Tools
This chapter introduces the most frequently used LUCIS-OPEN tools in models. The following tools are:

The tool is used to calculate weights of important criteria for decision making. In the Analytic Hierarchy Process (AHP), we arrange these factors, once selected, in a hierarchic structure descending from an overall goal to criteria, subcriteria and alternatives in successive levels. The tool serves two purposes: it provides an overall view of the complex relationships inherent in the situation; and helps the decision maker assess whether the issues in each level are of the same order of magnitude, so he can compare such homogeneous elements accurately. The AHP is rigorously concerned with the scaling problem and what sort of numbers to use, and how to correctly combine the priorities resulting from them.
-
Weights generating options:
Weights generating options Description Defined AHP weights Use this option if the relationships between each criteria can be measured by certain scales. Random AHP wights Use this option if the relationships between each criteria are unclear. -
List of criteria to weight: Input all criteria involved in decision making. The maximum number of criteria in this tool is 10.
-
Comparison table for creating the reciprocal matrix (optional): The table is used to compare each criteria in scales. The scale to use in making the judgments is given in table that you can use values from 1 (equally important) to 9 (extremely important).
Intensity of importance Definition Explanation 1 Equal importance Two activities contribute equally to the objective 3 Moderate importance of one over another Experience and judgement strongly favor one activity over another 5 Essential or strong importance Experience and judgement strongly favor one activity over another 7 Very strong importance An activity is strongly favored and its dominance demonstrated in practice 9 Extreme importance The evidence favoring one activity over another is of the highest possible order of affirmation 2,4,6,8 Intermediate values between the two adjacent judgments When compromise is needed Reciprocals If activity i has one of the above numbers assigned to it when compared with activity j, then j has the reciprocal value when compared with i. For example, if criteria 1 (row id) is 3 times important than criteria 2 (column id), criteria 1 is 9 times important than criteria 3, and criteria 2 is 1/3 times important than criteria 3, the comparison table can be created as follows:
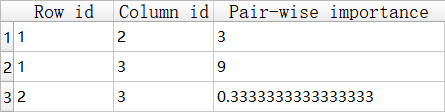
💡 How to understand the comparison table
Usually, AHP elicits pairwise comparison judgments by comparing criteria one by one in a matrix. In this tool, we only compare different criteria once. It means that we only input the value in the upper diagonal part of matrix.In this tool, the value of pair-wise importance must be float. When the value is fractions (i.e., 1/3, 1/6, 1/7, and 1/9) whose calculation result is a repeating decimal. You should put the following float value into the comparison table.

The results of the comparisons table will be entered into a matrix which is processed mathematically to derive the priorities for all criteria.
-
HTML report: Output HTML report presents the porioriteis for all criteria. The consistency index (CI) in here is compared with the same index obtained as an average over a large number of reciprocal matrices of the same order whose entries are random. If the consistency ratio of CI to that from random matrices is significantly small (carefully specified to be about 10% or less), we accept the estimate. Otherwise, we attempt to improve consistency.
Calculate density of line features within the specified search radius of each input polygon features.
- Input layer: Input vector layer.
- Line layer: Input line layer.
- Cell size for rasterizing line features (optional): The size of cells, to which the line features are rasterized. The smaller the value, the more precise the outcome, but the longer time will be taken to run the tool.
- Search radius (optional): The search radius created around the polygons to calculate the density. The default set is 0, which means the calculating area is the area of each polygon feature. Units need to be specified.
- Areal unit: The desired area units of the output density values.
- Output column name: Name of the column storing distances in the output layer.
- Output: Output vector layer.
Calculate density of point features within the specified search radius of each input polygon features.
- Input layer: Input vector layer.
- Point layer: Input point layer.
- Population field (optional): Field denoting population values for each point. The population field is the count or quantity to be used in the calculation of a continuous surface.
- Search radius (optional): The search radius created around the polygons to calculate the density. The default set is 0, which means the calculating area is the area of each polygon feature. Units need to be specified.
- Areal unit: The desired area units of the output density values.
- Output column name: Name of the column storing distances in the output layer.
- Output: Output vector layer.
Calculate distance for each feature in the input data to its nearest neighbor in the line layer.
- Input layer: Input vector layer.
- Line layer: Input line layer.
- Cell size for rasterizing line features (optional): The size of cells, to which the line features are rasterized. The smaller the value, the more precise the outcome, but the longer time will be taken to run the tool.
- Distance method: Choose between Euclidean Distance or Manhattan Distance.
- Output data type (optional): Choose between integer or float(default) output value.
