

Unofficial implementation of the paper Data-Efficient Reinforcement Learning with Probabilistic Model Predictive Control with Pytorch and GPyTorch.
Trial-and-error based reinforcement learning (RL) has seen rapid advancements in recent times, especially with the advent of deep neural networks.
However, the majority of autonomous RL algorithms either rely on engineered features or a large number of interactions with the environment.
Such a large number of interactions may be impractical in many real-world applications.
For example, robots are subject to wear and tear and, hence, millions of interactions may change or damage the system.
Moreover, practical systems have limitations in the form of the maximum torque that can be safely applied.
To reduce the number of system interactions while naturally handling constraints, we propose a model-based RL framework based on Model Predictive Control (MPC).
In particular, we propose to learn a probabilistic transition model using Gaussian Processes (GPs) to incorporate model uncertainties into long-term predictions, thereby,
reducing the impact of model errors. We then use MPC to find a control sequence that minimises the expected long-term cost.
We provide theoretical guarantees for the first-order optimality in the GP-based transition models with deterministic approximate inference for long-term planning.
The proposed framework demonstrates superior data efficiency and learning rates compared to the current state of the art.
numpy, gym, pytorch, gpytorch, matplotlib, scikit-learn, ffmpeg
Download anaconda Open an anaconda prompt window:
git clone https://github.com/SimonRennotte/Data-Efficient-Reinforcement-Learning-with-Probabilistic-Model-Predictive-Control
cd Data-Efficient-Reinforcement-Learning-with-Probabilistic-Model-Predictive-Control
conda env create -f environment.yml
conda activate gp_rl_env
python examples/pendulum/run_pendulum.py
To apply the method on different gym environments, refer the to /examples folder. Note that the control_config object must be defined so that it works for the environment. Some parameters depend on the dimensionality of actions and observations.
In each experiment, two types of plots are available to observe and comprehend the control process:
-
2D Plots:
- The top graph displays the states, along with the predicted states and uncertainty from a specified number of previous time steps. The value of "n" is mentioned in the legend.
- The middle graph depicts the actions taken during control.
- The bottom graph illustrates the real cost alongside the predicted trajectory cost, which is the mean of future predicted costs, along with its associated uncertainty.
-
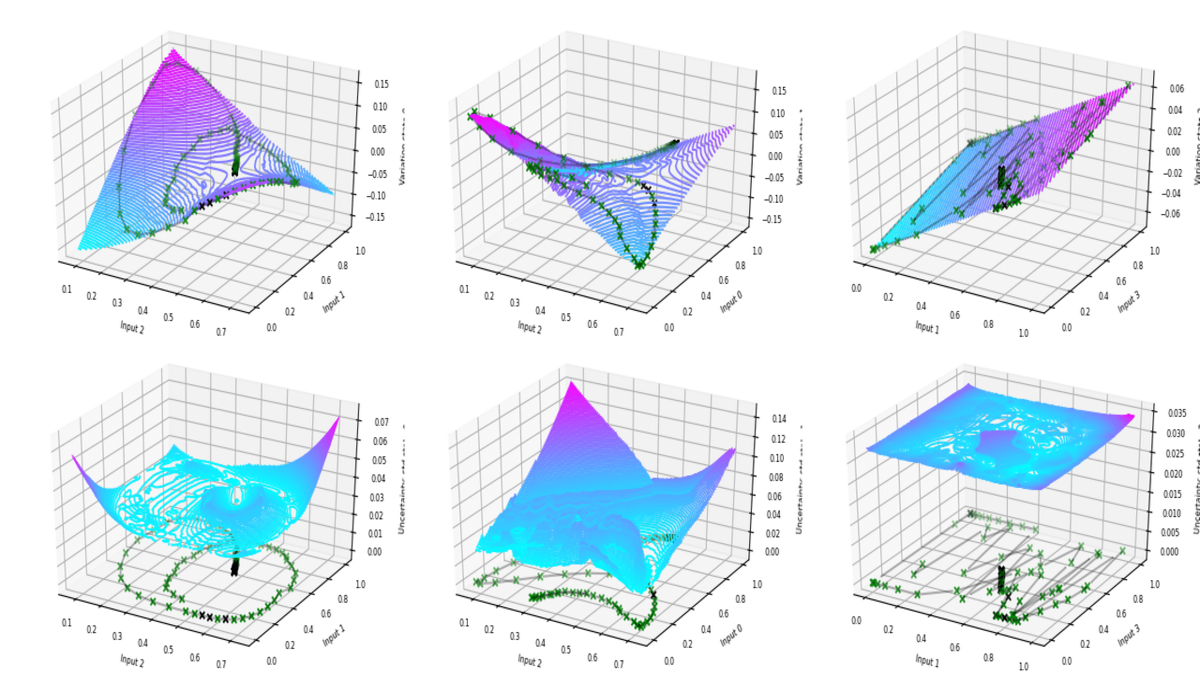
3D Plots:
- These plots showcase the Gaussian process models and the stored data points.
- Each graph in the top row represents the change in states for the next step based on the current states and actions.
- The indices on the x and y axes denote the states or actions being represented. For example, an index of 3 corresponds to the action for the pendulum. Actions have higher indices than states.
- Since it's not feasible to display every input of the Gaussian process on the 3D graph, the axes are chosen to represent the two inputs (state or action) with the smallest lengthscales. Hence, the x-y axes may differ for each graph.
- The graphs in the bottom row demonstrate the predicted uncertainty, while the data points represent prediction errors. Points stored in the memory of the Gaussian process model are depicted in green, while points that were not used for Gaussian process predictions due to their similarity to existing points in memory are shown in black.
During the control process, a dynamic graph, similar to the 2D plot described earlier, provides real-time visualization of the evolving states, actions, and costs. It also displays the predicted states, actions, and costs computed by the model for the Model Predictive Control (MPC). The predicted future states, actions, and costs are represented by dashed lines, accompanied by their confidence intervals (2 standard deviations).
The following figure shows the mean cost over 10 runs:

