
Group Project for CS605 Natural Language Processing for Smart Assistant
- Project Title: Leveraging Advanced NLP and RAG for Dynamic Gameplay Chatbot
- Group Member: Mary Vanessa Heng Hui Khim, Yee Jun Yit, Yeo York Yong, Zhuang Yiwen
The evolution of open-world games has significantly increased the complexity and richness of gameplay. These games often feature intricate mechanics, diverse ecosystems, and dynamic systems that respond to player actions. However, this complexity presents challenges for many players, especially casual gamers, novices, and those new to the genre. Players struggle to understand intricate game mechanics, locate specific items, and navigate various systems (e.g., crafting, character progression, combat mechanics, quests). This can lead to frustration and a sense of being lost in the game world (Wang et al. 2023).
Current Large Language Models (LLMs) lack domain-specific knowledge related to gaming mechanics, strategies, and objectives. They provide generic or irrelevant responses when players seek assistance with in-game challenges or objectives. Additionally, LLMs struggle to handle dynamic game situations or understand individual player objectives without significant customization (Kim et al. 2023).
To address these challenges, we propose developing a sophisticated game chatbot. Our contributions include:
-
Implementing NLP and RAG Techniques: We leverage Natural Language Processing (NLP) and Retrieval-Augmented Generation (RAG) techniques to assist players with their game-related queries.
-
Creating a Dynamic and Personalized Game Chatbot: Our chatbot provides gameplay tips, strategies, and a companion experience tailored to individual player needs. It adapts to player progression and style, refining its assistance based on feedback.
-
Experimenting with Parameters: We explore different embeddings, LLM types, and prompt testing to optimize the chatbot’s accuracy.

- User Query: The process begins with a user query (e.g., “What are the three starter Pokemon in the game?”).
- Embedding Model: The user query is converted into an embedded representation using an embedding model (e.g., Ollama, OpenAI, GoogleGenerativeAI).
- Vector Database: A database of pre-processed documents using (e.g. Facebook AI Similarity Search (FAISS)) stores the embedding and is made available.
- Vector Comparison: The embedded user query is compared against the document embeddings in the database.
- Top-k Retrieval: The system retrieves the top-k most similar documents based on vector similarity scores.
Generation Component:
- Context Creation: The retrieved documents are combined with the original user query to create context (e.g., “The starter Pokémon options in Paldea are Sprigatito (Grass), Fuecoco (Fire), and Quaxly (Water).”).
- Language Model (LLM): A pre-trained language model (e.g., Llama3) takes this context as input.
- Prompt Generation: The LLM generates a prompt that incorporates both the user query and the retrieved document information.
- Answer Generation: Using this prompt, the LLM generates a specific answer (e.g., “The new Pokemon Scarlet and Pokemon Violet starters are Sprigatito, Fuecoco, and Quaxly,”).

RAGAS evaluation framework is designed to assess and quantify the performance of Retrieval-Augmented Generation (RAG) pipelines. The ragas score consist of these two components:
- Generation Assessment: Evaluates the quality of LLM-generated text. Metrics include faithfulness (alignment with retrieved context) and answer correctness.
- Retrieval Assessment: Focuses on the effectiveness of the retrieval component. Measures how well the system retrieves relevant documents and ensures that retrieved context enhances LLM responses.
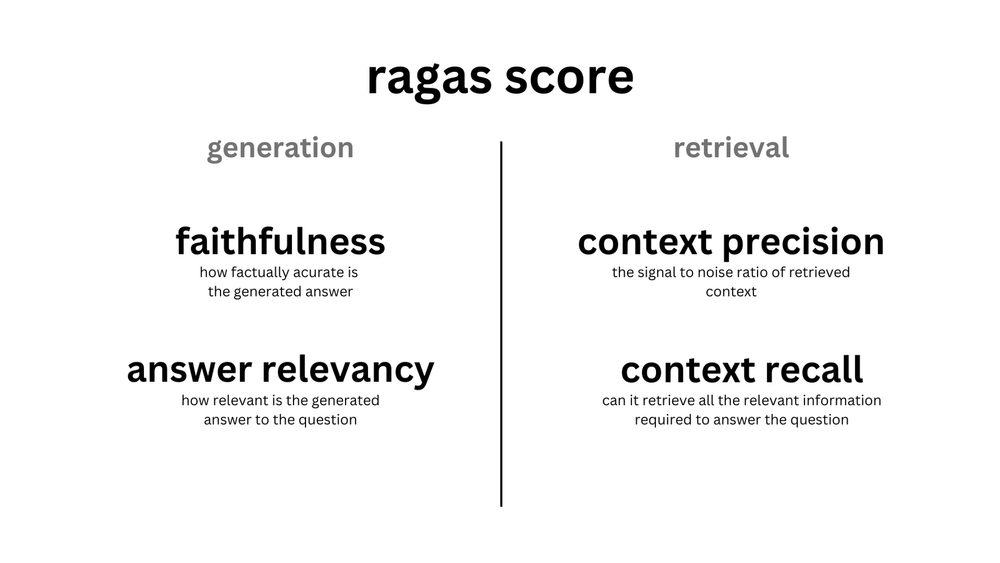
- Faithfulness measures how well the generated answer aligns with the information provided in the retrieved context. It ensures that the response remains consistent with the facts presented in the context.
