Audio/video medias and streams deep analyzer in Java with FFmpeg as back-end: extract/process technical information from audio/videos files/streams.
This application is currently in beta version, and should be ready for production.
🚩 About
🏪 Features
⚡ Getting started
🛫 Examples
📕 Documentation, contributing and support
🌹 Acknowledgments
![]()
![]()
This application will run FFmpeg on a source video/audio file to apply some filters, and generate analysis raw data (mostly high verbosely text/XML streams). They are parsed and reduced/converted/drawn/summarized them to some output formats by Mediadeepa.
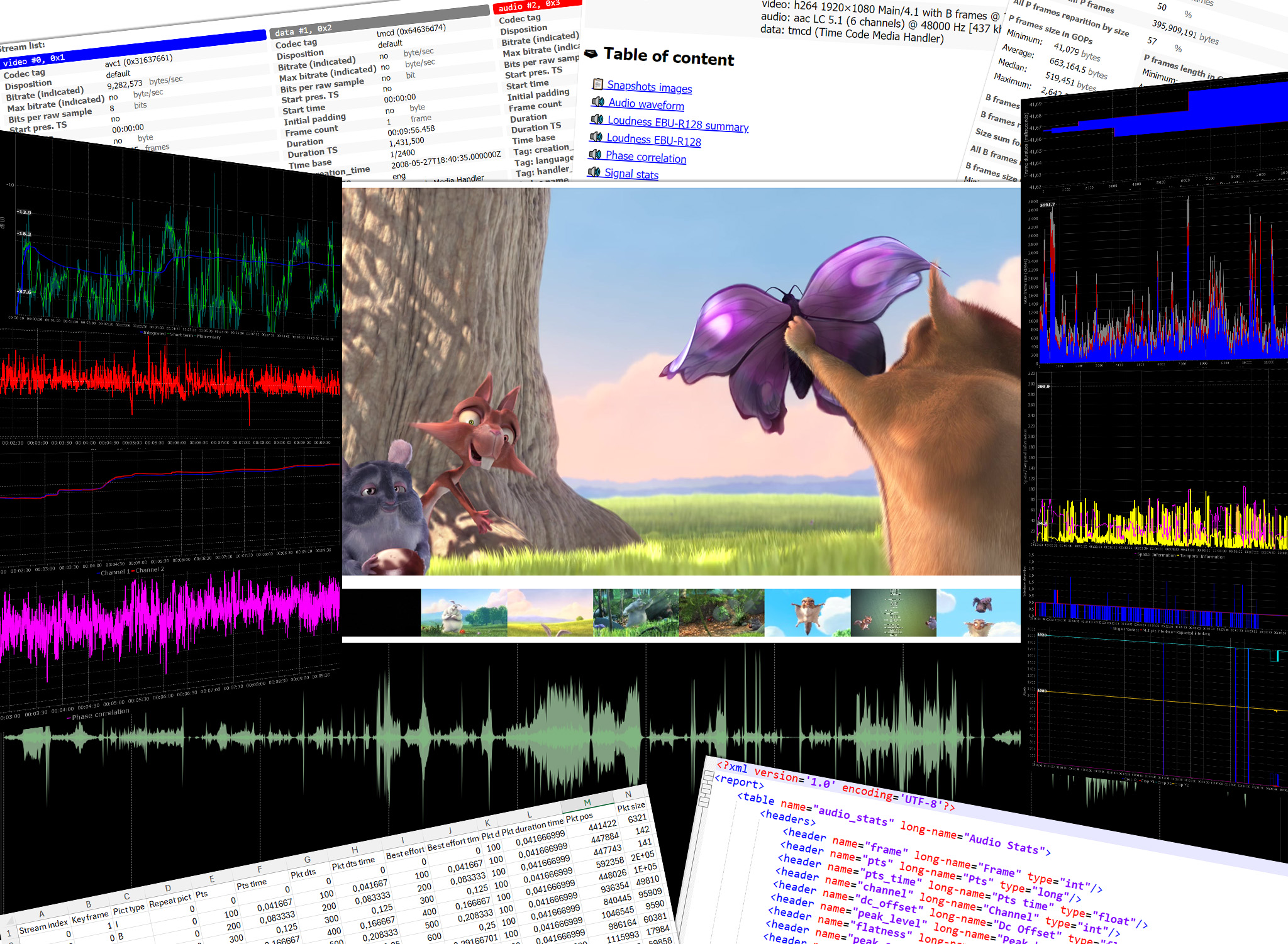
Mediadeepa is a command line standalone application (no GUI, no specific setup).