We can see that the model allows to control the environment in less than hundred interactions with the environment. As a comparison, the state of the art of model free reinforcement learning algorithms in https://github.com/quantumiracle/SOTA-RL-Algorithms solves the problem in more than 15 episodes of 200 interactions with the environment.
The following animation shows an example of control.
And the gaussian process models and points in memory:
The mountain car problem is different in that the number of time steps to plan in order to control the environment is higher. To avoid this problem, the parameter to repeat the actions has been set to 5. For the shown example, 1 control time step corresponds to 5 time steps where the action is held constant.
The mean costs over 10 runs can be seen in the following figure:

As for the pendulum, the optimal control is obtained in very few steps compared to the state of the art of model-free reinforcement agents


To assess control performance in the presence of noise, multiple actions, and time-varying parameters, a custom gym environment has been created. This environment simulates a straightforward process control scenario involving the regulation of a level and concentration within a tank.
For detailed information about the environment, please refer to the file located in the /envs/ folder.
The control is represented in the following animation:

The predicted future states can be accessed within the object during each control iteration. This means the future distribution can be used to set constraints on the states. In this case, the penalties have been added for states that fall outside an allowed region.
To illustrate control with constraints, an example is provided below using the mountain car scenario. The graph displays the permissible boundaries indicated by dotted lines.
The following constraints have been added:
- The car is not allowed to reach the top but must stay on the clif.
- The maximum speed of the car is limited
- The car can't go too much left

The control is reached with few violations of the constraints while still optimizing the cost function.
By changing the way that the optimized actions are defined, it is possible to limit the changes of actions.
The following animation represents an example of this functionality for the process control environment.

In the previous examples, the model assumed a static environment without any changes over time.
However, by introducing an extra input to the model that represents the iteration time, we can assign more significance to recent data points. This enables the model to adapt to changes in the environment as time progresses.
The learned time lengthscale provides insight into the pace at which the environment evolves.
To illustrate this functionality, an animation is presented for the process control environment. In this animation, the parameters changes every 200 timesteps.