- The answer is scaled to (0,1) range. Higher the better.
Question: Where and when was Einstein born?
- Context: Albert Einstein (born 14 March 1879) was a German-born theoretical physicist, widely held to be one of the greatest and most influential scientists of all time
- High faithfulness answer: Einstein was born in Germany on 14th March 1879.
- Low faithfulness answer: Einstein was born in Germany on 20th March 1879.
- Answer Relevancy assesses how pertinent the generated answer is to the given prompt. It measures the alignment between the answer and the original question. Lower scores are assigned to incomplete or irrelevant answers, while higher scores indicate better relevancy.
Where:
-
$E_{g_i}$ is the embedding of the generated question -
$E_{o}$ is the embedding of the original question. -
$N$ is the number of generated questions, which is 3 default.
- Context Precision evaluates whether all relevant items (chunks) from the ground truth appear at higher ranks in the retrieved contexts. Ideally, relevant chunks should be ranked at the top. It measures how well the system prioritizes relevant context.
- The resulting value ranges between 0 and 1, where higher scores indicate better precision.
Where
- This metric gauges the relevancy of the retrieved context, calculated based on both the question and contexts. The values fall within the range of (0, 1), with higher values indicating better relevancy.
- Ideally, the retrieved context should exclusively contain essential information to address the provided query. To compute this, we initially estimate the value of by identifying sentences within the retrieved context that are relevant for answering the given question. The final score is determined by the following formula:
Question: What is the capital of France?
- High context relevancy: France, in Western Europe, encompasses medieval cities, alpine villages and Mediterranean beaches. Paris, its capital, is famed for its fashion houses, classical art museums including the Louvre and monuments like the Eiffel Tower.
- Low context relevancy: France, in Western Europe, encompasses medieval cities, alpine villages and Mediterranean beaches. Paris, its capital, is famed for its fashion houses, classical art museums including the Louvre and monuments like the Eiffel Tower. The country is also renowned for its wines and sophisticated cuisine. Lascaux’s ancient cave drawings, Lyon’s Roman theater and the vast Palace of Versailles attest to its rich history.
- Context recall measures the extent to which the retrieved context aligns with the annotated answer, treated as the ground truth. It is computed based on the ground truth and the retrieved context, and the values range between 0 and 1, with higher values indicating better performance. The formula for calculating context recall is as follows:
Question: Where is France and what is it’s capital?
- Ground truth: France is in Western Europe and its capital is Paris.
- High context recall: France, in Western Europe, encompasses medieval cities, alpine villages and Mediterranean beaches. Paris, its capital, is famed for its fashion houses, classical art museums including the Louvre and monuments like the Eiffel Tower.
- Low context recall: France, in Western Europe, encompasses medieval cities, alpine villages and Mediterranean beaches. The country is also renowned for its wines and sophisticated cuisine. Lascaux’s ancient cave drawings, Lyon’s Roman theater and the vast Palace of Versailles attest to its rich history.
- Context Recall measures the proportion of relevant entities (e.g., facts, names, locations) that are correctly retrieved from the ground truth context. It quantifies how well the system recalls entities from the retrieved context.
- To compute this metric, we use two sets,
$GE$ and$CE$ , as set of entities present in ground_truths and set of entities present in contexts respectively. - We then take the number of elements in intersection of these sets and divide it by the number of elements present in the
$GE$ , given by the formula:
- Ground truth: The Taj Mahal is an ivory-white marble mausoleum on the right bank of the river Yamuna in the Indian city of Agra. It was commissioned in 1631 by the Mughal emperor Shah Jahan to house the tomb of his favorite wife, Mumtaz Mahal.
- High entity recall context: The Taj Mahal is a symbol of love and architectural marvel located in Agra, India. It was built by the Mughal emperor Shah Jahan in memory of his beloved wife, Mumtaz Mahal. The structure is renowned for its intricate marble work and beautiful gardens surrounding it.