This application is licensed with the GNU General Public License v3.
Mediadeepa can handle any audio/video files managed by FFmpeg, and produce reports with it.
Analysis scope is currently based on FFmpeg filters and tools:
- Audio phase meter
aphasemeter - Time domain statistics about audio frames
astats - Audio loudness meter (EBU R128 scanner)
ebur128 - Audio silence detection
silencedetect - Video black/block artifacts/blurred/duplicate/interlacing frames detection (
blackdetect/blockdetect/blurdetect/freezedetect/idet) - Video border detection
cropdetect - Video spatial information (SI) and temporal information (TI)
siti - Structural media container information: audio/video stream frames size, timing, GOP type
- Create a technical resumed of media file based on FFprobe media file header
- Optional filter use, based on command line (user choice) and current FFmpeg filter availability on app environment.
- User can optionally add timed constraints:
- start position on media file
- limit analysis duration on media file
- limit time to do the analysis operation
- During the analyzing operation, an ETA/progress bar is displayed, and based on current FFmpeg processing
And it can export to file the FFprobe XML with media headers (container and A/V streams).
This application can run on three different "modes":
- Process to export: this is the classical mode. Mediadeepa will drive FFmpeg to produce analysis data from your source file, and export the result a the end.
- Process to extract: sometimes, you don't need to process data during the analysis session. So, Mediadeepa can just extract to raw text/xml files (zipped in one archive file) all the gathered data from FFmpeg.
- Import to export: to load in Mediadeepa all gathered raw data files. Mediadeepa is very tolerant with the zip content, notably if they were not created by Mediadeepa (originally). No one is mandatory in zip.
You can process multiple files and directory scans in one run, as well as load a text file as file list to process.
- It only support the first video, and the first founded audio stream of a file.
- Audio mono and stereo only.
- Some process take (long) time to do, like SITI and container analyzing, caused by poor FFmpeg/FFprobe performances with these filters.
- Loudness EBU R-128,and audio stats measures works correctly with FFmpeg v7+, due to internal bugs/limitations with the previous versions.
- Limited file start position time and duration are only applied on media analyzing, not container, image snapshot or audio signal.
An internal warning will by displayed if you try to works with a Zip archive created by a different Mediadeepa version.
- Java/JRE/JDK 21+
- FFmpeg/FFprobe v5+ (v7+ highly recommended)
Declared on OS (Windows/Linux/macOS) PATH.
Download the last application release, as a Linux RPM or DEB package, or as an executable JAR (autonomous fat JAR file), downloaded directly from GitHub releases page, and build at each releases.
Install/update with
# DEB file on Debian/Ubuntu Linux distribs
sudo dpkg -i mediadeepa-0.1.0.deb
# RPM file on RHEL/CentOS Linux distribs
sudo rpm -U mediadeepa-0.1.0.rpmRemove with sudo dpkg -r mediadeepa or rpm -e mediadeepa.
After, on Linux, run mediadeepa [parameters], and man mediadeepa for the internal doc man page.
On Windows/macOS, just run java -jar mediadeepa-0.1.0.jar [options].
And simply run the application with java -jar mediadeepa-0.1.0.jar.
Mediadeepa contain embedded help, displayed with the -h parameter.
You can set the command line parameters with java -jar mediadeepa-0.1.0.jar [parameters].
You can build yourself a JAR, with Git and Maven.
Run on Linux/WSL/macOS, after setup Git and Maven:
git clone https://github.com/mediaexmachina/mediadeepa.git
cd mediadeepa
mvn install -DskipTestsBuild jar will be founded on target directory as mediadeepa-0.1.0.jar
Export to the current directory the analysis report for the file videofile.mov:
mediadeepa -i videofile.mov -f report -e .