The approach uses a model to control the environment. This family of methods is called Model Predictive Control (MPC). At each interaction with the real environment, the optimal action is obtained through an iterative approach. The model is used to evaluate certain actions over a fixed time horizon by simulating the environment. This simulation is used several times with different actions at each interaction with the real world to find the optimal actions in the time horizon window. The first control of the time horizon is then used for the next action in the real world. In traditional control theory, the model is a mathematical model obtained from expert knowledge. Here, the model is a Gaussian process that learns from observed data.
Gaussian processes are used to predict the change of states as a function of states and actions. The predictions are a multidimensional gaussian distribution, which allows to get the uncertainty of these predictions. Gaussian processes are defined by a mean and covariance function, and store previous points (states(t), actions(t), (states(t+1) - states(t))) in memory. To compute new predictions, the covariance between the new points and the points stored in memory is calculated, which allows, with a little mathematics, to get the predicted distribution. Conceptually, Gaussian processes can be seen as if they were looking at adjacent points in memory to compute predictions at new points. Depending on the distance between the new point and the points stored in memory, the uncertainty will be greater or smaller. In our case, for each state, one Gaussian process is used which has n (number of states) + m (number of actions) inputs, and 1 output used to predict the variation of that state.
In this paper, the uncertainties propagate during trajectory calculations which allows to calculate the uncertainty of the loss in the window of the simulation horizon. This makes it possible to explore more efficiently by rewarding future states where the uncertainty of the loss is high. It can also be used to get a real-time idea of the model's certainty about the future. Uncertainty can also be used to impose security constraints. This can be done by prohibiting visits to states where the uncertainty is too high by imposing constraints on the lower or upper limit of the state confidence interval. This method is already used for safe Bayesian optimization. For example, it has been used to optimize UAV controllers to avoid crashes during optimization.
This approach allows learning fast enough to enable online learning from scratch, which opens up many possibilities for Reinforcement Learning in new applications with some more research.
Currently, real-world applications of model-free reinforcement learning algorithms are limited due to the number of interactions they require with the environment.
This method shows that for the applications on which it can be used, the same results as for state-of-the-art model-free algorithms (to the extent of my knowledge) can be obtained with approximately 20 times less interaction with the environment.
Understanding the reasons of this increased efficiency would open the search for algorithms with the same improvement in sample efficiency but without the limitations of this method.
For example, the future predicted rewards (or cost) are predicted as a distribution. By maximizing the upper confidence bound of future rewards, future states with high reward uncertainty are encouraged, allowing for effective exploration.
Maximizing future state uncertainty could also be used to explore environments without rewards.
If future research removes the limitations of this method, this type of data efficiency could be used for real world applications where real-time learning is required and thus open many new applications for reinforcement learning.
Compared to the implementation in the paper, the scripts have been designed to perform the control over a long time without any reset, which means :
- The optimized function in the MPC is the lower confidence bound of the expected long-term cost to reward exploration and avoid getting stuck in a local minimum.
- The environment is not reset, learning is done in one go. Thus, the hyper-parameters training can not be done between trials. The learning of the hyperparameters and the storage of the visualizations are performed in a parallel process at regular time intervals in order to minimize the computation time at each control iteration.
- The optimizer for actions is LBFGS
- An option has been added to decide to include a point in the model memory depending on the prediction error at that point and the predicted uncertainty to avoid having too many points in memory. Only points with a predicted uncertainty or a prediction error greater than a threshold are stored in memory.
- An option has been added to allow to include the time of observation to the gaussian process models. This can be useful when the environment changes over time, as the model will learn to rely on more recent points vs older points in memory.
- The cost function must be clearly defined as a squared distance function of the states and actions from a reference point.
- The length of the prediction horizon of the mpc will impact computation times. This can be a problem when the dimensionality of the observation space and/or action space is also high.
- The dimension of the input and output of the gaussian process must stay low, which limits application to cases with low dimensionality of the states and actions.
- If too much points are stored in the memory of the gaussian process, the computation times might become too high per iteration.
- The current implementation will not work for gym environments with discrete states or actions.
- No guarantee is given for the time per iteration.
- Actions must have an effect on the observation of the next observed step. Delays are not supported in the model. Observation must unequivocally describe the system states.
Gaussian processes: https://www.youtube.com/watch?v=92-98SYOdlY&list=PL93aLKqThq4hbACqDja5QFuFKDcNtkPXz&index=2
Presentation of PILCO by Marc Deisenroth: https://www.youtube.com/watch?v=AVdx2hbcsfI (method that uses the same gaussian process model, but without a MPC controller)
Safe Bayesian optimization: https://www.youtube.com/watch?v=sMfPRLtrob4
Original paper: https://deepai.org/publication/data-efficient-reinforcement-learning-with-probabilistic-model-predictive-control
PILCO paper that describes the moment matching approximation used for states uncertainty propagation: https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=6654139
Marc Deisenroth thesis: https://deisenroth.cc/pdf/thesis.pdf
http://www.gaussianprocess.org/gpml/
https://github.com/nrontsis/PILCO
You can contact me on Linkedin: https://www.linkedin.com/in/simon-rennotte-96aa04169/ or by email: simon.rennotte@protonmail.com