sync #10
Merged
sync #10
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
… returning null on decimal overflow ### What changes were proposed in this pull request? JIRA SPARK-28067: Wrong results are returned for aggregate sum with decimals with whole stage codegen enabled **Repro:** WholeStage enabled enabled -> Wrong results WholeStage disabled -> Returns exception Decimal precision 39 exceeds max precision 38 **Issues:** 1. Wrong results are returned which is bad 2. Inconsistency between whole stage enabled and disabled. **Cause:** Sum does not take care of possibility of overflow for the intermediate steps. ie the updateExpressions and mergeExpressions. This PR makes the following changes: - Add changes to check if overflow occurs for decimal in aggregate Sum and if there is an overflow, it will return null for the Sum operation when spark.sql.ansi.enabled is false. - When spark.sql.ansi.enabled is true, then the sum operation will return an exception if an overflow occurs for the decimal operation in Sum. - This is keeping it consistent with the behavior defined in spark.sql.ansi.enabled property **Before the fix: Scenario 1:** - WRONG RESULTS ``` scala> val df = Seq( | (BigDecimal("10000000000000000000"), 1), | (BigDecimal("10000000000000000000"), 1), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2)).toDF("decNum", "intNum") df: org.apache.spark.sql.DataFrame = [decNum: decimal(38,18), intNum: int] scala> val df2 = df.withColumnRenamed("decNum", "decNum2").join(df, "intNum").agg(sum("decNum")) df2: org.apache.spark.sql.DataFrame = [sum(decNum): decimal(38,18)] scala> df2.show(40,false) +---------------------------------------+ |sum(decNum) | +---------------------------------------+ |20000000000000000000.000000000000000000| +---------------------------------------+ ``` -- **Before fix: Scenario2: Setting spark.sql.ansi.enabled to true** - WRONG RESULTS ``` scala> spark.conf.set("spark.sql.ansi.enabled", "true") scala> val df = Seq( | (BigDecimal("10000000000000000000"), 1), | (BigDecimal("10000000000000000000"), 1), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2)).toDF("decNum", "intNum") df: org.apache.spark.sql.DataFrame = [decNum: decimal(38,18), intNum: int] scala> val df2 = df.withColumnRenamed("decNum", "decNum2").join(df, "intNum").agg(sum("decNum")) df2: org.apache.spark.sql.DataFrame = [sum(decNum): decimal(38,18)] scala> df2.show(40,false) +---------------------------------------+ |sum(decNum) | +---------------------------------------+ |20000000000000000000.000000000000000000| +---------------------------------------+ ``` **After the fix: Scenario1:** ``` scala> val df = Seq( | (BigDecimal("10000000000000000000"), 1), | (BigDecimal("10000000000000000000"), 1), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2)).toDF("decNum", "intNum") df: org.apache.spark.sql.DataFrame = [decNum: decimal(38,18), intNum: int] scala> val df2 = df.withColumnRenamed("decNum", "decNum2").join(df, "intNum").agg(sum("decNum")) df2: org.apache.spark.sql.DataFrame = [sum(decNum): decimal(38,18)] scala> df2.show(40,false) +-----------+ |sum(decNum)| +-----------+ |null | +-----------+ ``` **After fix: Scenario2: Setting the spark.sql.ansi.enabled to true:** ``` scala> spark.conf.set("spark.sql.ansi.enabled", "true") scala> val df = Seq( | (BigDecimal("10000000000000000000"), 1), | (BigDecimal("10000000000000000000"), 1), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2), | (BigDecimal("10000000000000000000"), 2)).toDF("decNum", "intNum") df: org.apache.spark.sql.DataFrame = [decNum: decimal(38,18), intNum: int] scala> val df2 = df.withColumnRenamed("decNum", "decNum2").join(df, "intNum").agg(sum("decNum")) df2: org.apache.spark.sql.DataFrame = [sum(decNum): decimal(38,18)] scala> df2.show(40,false) 20/02/18 10:57:43 ERROR Executor: Exception in task 5.0 in stage 4.0 (TID 30) java.lang.ArithmeticException: Decimal(expanded,100000000000000000000.000000000000000000,39,18}) cannot be represented as Decimal(38, 18). ``` ### Why are the changes needed? The changes are needed in order to fix the wrong results that are returned for decimal aggregate sum. ### Does this PR introduce any user-facing change? User would see wrong results on aggregate sum that involved decimal overflow prior to this change, but now the user will see null. But if user enables the spark.sql.ansi.enabled flag to true, then the user will see an exception and not incorrect results. ### How was this patch tested? New test has been added and existing tests for sql, catalyst and hive suites were run ok. Closes #27627 from skambha/decaggfixwrongresults. Lead-authored-by: Sunitha Kambhampati <skambha@us.ibm.com> Co-authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…down ### What changes were proposed in this pull request? 1. Modified `ParquetFilters.valueCanMakeFilterOn()` to accept filters with `java.time.Instant` attributes. 2. Added `ParquetFilters.timestampToMicros()` to support both types `java.sql.Timestamp` and `java.time.Instant` in conversions to microseconds. 3. Re-used `timestampToMicros` in constructing of Parquet filters. ### Why are the changes needed? To support pushed down filters with `java.time.Instant` attributes. Before the changes, date filters are not pushed down to Parquet datasource when `spark.sql.datetime.java8API.enabled` is `true`. ### Does this PR introduce any user-facing change? No ### How was this patch tested? Modified tests to `ParquetFilterSuite` to check the case when Java 8 API is enabled. Closes #28696 from MaxGekk/support-instant-parquet-filters. Authored-by: Max Gekk <max.gekk@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
### What changes were proposed in this pull request? We should use dataType.catalogString to unified the data type mismatch message. Before: ```sql spark-sql> create table SPARK_31834(a int) using parquet; spark-sql> insert into SPARK_31834 select '1'; Error in query: Cannot write incompatible data to table '`default`.`spark_31834`': - Cannot safely cast 'a': StringType to IntegerType; ``` After: ```sql spark-sql> create table SPARK_31834(a int) using parquet; spark-sql> insert into SPARK_31834 select '1'; Error in query: Cannot write incompatible data to table '`default`.`spark_31834`': - Cannot safely cast 'a': string to int; ``` ### How was this patch tested? UT. Closes #28654 from lipzhu/SPARK-31834. Authored-by: lipzhu <lipzhu@ebay.com> Signed-off-by: HyukjinKwon <gurwls223@apache.org>
### What changes were proposed in this pull request? This PR upgrades HtmlUnit. Selenium and Jetty also upgraded because of dependency. ### Why are the changes needed? Recently, a security issue which affects HtmlUnit is reported. https://nvd.nist.gov/vuln/detail/CVE-2020-5529 According to the report, arbitrary code can be run by malicious users. HtmlUnit is used for test so the impact might not be large but it's better to upgrade it just in case. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Existing testcases. Closes #28585 from sarutak/upgrade-htmlunit. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: Sean Owen <srowen@gmail.com>
### What changes were proposed in this pull request? Only push the release tag after the build has finished. ### Why are the changes needed? If the build fails we don't need a release tag. ### Does this PR introduce _any_ user-facing change? No ### How was this patch tested? Running locally with a fake user in #28667 Closes #28700 from holdenk/SPARK-31860-build-master-only-push-tags-on-success. Authored-by: Holden Karau <hkarau@apple.com> Signed-off-by: Holden Karau <hkarau@apple.com>
### What changes were proposed in this pull request? Add cross build support to our docker image script using the new dockerx extension. ### Why are the changes needed? We have a CI for Spark on ARM, we should support building