Grounding DINO Methods | 
Grounding DINO Demos |

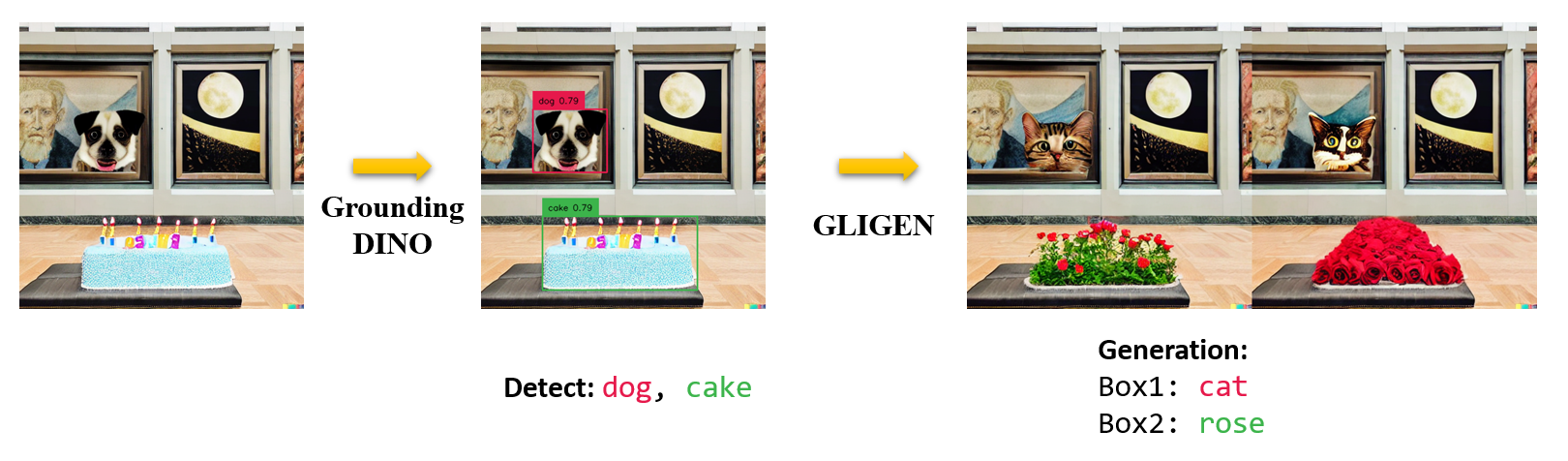
Extensions | Grounding DINO with Segment Anything; Grounding DINO with Stable Diffusion; Grounding DINO with GLIGEN
Official PyTorch implementation of Grounding DINO, a stronger open-set object detector. Code is available now!
- Open-Set Detection. Detect everything with language!
- High Performancce. COCO zero-shot 52.5 AP (training without COCO data!). COCO fine-tune 63.0 AP.
- Flexible. Collaboration with Stable Diffusion for Image Editting.
2023/04/15: Refer to CV in the Wild Readings for those who are interested in open-set recognition!2023/04/08: We release demos to combine Grounding DINO with GLIGEN for more controllable image editings.2023/04/08: We release demos to combine Grounding DINO with Stable Diffusion for image editings.2023/04/06: We build a new demo by marrying GroundingDINO with Segment-Anything named Grounded-Segment-Anything aims to support segmentation in GroundingDINO.2023/03/28: A YouTube video about Grounding DINO and basic object detection prompt engineering. [SkalskiP]2023/03/28: Add a demo on Hugging Face Space!2023/03/27: Support CPU-only mode. Now the model can run on machines without GPUs.2023/03/25: A demo for Grounding DINO is available at Colab. [SkalskiP]2023/03/22: Code is available Now!

- Grounding DINO accepts an
(image, text)pair as inputs. - It outputs
900(by default) object boxes. Each box has similarity scores across all input words. (as shown in Figures below.) - We defaultly choose the boxes whose highest similarities are higher than a
box_threshold. - We extract the words whose similarities are higher than the
text_thresholdas predicted labels. - If you want to obtain objects of specific phrases, like the
dogsin the sentencetwo dogs with a stick., you can select the boxes with highest text similarities withdogsas final outputs. - Note that each word can be split to more than one tokens with differetn tokenlizers. The number of words in a sentence may not equal to the number of text tokens.
- We suggest separating different category names with
.for Grounding DINO.



- Release inference code and demo.
- Release checkpoints.
- Grounding DINO with Stable Diffusion and GLIGEN demos.
- Release training codes.
If you h