3) Nerf for large scenes and 3d mapping: aka Google live view and Apple Fly around
- Bounded and Unbounded Neural Radiance Fields
-
Combining multiple Nerfs to a map
- Building NeRF at City Scale, 2021
- Urban Radiance Fields
- LIDAR Constrained NeRF on Outdoor Scenes
- Block-NeRF, 2022
- Google live view, 2022
- Apple fly around, 2022
- NeRFusion: Fusing Radiance Fields for Large-Scale Scene Reconstruction, 2022
- NeRFuser, 2023
- PlaNeRF: SVD Unsupervised 3D Plane Regularization for NeRF Large-Scale Scene Reconstruction, 2023
- Hybrid large scale rendering
- Nerf compositing for avatars
- Multi-resolution Nerfs
- Google Reconstructing indoor spaces with NeRF, 2023
Table of contents generated with markdown-toc
Real forward-facing scenes and synthetic bounded scenes
If you are trying to reconstruct a scene or object from images, you may wish to consider adding a spatial distortion. When rendering a target view of a scene, the camera will emit a camera ray for each pixel and query the scene at points along this ray. We can choose where to query these points using different samplers.
These samplers have some notion of bounds that define where the ray should start and terminate. If you know that everything in your scenes exists within some predefined bounds (ie. a cube that a room fits in) then the sampler will properly sample the entire space. If however the scene is unbounded (ie. an outdoor scene) defining where to stop sampling is challenging. One option to increase the far sampling distance to a large value (ie. 1km). Alternatively we can warp the space into a fixed volume. Below are supported distortions.
https://jonbarron.info/mipnerf360/

We explore how to leverage neural radiance fields (NeRFs) to build interactive 3D environments from large-scale visual captures spanning buildings or even multiple city blocks collected primarily from drone data. In contrast to the single object scenes against which NeRFs have been traditionally evaluated, this setting poses multiple challenges including (1) the need to incorporate thousands of images with varying lighting conditions, all of which capture only a small subset of the scene, (2) prohibitively high model capacity and ray sampling requirements beyond what can be naively trained on a single GPU, and (3) an arbitrarily large number of possible viewpoints that make it unfeasible to precompute all relevant information beforehand (as real-time NeRF renderers typically do). https://arxiv.org/abs/2112.10703
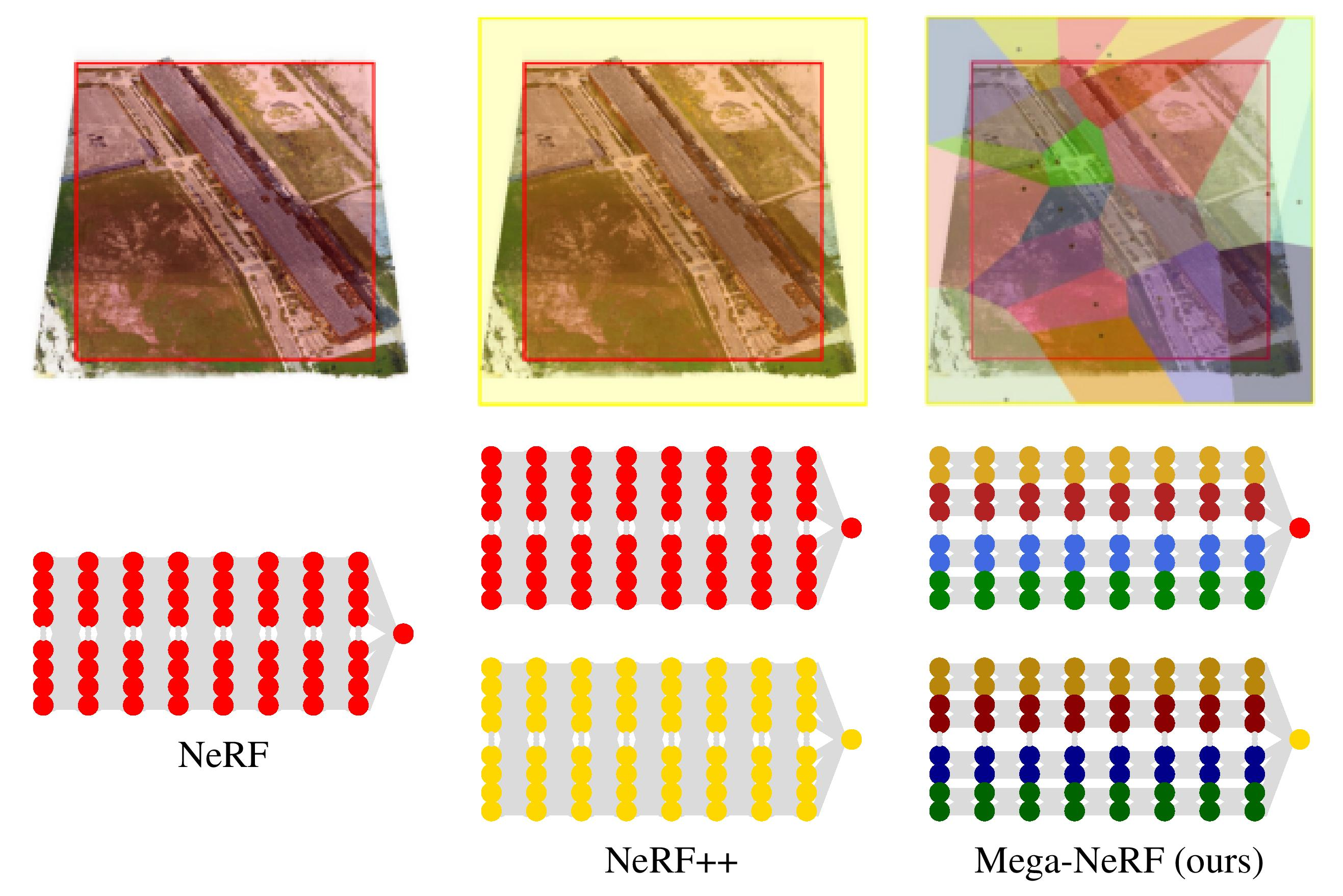
https://github.com/cmusatyalab/mega-nerf
A learning-based framework for disentangling
outdoor scenes into temporally-varying illumination and permanent scene
factors imagery from Google Street View, where the same locations are
captured repeatedly through time.


