ROS 2 Type Adaptation Definition.
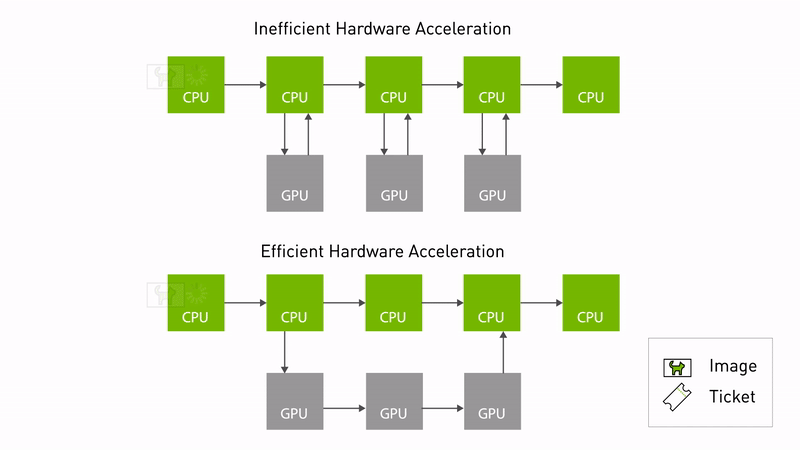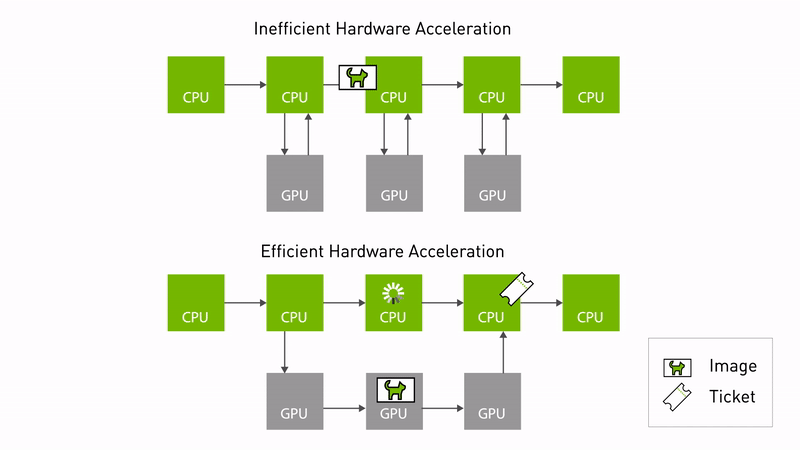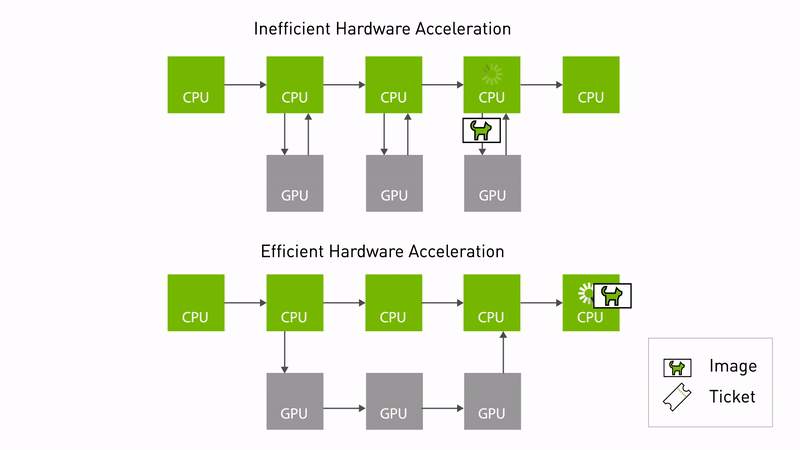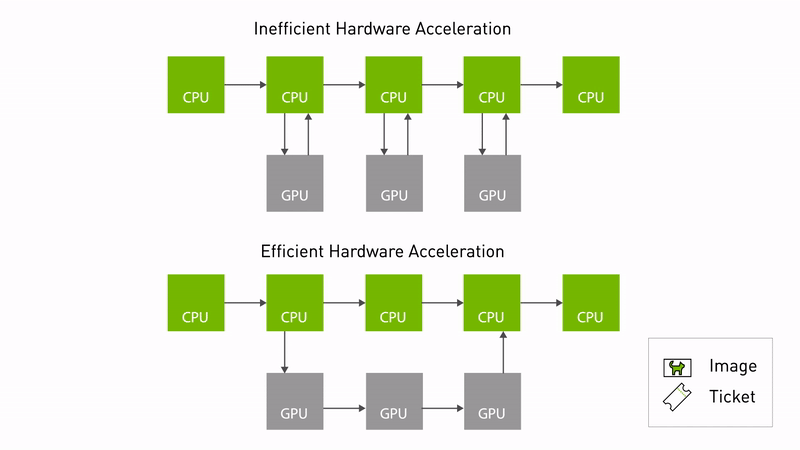
The Autoware CUDA Type Adapters is a high-performance library designed to optimize image/pointcloud processing pipelines in ROS 2, particularly for autonomous driving systems using NVIDIA hardware. This library implements ROS 2 Type Adaptation to minimize CPU-GPU data transfer overhead and enable zero-copy operations where possible.
Key Features:
- Seamless integration with ROS 2 and CUDA-enabled devices
- Compatible with both Jetson hardware and standard NVIDIA GPUs
- No performance degradation when used without full-pipeline optimization
- Streamlined image processing for reduced latency in real-time applications
Illustration gif from nvidia docs:
- ROS 2 (Tested on Humble)
- CUDA-enabled devices (Jetson platforms and standard NVIDIA GPUs)
In your CMakeLists.txt:
find_package(autoware_type_adapters REQUIRED)
ament_target_dependencies(your_node autoware_type_adapters)In your package.xml:
<depend>autoware_type_adapters</depend>In your C++ code:
#include "type_adapters/image_container.hpp"
using ImageContainer = autoware::type_adaptation::type_adapters::ImageContainer;
using ImageContainerUniquePtr = autoware::type_adaptation::type_adapters::ImageContainer;// In your node's header file
rclcpp::Subscription<ImageContainer>::SharedPtr gpu_image_sub_;
rclcpp::Publisher<ImageContainer>::SharedPtr gpu_image_pub_;
// In your node's implementation
gpu_image_sub_ = this->create_subscription<ImageContainer>(
"input_image", 10, std::bind(&YourNode::imageCallback, this, std::placeholders::_1));
gpu_image_pub_ = this->create_publisher<ImageContainer>("output_image", 10);
void YourNode::imageCallback(const std::shared_ptr<ImageContainer> msg)
{
// Process the image using CUDA
// ...
// Publish the processed image
gpu_image_pub_->publish(*processed_image);
}void YourNode::processImage(const ImageContainer& msg)
{
// Get CUDA memory pointer
uint8_t* cuda_ptr = msg.cuda_mem();
// Get CUDA stream
cudaStream_t stream = msg.cuda_stream()->stream();
// Use these in your CUDA kernels or NPP functions
// ...
}- The CUDA Image Container is designed to work efficiently even without full-pipeline optimization. You can expect no performance degradation when using it in parts of your system.
- For best performance, use the CUDA stream provided by the Image Container for all GPU operations within a processing node.
- The CUDA memory for image data is tightly packed without padding. If your CUDA/NPP libraries require padded 2D image data, manage the alignment manually.
This project was inspired by the work done in the NVIDIA Isaac ROS project and adapted for broader use in the Autoware community.