images for ARM and AMD64. ### Does this PR introduce _any_ user-facing change? Yes, a new flag is added to the docker image build script to cross-build ### How was this patch tested? Manually ran build script & pushed to https://hub.docker.com/repository/registry-1.docker.io/holdenk/spark/tags?page=1 verified amd64 & arm64 listed. Closes #28615 from holdenk/cross-build. Lead-authored-by: Holden Karau <hkarau@apple.com> Co-authored-by: Holden Karau <holden@pigscanfly.ca> Signed-off-by: Holden Karau <hkarau@apple.com>
### What changes were proposed in this pull request? SQL Rest API exposes query execution details and metrics as Public API. Its documentation will be useful for the end-users. ### Why are the changes needed? SQL Rest API does not exist under Spark Rest API. ### Does this PR introduce any user-facing change? No ### How was this patch tested? Manually build and check Closes #28354 from erenavsarogullari/SPARK-31566. Lead-authored-by: Eren Avsarogullari <eren.avsarogullari@gmail.com> Co-authored-by: Gengliang Wang <gengliang.wang@databricks.com> Co-authored-by: Eren Avsarogullari <erenavsarogullari@gmail.com> Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
### What changes were proposed in this pull request? This PR aims to upgrade to Zstd 1.4.5. ### Why are the changes needed? Zstd 1.4.5 improves performance. https://github.com/facebook/zstd/releases/tag/v1.4.5 ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Passed the Jenkins. Closes #28682 from williamhyun/zstd. Authored-by: William Hyun <williamhyun3@gmail.com> Signed-off-by: DB Tsai <d_tsai@apple.com>
### What changes were proposed in this pull request? This PR fix an issue related to DAG-viz. Because DAG-viz for a job fetches link urls for each stage from the stage table, rendering can fail with pagination. You can reproduce this issue with the following operation. ``` sc.parallelize(1 to 10).map(value => (value ,value)).repartition(1).repartition(1).repartition(1).reduceByKey(_ + _).collect ``` And then, visit the corresponding job page. There are 5 stages so show <5 stages in the paged table. <img width="1440" alt="dag-rendering-issue1" src="https://user-images.githubusercontent.com/4736016/83376286-c29f3d00-a40c-11ea-891b-eb8f42afbb27.png"> <img width="1439" alt="dag-rendering-issue2" src="https://user-images.githubusercontent.com/4736016/83376288-c3d06a00-a40c-11ea-8bb2-38542e5010c1.png"> ### Why are the changes needed? This is a bug. ### Does this PR introduce _any_ user-facing change? No. ### How was this patch tested? Newly added test case with following command. `build/sbt -Dtest.default.exclude.tags= -Dspark.test.webdriver.chrome.driver=/path/to/chromedriver "testOnly org.apache.spark.ui.ChromeUISeleniumSuite -- -z SPARK-31882"` Closes #28690 from sarutak/fix-dag-rendering-issue. Authored-by: Kousuke Saruta <sarutak@oss.nttdata.com> Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
{kind=link}
{kind=link}
…ed dataframes ### What changes were proposed in this pull request? With this pull request I want to improve the Web UI / SQL tab visualization. The principal problem that I find is when you have a cache in your plan, the SQL visualization don’t show any information about the part of the plan that has been cached. Before the change 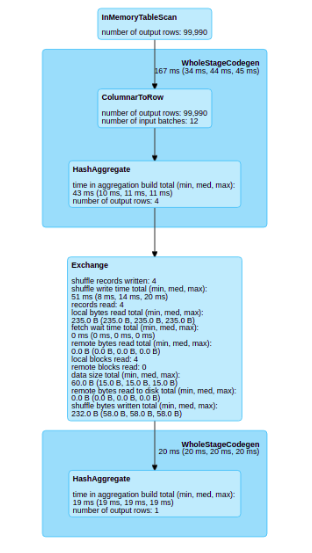 After the change  ### Why are the changes needed? When we have a SQL plan with cached dataframes we lose the graphical information of this dataframe in the sql tab ### Does this PR introduce any user-facing change? Yes, in the sql tab ### How was this patch tested? Unit testing and manual tests throught spark shell Closes #26082 from planga82/feature/SPARK-29431_SQL_Cache_webUI. Lead-authored-by: Pablo Langa <soypab@gmail.com> Co-authored-by: Gengliang Wang <gengliang.wang@databricks.com> Co-authored-by: Unknown <soypab@gmail.com> Signed-off-by: Gengliang Wang <gengliang.wang@databricks.com>