Source: https://en.wikipedia.org/wiki/Light_stage


Instead of having different pictures a few centimeters apart this approach can handle have pictures from thousands of kilometers apart, ranging from satellites to pictures taken on the road. As you can see, NeRF alone fails to use such drastically different pictures to reconstruct the scenes. CityNeRF is capable of packing city-scale 3D scenes into a unified model, which preserves high-quality details across scales varying from satellite-level to ground-level.
Source:
First trains the neural network successively from distant viewpoints to close-up viewpoints -- and to train the neural network on transitions in between these "levels". This was inspired by "level of detail" systems currently in use by traditional 3D computer rendering systems. "Joint training on all scales results in blurry texture in close views and incomplete geometry in remote views. Separate training on each scale yields inconsistent geometries and textures between successive scales." So the system starts at the most distant level and incorporates more and more information from the next closer level as it progresses from level to level.
Modifies the neural network itself at each level by adding what they call a "block". A block has two separate information flows, one for the more distant and one for the more close up level being trained at that moment. It's designed in such a way that a set of information called "base" information is determined for the more distant level, and then "residual" information (in the form of colors and densities) that modifies the "base" and adds detail is calculated from there.
As current CityNeRF is built upon static scenes, it cannot handle inconsistency in the training data. We observed that, in Google Earth Studio [1], objects with slender geometry, such as a lightning rod, flicker as the camera pulls away. Artifacts like flickering moir patterns in the windows of skyscrapers, and differences in detail manifested as distinct square regions on the globe are also observed in the rendered images served as the ground truths2. Such defects lead to unstable rendering results around certain regions and bring about inconsistencies. A potential remedy is to treat it as a dynamic scene and associate each view with an appearance code that is jointly optimized as suggested in [6, 10]. Another potential limitation is on computation. The progressive strategy naturally takes longer training time, hence requires more computational resources.
https://urban-radiance-fields.github.io
Now implemented in nerfstudio https://github.com/nerfstudio-project/nerfstudio/pull/1173

https://www.yigitarastunali.com/project/lidar-constrainted-nerf-on-outdoor-scenes/