- Low entity recall context: The Taj Mahal is an iconic monument in India. It is a UNESCO World Heritage Site and attracts millions of visitors annually. The intricate carvings and stunning architecture make it a must-visit destination.
- The concept of Answer Semantic Similarity pertains to the assessment of the semantic resemblance between the generated answer and the ground truth.
- This evaluation is based on the ground truth and the answer, with values falling within the range of 0 to 1. A higher score signifies a better alignment between the generated answer and the ground truth.
- Measuring the semantic similarity between answers can offer valuable insights into the quality of the generated response. This evaluation utilizes a cross-encoder model to calculate the semantic similarity score.
- Ground truth: Albert Einstein’s theory of relativity revolutionized our understanding of the universe.”
- High similarity answer: Einstein’s groundbreaking theory of relativity transformed our comprehension of the cosmos.
- Low similarity answer: Isaac Newton’s laws of motion greatly influenced classical physics.
- Explain how accurate the generated answer is assessed based on the ground truth.
- This evaluation relies on the ground truth and the answer, with scores ranging from 0 to 1. A higher score indicates a closer alignment between the generated answer and the ground truth, signifying better correctness.
- Answer correctness encompasses two critical aspects: semantic similarity between the generated answer and the ground truth, as well as factual similarity. These aspects are combined using a weighted scheme to formulate the answer correctness score. Users also have the option to employ a ‘threshold’ value to round the resulting score to binary, if desired.
- Ground truth: Einstein was born in 1879 in Germany.
- High answer correctness: In 1879, Einstein was born in Germany.
- Low answer correctness: Einstein was born in Spain in 1879.
Environment and Code:
- Clone the following github repo
https://github.com/yYorky/Pokemon-Game-RAG-Chatbot.git - Create a virtual environment first using
conda create -p venv python==3.10 -y - Ensure you have the necessary dependencies installed
pip install -r requirements.txt - Set up environment variables
.envfor API keys (e.g., OpenAI, GoogleGenerativeAI, GROQ).
Data Preparation:
- Prepare an evaluation dataset in CSV format that is based on the reference document.
- The dataset should contain at least two columns: ‘question’ and ‘ground_truth’.
Running the System:
-
Run the Streamlit app.
- Use
streamlit run groq/model_eval.pyto run evaluation version - Use
streamlit run groq/model_base.pyto run basic version
- Use
-
In the Customization sidebar: select the appropriate settings for testing
-
Choose a model (e.g. llama3)
-
Choose an embedding type (e.g., OpenAI, Ollama, or GoogleGenerativeAI).
-
Select a conversational memory length (how long the chatbot should use past conversation for inputs)
-
Choose a Chunk size and Chunk Overlap for document embedding
-
Type a prompt for the LLM if necessary
-
Click on Documents Embedding to embed document
-
The RAG chatbot is now ready to use.
Using model_base.py
- Ask questions related to Pokemon Scarlet & Violet and view the response
- Click on document similarity search to view the retreived chunks

Using model_eval.py
- Upload the evaluation dataset in the sidebar.
- Ask questions related to Pokemon Scarlet & Violet.
- The system will retrieve context and generate responses using RAG as well as compute evaluation metrics using RAGAS framework
- Continue asking questions as necessary, if there are questions asked that are not in the evaluation dataset it will skip the RAGAS evaluation
- Click on Save Evaluation Results and Download results to review

- Wang, B., Gao, Z., & Shidujaman, M. (2023). Meaningful place: A phenomenological approach to the design of spatial experience in open-world games. Journal of Game Design, 10(2), 45-621. https://doi.org/10.1177/15554120231171290
- Hugging Face. (n.d.). Advanced RAG (Retrieval-Augmented Generation) Cookbook. Retrieved from https://huggingface.co/learn/cookbook/advanced_rag
- Ragas Documentation (n.d.). Retrieved from https://docs.ragas.io/en/latest/concepts/metrics/index.html
- Github by Krishnaik06. (n.d.). Updated Langchain. Retrieved from https://github.com/krishnaik06/Updated-Langchain
- Guthub by Alejandro-ao. (n.d.). Ask Multiple PDFs. Retrieved from https://github.com/alejandro-ao/ask-multiple-pdfs
- (reddit)Brittlebear (2023) Pokemon Scarlet And Violet Walkthrough. Retreived from https://docs.google.com/document/d/1xL1NNZnKRabyl93BewLzcZkcvmDJj2612K0Ih10hqXQ/edit#heading=h.82hsajnz9z9b