- Output column name: Name of the column storing distances in the output layer.
- Output: Output vector layer.
Calculate distance for each feature in the input data to its nearest neighbor in the point dataset.
- Input layer: Input vector layer.
- Point layer: Input point layer.
- Distance method: Choose between Euclidean Distance or Manhattan Distance.
- Output data type (optional): Choose between integer or float(default) output value.
- Output column name: Name of the column storing distances in the output layer.
- Output Output vector layer.
Calculate distance for each feature in the input data to its nearest cell with the specified value in the raster layer. You must make sure that the specified value is valid, i.e., it exists in the raster layer.
- Input: Input vector layer.
- Raster: Input raster layer.
- Cell value: The value of cells, to which distances are calculated.
- No data (optional): Value should be considered as "no data" in the raster layer.
- Distance method: Choose between Euclidean Distance or Manhattan Distance.
- Output data format (optional): Choose between integer or float (default) output value.
- Output column name: Name of the column storing distances in the output layer.
- Output: Output vector layer
Erase the part in input layer that overlaps with the erase layer.
- Input layer: Input vector layer.
- Erase layer: The features to be used to erase coincident features in the input.
- Output: Output vector layer.
This function implements an IDW interpolation. The power parameter dictates how fast the influence to a given location by its nearby objects decays. idw_cv, a k-fold cross validation method is offered to determine the most appropriate value of the power parameter.
- Input layer: Input vector layer, to which will be assigned the interpolated value.
- Interpolation layer: The input features containing the values to be interpolated.
- Power parameter for interpolation (optional): The exponent of distance. This controls the significance of surrounding points on the interpolated value. A higher power results in less influence from distant points. It can be any real number greater than 0, but the most reasonable results will be obtained using values from 0.5 to 3. The default is 2.
- Number of neighbors (optional): An integer value specifying the number of nearest input sample points to be used to perform interpolation. The default is 12points.
- Search radius (optional): Maximum distance used to find neighbors. If not provided, the function will search for all neighbors specified by Number ofNeighbors.
- Output data type (optional): Choose between integer or float (default) output value.
- Output field name: Name of the column storing distances in the output layer.
- Output layer: Output vector layer.
Reclassify a field in the input table based on predefined rules and store the translated values in a new field.
- Input layer:Input vector layer.
- Field to reclassify:Transform specific values or ranges of values in a field to specified classes, i.e. reclassifying values 5 as 100 or values 1 to 5 as 100.
- Old values:Old values could be specific values or ranges of values. Specific values or ranges of values should be separated by comma, i.e., for specific values: 1, 2, for ranges of values: 1-5, 5-10. If two ranges are specified, such as 1 to 5 equal to 100 and 5 to 10 equal to 200, the value 5 will usually be assigned to the value 100 and 5.01 will be assigned to 200 as output values.
- New values:New values should correspond to Old specific values or Old ranges of values.
- No data value (optional): If any value in fields cannot be covered by defined Old values, those value will be given a new value. The default value is 1.
- Output column name: Name of the column storing reclassified new values
- Output layer: Output vector layer.
Rescale values in a field into a new bound.
- Input layer: Input vector layer.
- Field to rescale: Transform values in a field to a specified continuous scale, i.e., on a 1 to 9 scale
- Start/End value for rescaling (optional): If Start is less than end, the rescaling is in the same direction as values in the input field, i.e., smaller (bigger) values in the input field correspond to smaller (bigger) values in the output.If argument Start is greater than end, the rescaling is in the reverse direction as values in the input field, i.e., smaller (bigger) values in the input field correspond to bigger (smaller) values in the output.
- New minimum/maximum (optional): Values beyond the specified bound will be assigned to Output minimum and Output maximum, depending on which side they are on, i.e., when start value is less than end, values smaller than start value will be recorded as Output minimum.
- Output field name: Name the rescaled field in Input table.
- Output layer: Output vector layer.
Select part of the input Layer based on its spatial relationship with the selecting layer.
-
Input layer: The features that will be evaluated against the Selection features parameter. The selection will be applied to these Input features.
-
Selection layer: The features in the Input layer will be selected based on their relationship to the features from this layer.
-
Join option (geometric predicate): Defines the criteria used to match rows. The match options are:
Join option Description Intersect The features in the Selection features will be matched if they intersect a Input feature. This is the default option. Contains The features in the Selection features will be matched if a Input feature contains them. For this option, the Input features cannot be points, and the Input features can only be polygons when the Selection features are also polygons. Within The features in the Selection features will be matched if a Input feature is within them. It is opposite to Contains. For this option, the Selection features can only be polygons when the Input features are also polygons. Point can be a Selection feature only if point a is Input feature. -
Within a distance from selection features: The distance used to search for input features around any selection features.