Export to my Download directory the analysis result, as MS Excel and graphic files, the media file videofile.mov, only for audio and media container:
mediadeepa -i videofile.mov -c -f xlsx -f graphic -vn -e $HOME/Downloads
All available Export formats type are listed by:
mediadeepa -o
Just:
mediadeepa -i videofile.mov --extract analysing-archive.zip
You can setup FFmpeg, like with import, like:
mediadeepa -i videofile.mov -c -an --extract analysing-archive.zip
Extracted (archive) ZIP file can be loaded simply by -i:
mediadeepa -i analysing-archive.zip -f report -f graphic -e .
Add -i options to works with multiple files, like:
mediadeepa -i analysing-archive.zip -i videofile.mov -i anotherfile.wav -f report -f graphic -e .
You can mix archive zip files and media files, but beware to not import with extract (zip to zip) or use single output file mode (--single-export).
With the same restrictions as Multiple Import or Process, you can use a directory with -i parameter.
mediadeepa -i /some/directory -i /some/another/directory -f report -f graphic -e .
All non hidden founded files, not recursively (ignore the sub directories) will be used. You should use include/exclude parameter to manage the file selection criteria.
Use:
mediadeepa -i /some/directory --recursive --exclude-path never-this --include-ext ".mkv" -f report -f graphic -e .
To
- scan recursively
/some/directorydirectory - with the
/some/directory/never-this/*directory ignored - only for MKV files
More options are available.
With the same options and restrictions as Directory scan to input files, just add --scan 10 to scan every 10 seconds all provided directories (simple -i files will be processed on application starts), like:
mediadeepa -i /some/directory --scan 10 -f report -f graphic -e .
Stop the scans with a key-press, or just with CTRL+C.
With the -il, as input list option:
mediadeepa -if my-medias.txt -f report -f graphic -e .
And the my-medias.txt file can just contain:
analysing-archive.zip
videofile.mov
anotherfile.wav
- Any space lines are ignored.
- Charset load respect the current OS session.
- You can use Windows and Linux new lines symbols (and you can mix them).
- You can accumulate multiple
-iand-iloptions, with the same limits as Multiple Import or Process. - Before starts the imports and processing, the application will check and throw an error if a file is missing (in
-i,-il, and in the lists itself).
You can read the FFmpeg filter documentation to know the behavior for each used filters, and the kind of returned values.
The project website contain the full documentation regarding the internal variables to specify produced filenames, image sizes...
You can found some documentation:
- On the Mediadeepa website https://gh.mexm.media/mediadeepa
- On the project's README on GitHub.
- On the Mediadeepa command line interface.
- On the integrated app man page.
This documentation source is located on src/main/resources/doc/en directory.
Send bug reports on GitHub project page
- Help with the documentation.
- Propose pull requests.
- Or just take time to test the application and report the experience.
If you have any questions, feel free to reach out via any contact method listed on https://mexm.media.
In the project source repository, you will found some tools to end-to-ends (e2e) automatic tests, in order to check the application behavior with real video files.
These tests are optional during the run of classical automatic tests, and only concerns dev. operations.
To run classical automatic tests, just run a mvn test.
To run e2e tests, you will need ffmpeg and bash:
- Create video tests files on
.demo-media-fileswithbash create-demo-files.bash(approx 230MB). - Optionally run
bash create-long-demo-file.bashto create a big test video file. - Next, just run
mvn test.
E2e tests take time. They will produce temp files in target directory (e2e* directories). A simple mvn clean wipe them, else the e2e scripts can reuse old generated files and don't loose some time.
E2e tests deeply checks all produced data from the application.
On each git tag, a GitHub Action will make a DEB and a RPM package on GitHub releases.
This Action use linux-springboot-packager to generate this files. Free feel to read this project documentation.
These packages are provided "as-it", as same for Mediadeepa. They are not signed.
Mediadeepa would never have been possible without the help of these magnificent and amazing OSS projects:
And the tech stack:
- Java 21
- Spring Boot 3
- Picocli 4
- My
prodlibandmedialibutility libs. - Maven (see
pom.xmlfor more information) - Open CSV
- Apache POI (poi-ooxml)
- SQLite JDBC
- Jackson
- jFreechart
- j2html
See THIRD-PARTY.txt file for more information on licenses and the full tech stack.
This page was generated by Mediadeepa when producing this version of the application, and is based on the functions available at that time.
© Media ex Machina 2022-2024