., 2023)
-
Single Motion Diffusion (Feb., 2023)
-
HumanMAC: Masked Motion Completion for Human Motion Prediction (Feb., 2023)
-
DiffMotion: Speech-Driven Gesture Synthesis Using Denoising Diffusion Model (Jan., 2023)
-
Modiff: Action-Conditioned 3d Motion Generation With Denoising Diffusion Probabilistic Models (Jan., 2023)
-
Unifying Human Motion Synthesis and Style Transfer With Denoising Diffusion Probabilistic Models (GRAPP 2023)
-
Executing Your Commands via Motion Diffusion in Latent Space (CVPR 2023)
-
Pretrained Diffusion Models for Unified Human Motion Synthesis (Dec., 2022)
-
PhysDiff: Physics-Guided Human Motion Diffusion Model (Dec., 2022)
-
BeLFusion: Latent Diffusion for Behavior-Driven Human Motion Prediction (Dec., 2022)
-
Listen, Denoise, Action! Audio-Driven Motion Synthesis With Diffusion Models (Nov. 2022)
-
Diffusion Motion: Generate Text-Guided 3d Human Motion by Diffusion Model (ICASSP 2023)
-
Human Joint Kinematics Diffusion-Refinement for Stochastic Motion Prediction (Oct., 2022)
-
Human Motion Diffusion Model (ICLR 2023)
-
FLAME: Free-form Language-based Motion Synthesis & Editing (AAAI 2023)
-
MotionDiffuse: Text-Driven Human Motion Generation with Diffusion Model (Aug., 2022)
-
Stochastic Trajectory Prediction via Motion Indeterminacy Diffusion (CVPR 2022)
















-
LDMVFI: Video Frame Interpolation with Latent Diffusion Models (Mar., 2023)
-
CaDM: Codec-aware Diffusion Modeling for Neural-enhanced Video Streaming (Nov., 2022)
-
MultiDiff: Consistent Novel View Synthesis from a Single Image (CVPR, 2024)
-
Vivid-ZOO: Multi-View Video Generation with Diffusion Model (Jun, 2024)
-
Director3D: Real-world Camera Trajectory and 3D Scene Generation from Text (June, 2024)
-
YouDream: Generating Anatomically Controllable Consistent Text-to-3D Animals (June, 2024)
-
Text2NeRF: Text-Driven 3D Scene Generation with Neural Radiance Fields (May, 2023)
-
RoomDreamer: Text-Driven 3D Indoor Scene Synthesis with Coherent Geometry and Texture (May, 2023)
-
NeuralField-LDM: Scene Generation with Hierarchical Latent Diffusion Models (CVPR 2023)
-
Single-Stage Diffusion NeRF: A Unified Approach to 3D Generation and Reconstruction (Apr., 2023)
-
Instruct-NeRF2NeRF: Editing 3D Scenes with Instructions (Mar., 2023)
-
DiffusioNeRF: Regularizing Neural Radiance Fields with Denoising Diffusion Models (Feb., 2023)
-
NerfDiff: Single-image View Synthesis with NeRF-guided Distillation from 3D-aware Diffusion (Feb., 2023)
-
DiffRF: Rendering-guided 3D Radiance Field Diffusion (CVPR 2023)






-
Exploring Diffusion Models for Unsupervised Video Anomaly Detection (Apr., 2023)
-
PDPP:Projected Diffusion for Procedure Planning in Instructional Videos (CVPR 2023)
-
DiffTAD: Temporal Action Detection with Proposal Denoising Diffusion (Mar., 2023)
-
Diffusion Action Segmentation (ICCV 2023)
-
DiffusionRet: Generative Text-Video Retrieval with Diffusion Model (ICCV 2023)
-
Refined Semantic Enhancement Towards Frequency Diffusion for Video Captioning (Nov., 2022)
-
A Generalist Framework for Panoptic Segmentation of Images and Videos (Oct., 2022)