A method that enables large-scale scene reconstruction by representing the environment using multiple compact NeRFs that each fit into memory. At inference time, Block-NeRF seamlessly combines renderings of the relevant NeRFs for the given area. In this example, we reconstruct the Alamo Square neighborhood in San Francisco using data collected over 3 months. Block-NeRF can update individual blocks of the environment without retraining on the entire scene, as demonstrated by the construction on the right.
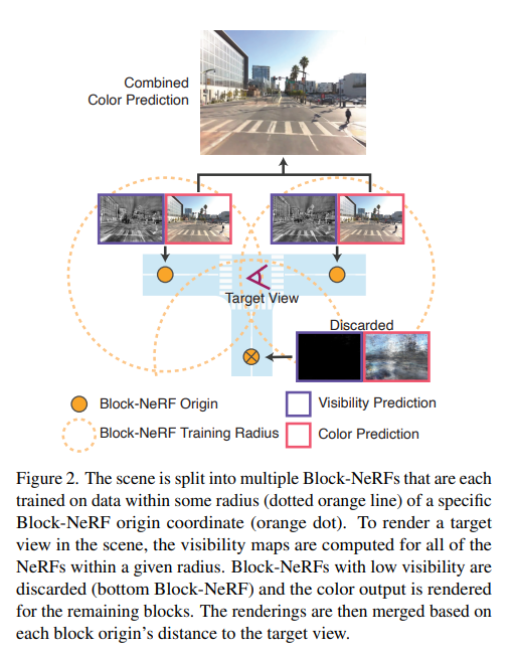
Video results can be found on the project website waymo.com/research/block-nerf.
- Unofficial implementation https://github.com/dvlab-research/BlockNeRFPytorch
Nikola Popovic, Danda Pani Paudel, Luc Van Gool
*arXiv: https://arxiv.org/abs/2212.01331

Uses Pixelstreaming, since google and apple are actively competing who is first techical detauls on both solutions are sparse

Instructions: https://support.apple.com/en-au/guide/iphone/iph81a3f978/ios
https://arxiv.org/pdf/2203.11283.pdf

-
https://github.com/3a1b2c3/nerfuser based on bnerfstudio


our contributions as follows:
- We propose a novel neural field representation that decomposes scene into geometry, spatially varying materials, and HDR lighting.
- To achieve efficient ray-tracing within a neural scene representation, we introduce a hybrid renderer that renders primary rays through volumetric rendering, and models the secondary rays using physics-based rendering. This enables high-quality inverse rendering of large urban scenes. *We model the HDR lighting and material properties of the scene, making our representation well suited for downstream applications such as relighting and virtual object insertion with cast shadows.

Neural G-buffer rendering To perform volume rendering *contains a normal map, a base color map, a material map and a depth map
- to predict the normal direction for any 3D location, and estimate the normal vectors through volume rendering of the normal field. We further regularize the predicted normal directions to be consistent with normals computed from the gradient of SD Field
Given the G-buffer, we can now perform the shading pass. To this end, we first extract an explicit mesh S of the scene from the optimized SD field using marching cubes
abs: https://buff.ly/3KfDtLH project page: https://buff.ly/3m7VUdr

https://www.unite.ai/creating-full-body-deepfakes-by-combining-multiple-nerfs/

Can handle inages with variable illumination (not photometrically static) cars and people may move, construction may begin or end, seasons and weather may change,
Given a large number of tourist photos taken at different times of day, this machine learning based approach learns to construct a continuous set of light fields and to synthesize novel views capturing all-times-of-day scene appearance. achieve convincing changes across a variety of times of day and lighting conditions. mask out transient objects such as people and cars during training and evaluation.