-
Output layer: Output vector layer.
Join attributes from the join features to the target features based on specified spatial relationship.
-
Target layer: Attributes of the target features and the attributes from the joined features are transferred to the output feature class. However, a subset of attributes can be defined in the field map parameter.
-
Join layer: The attributes from the join features are joined to the attributes of the target features.
-
Join option: Defines the criteria used to match rows. The match options are:
Join option Description Intersect The features in the Selection features will be matched if they intersect a Input feature. This is the default option. Contains The features in the join features will be matched if a target feature contains them. The target features must be polygons or polylines. For this option, the target features cannot be points, and the join features can only be polygons when the target features are also polygons. Within The features in the join features will be matched if a target feature is within them. It is opposite to Contains. For this option, the target features can only be polygons when the join features are also polygons. Point can be join feature only if point is target. -
Columns to join: A new feature class containing the attributes of join features, i.e.,"<clm_name> " e.g., "bldg_value sum". The types of function defaults to ['first'], other valid functions are ['last', 'sum', 'mean', 'median', 'max', 'min','std', 'var', 'count', 'size'].
Function Description First Use the columns' first value. Last Use the columns' last value. Sum Calculate the total of the columns' values. Mean Calculate the mean (average) of the columns' values. Median Calculate the median (middle) of the columns' values. Min Use the minimum value of all columns' values. Max Use the maximum value of all columns' values. Std (Standard deviation) Use the standard deviation classification method on all columns' values. Var (Variance) Calculates the variance for all records of the specified field. Count Find the number of records included in the calculation. -
Join type: Determines how joins between the target features and join features will be handled in the output feature class if multiple join features are found that have the same spatial relationship with a single target feature.
Join type Description Join one to one If multiple join features are found that have the same spatial relationship with a single target feature, the attributes from the multiple join features will be aggregated. For example, if a point target feature is found within two separate polygon join features, the attributes from the two polygons will be aggregated before being transferred to the output point feature class. If one polygon has an attribute value of 3 and the other has a value of 7, and a Sum merge rule is specified, the aggregated value in the output feature class will be 10. Join one to many If multiple join features are found that have the same spatial relationship with a single target feature, the output feature class will contain multiple copies (records) of the target feature. For example, if a single point target feature is found within two separate polygon join features, the output feature class will contain two copies of the target feature: one record with the attributes of one polygon, and another record with the attributes of the other polygon. -
Output shapefile: Output vector layer.
Calculate a weighted sum over a set of existing fields within the input layer.
- Input layer: Vector layer being weighted.
- Fields: The field to use for weighting. The number of fields (second parameter) must equal to the number of weights (third parameter).
- Weights: Weight value by which to multiply the fields. It can be any positive or negative decimal value. Weights should be separated by comma.
- Output field: Output vector layer.
Calculate statistics on values of raster within the zones of another dataset.
-
Input layer: Dataset that defines the zones and sets boundaries according to its geometries. The zones are only defined by a vector layer.
-
Raster layer: Raster that contains the values on which to calculate a statistic.
-
Types of statistics: Statistic type to be calculate. The types of statistics defaults to ['count', 'min', 'max', 'mean'].Other valid statistics are ['sum', 'std', 'median', 'majority','minority', 'unique', 'range'].
Function Description Count Count the number of cells have value, no data would not be counted. Min (Minimum) Determines the smallest value of all cells in the value raster that belong to the same zone as the output cell. Max (Maximum) Determines the largest value of all cells in the value raster that belong to the same zone as the output cell. Mean Calculates the average of all cells in the value raster that belong to the same zone as the output cell. Sum Calculates the total value of all cells in the value raster that belong to the same zone as the output cell. Std (Standard deviation) Calculates the standard deviation of all cells in the value raster that belong to the same zone as the output cell. Median Determines the median value of all cells in the value raster that belong to the same zone as the output cell. Majority Determines the value that occurs most often of all cells in the value raster that belong to the same zone as the output cell. Minority Determines the value that occurs least often of all cells in the value raster that belong to the same zone as the output cell. Unique Count the number of unique value in cells. Range Calculates the difference between the largest and smallest value of all cells in the value raster that belong to the same zone as the output cell. -
No data value (optional): Value should be considered as "no data" in the raster layer.
-
Output layer: Output vector layer.