{kind=link}
{kind=link}
…ase to be consistent with Scala side
### What changes were proposed in this pull request?
Scala:
```scala
scala> spark.range(10).explain("cost")
```
```
== Optimized Logical Plan ==
Range (0, 10, step=1, splits=Some(12)), Statistics(sizeInBytes=80.0 B)
== Physical Plan ==
*(1) Range (0, 10, step=1, splits=12)
```
PySpark:
```python
>>> spark.range(10).explain("cost")
```
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/.../spark/python/pyspark/sql/dataframe.py", line 333, in explain
raise TypeError(err_msg)
TypeError: extended (optional) should be provided as bool, got <class 'str'>
```
In addition, it is consistent with other codes too, for example, `DataFrame.sample` also can support `DataFrame.sample(1.0)` and `DataFrame.sample(False)`.
### Why are the changes needed?
To provide the consistent API support across APIs.
### Does this PR introduce _any_ user-facing change?
Nope, it's only changes in unreleased branches.
If this lands to master only, yes, users will be able to set `mode` as `df.explain("...")` in Spark 3.1.
After this PR:
```python
>>> spark.range(10).explain("cost")
```
```
== Optimized Logical Plan ==
Range (0, 10, step=1, splits=Some(12)), Statistics(sizeInBytes=80.0 B)
== Physical Plan ==
*(1) Range (0, 10, step=1, splits=12)
```
### How was this patch tested?
Unittest was added and manually tested as well to make sure:
```python
spark.range(10).explain(True)
spark.range(10).explain(False)
spark.range(10).explain("cost")
spark.range(10).explain(extended="cost")
spark.range(10).explain(mode="cost")
spark.range(10).explain()
spark.range(10).explain(True, "cost")
spark.range(10).explain(1.0)
```
Closes #28711 from HyukjinKwon/SPARK-31895.
Authored-by: HyukjinKwon <gurwls223@apache.org>
Signed-off-by: HyukjinKwon <gurwls223@apache.org>
This reverts commit e5c3463.
# What changes were proposed in this pull request?
This PR switches the default Locale from the `US` to `GB` to change the behavior of the first day of the week from Sunday-started to Monday-started as same as v2.4
### Why are the changes needed?
#### cases
```sql
spark-sql> select to_timestamp('2020-1-1', 'YYYY-w-u');
2019-12-29 00:00:00
spark-sql> set spark.sql.legacy.timeParserPolicy=legacy;
spark.sql.legacy.timeParserPolicy legacy
spark-sql> select to_timestamp('2020-1-1', 'YYYY-w-u');
2019-12-30 00:00:00
```
#### reasons
These week-based fields need Locale to express their semantics, the first day of the week varies from country to country.
From the Java doc of WeekFields
```java
/**
* Gets the first day-of-week.
* <p>
* The first day-of-week varies by culture.
* For example, the US uses Sunday, while France and the ISO-8601 standard use Monday.
* This method returns the first day using the standard {code DayOfWeek} enum.
*
* return the first day-of-week, not null
*/
public DayOfWeek getFirstDayOfWeek() {
return firstDayOfWeek;
}
```
But for the SimpleDateFormat, the day-of-week is not localized
```
u Day number of week (1 = Monday, ..., 7 = Sunday) Number 1
```
Currently, the default locale we use is the US, so the result moved a day backward.
For other countries, please refer to [First Day of the Week in Different Countries](http://chartsbin.com/view/41671)
With this change, it restores the first day of week calculating for functions when using the default locale.
### Does this PR introduce _any_ user-facing change?
Yes, but the behavior change is used to restore the old one of v2.4
### How was this patch tested?
add unit tests
Closes #28692 from yaooqinn/SPARK-31879.
Authored-by: Kent Yao <yaooqinn@hotmail.com>
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
sync