Source: https://www.semanticscholar.org/paper/Crowdsampling-the-Plenoptic-Function-Li-Xian

Source: Crowdsampling the Plenoptic Function, 2020
unsupervised manner. The approach takes unstructured Internet photos spanning some range of time-varying appearance in a scene and learns how to reconstruct a plenoptic slice, a representation of the light field that respects temporal structure in the plenoptic function when interpolated over time|for each of the viewing conditions captured in our input data. By designing our model to preserve the structure of real plenoptic functions, we force it to learn time-varying phenomena like the motion of shadows according to sun position. This lets us, for example, recover plenoptic slices for images taken at different times of day and interpolate between them to observe how shadows move as the day progresses (best seen in our supplemental video).

Optimize for Photometric Loss: The difference between the predicted color of the pixel (shown in Figure 9) and the actual color of the pixel makes the photometric loss. This eventually allows us to perform backpropagation on the MLP and minimize the loss. In effect, we learn a representation of the scene that can produce high-quality views from a continuum of viewpoints and viewing conditions that vary with time.

Source: NeRF-W Nerf in the wild
NeRF-W disentangles lighting from the underlying 3D scene geometry. The latter remains consistent even as the former changes.

Source: nerf in the wild
- Reference implementation (nerf and nerf in the wild using pytorch) https://github.com/kwea123/nerf_pl
https://formyfamily.github.io/NeROIC/ We present a novel method to acquire object representations from online image collections, capturing high-quality geometry and material properties of arbitrary objects from photographs with varying cameras, illumination, and backgrounds.

Source: Advances in Neural Rendering, https://www.neuralrender.com/
Article:https://lnkd.in/gsMbpD-7 Code Repo:https://lnkd.in/gRWvhra5 Implicit neural representation (INR) has emerged as a powerful paradigm for representing signals, such as images, videos, 3D shapes, etc. Although it has shown the ability to represent fine details, its efficiency as a data representation has not been extensively studied. In INR, the data is stored in the form of parameters of a neural network and general purpose optimization algorithms do not generally exploit the spatial and temporal redundancy in signals. In this paper, we suggest a novel INR approach to representing and compressing videos by explicitly removing data redundancy. Instead of storing raw RGB colors, we propose Neural Residual Flow Fields (NRFF), using motion information across video frames and residuals that are necessary to reconstruct a video. Maintaining the motion information, which is usually smoother and less complex than the raw signals, requires far fewer parameters. Furthermore, reusing redundant pixel values further improves the network parameter efficiency. Experimental results have shown that the proposed method outperforms the baseline methods by a significant margin.
The rendering procedure used by neural radiance fields (NeRF) samples a scene with a single ray per pixel and may therefore produce renderings that are excessively blurred or aliased when training or testing images observe scene content at different resolutions. The straightforward solution of supersampling by rendering with multiple rays per pixel is impractical for NeRF, because rendering each ray requires querying a multilayer perceptron hundreds of times. https://github.com/google/mipnerf
See also:
abs: https://buff.ly/3zZnHQm project page: https://buff.ly/3mw97wG

two key innovations: (a) we factorize the scene into three separate hash table data structures to efficiently encode static, dynamic, and far-field radiance fields, and (b) we make use of unlabeled target signals consisting of RGB images, sparse LiDAR, off-the-shelf self-supervised 2D descriptors, and most importantly, 2D optical flow
3 components: a static branch that models stationary topography that is consistent across videos, a dynamic branch that handles both transient (e.g., parked cars) and truly dynamic objects (e.g., pedestrians), and an environment map that handles far-field objects and sky. We model each branch using a multi-resolution hash table with scene partitioning, allowing SUDS to scale to an entire city spanning over 100 km2.

We learn an explicit shadow field (a) as a
pointwise reduction on static color, enabling better depth reconstruction
and static/dynamic factorization than without (

Animating high-fidelity **video portrait with speech audio is crucial for virtual reality and digital entertainment. While most previous studies rely on accurate explicit structural information, recent works explore the implicit scene representation of Neural Radiance Fields (NeRF) for realistic generation.
https://ai.googleblog.com/2023/06/reconstructing-indoor-spaces-with-nerf.html
