Log Spacemap Project #8442
Log Spacemap Project #8442
Conversation
76ce679
to
b14bc54
Compare
7cd2a5f
to
b2c78ee
Compare
20b8058
to
bdda73a
Compare
|
Hi there, I spent the last few days reviewing this code. It's of great interest to me at work as we land in this pathological case often. I don't know how this community works, would my PR approval be helpful at all? Code's quite clean. |
bdda73a
to
c3da4d2
Compare
|
Thanks for reading through the review and I'm glad to hear that it will help you! I think we can count you as a reviewer - more reviewers are always welcome. Keep in mind though that since this is a large change and in the metaslab code, I'd personally feel most comfortable merging this once I get feedback from folks whose code I had to change or those who have recently made changes to related codepaths. In the meantime, feel free to let me know if you have any specific suggestions/feedback from your code review. |
|
Regarding the |
I agree although I'm not that familiar on the infrastructure changes that would be needed for this. @behlendorf thoughts? |
|
Hi, Could it be possible to rebase this beautyfull piece of code to master ? Thanks, |
95175e3
to
245e482
Compare
|
@edillmann rebased |
For exactly this reason this behavior is supported by the existing infrastructure. Unfortunately, it's really not documented anywhere other than in the zimport commit itself, 133a5c6 . @sdimitro you're going to want to add the following line to the top most commit in this PR. Assuming that works as intended I think we should update the https://github.com/zfsonlinux/zfs/wiki/Buildbot-Options documentation on the wiki to more prominently describe hot to use this functionality. |
|
@sdimitro can you please rebase this on master now that redacted send/recv has been merged. |
|
Just rebased on the latest master. @behlendorf can you take a look when you get the change now that redacted send/receive is in? |
a7f952f
to
c5c0546
Compare
0c73bbe
to
b8852f3
Compare
= Motivation At Delphix we've seen a lot of customer systems where fragmentation is over 75% and random writes take a performance hit because a lot of time is spend on I/Os that update on-disk space accounting metadata. Specifically, we seen cases where 20% to 40% of sync time is spend after sync pass 1 and ~30% of the I/Os on the system is spent updating spacemaps. The problem is that these pools have existed long enough that we've touched almost every metaslab at least once, and random writes scatter frees across all metaslabs every TXG, thus appending to their spacemaps and resulting in many I/Os. To give an example, assuming that every VDEV has 200 metaslabs and our writes fit within a single spacemap block (generally 4K) we have 200 I/Os. Then if we assume 2 levels of indirection, we need 400 additional I/Os and since we are talking about metadata for which we keep 2 extra copies for redundancy we need to triple that number, leading to a total of 1800 I/Os per VDEV every TXG. We could try and decrease the number of metaslabs so we have less I/Os per TXG but then each metaslab would cover a wider range on disk and thus would take more time to be loaded in memory from disk. In addition, after it's loaded, it's range tree would consume more memory. Another idea would be to just increase the spacemap block size which would allow us to fit more entries within an I/O block resulting in fewer I/Os per metaslab and a speedup in loading time. The problem is still that we don't deal with the number of I/Os going up as the number of metaslabs is increasing and the fact is that we generally write a lot to a few metaslabs and a little to the rest of them. Thus, just increasing the block size would actually waste bandwidth because we won't be utilizing our bigger block size. = About this patch This patch introduces the Log Spacemap project which provides the solution to the above problem while taking into account all the aforementioned tradeoffs. The details on how it achieves that can be found in the references sections below and in the code (see Big Theory Statement in spa_log_spacemap.c). Even though the change is fairly constraint within the metaslab and lower-level SPA codepaths, there is a side-change that is user-facing. The change is that VDEV IDs from VDEV holes will no longer be reused. To give some background and reasoning for this, when a log device is removed and its VDEV structure was replaced with a hole (or was compacted; if at the end of the vdev array), its vdev_id could be reused by devices added after that. Now with the pool-wide space maps recording the vdev ID, this behavior can cause problems (e.g. is this entry refering to a segment in the new vdev or the removed log?). Thus, to simplify things the ID reuse behavior is gone and now vdev IDs for top-level vdevs are truly unique within a pool. = Testing The illumos implementation of this feature has been used internally for a year and has been in production for ~6 months. For this patch specifically there don't seem to be any regressions introduced to ZTS and I have been running zloop for a week without any related problems. = Performance Analysis (Linux Specific) All performance results and analysis for illumos can be found in the links of the references. Redoing the same experiments in Linux gave similar results. Below are the specifics of the Linux run. After the pool reached stable state the percentage of the time spent in pass 1 per TXG was 64% on average for the stock bits while the log spacemap bits stayed at 95% during the experiment (graph: sdimitro.github.io/img/linux-lsm/PercOfSyncInPassOne.png). Sync times per TXG were 37.6 seconds on average for the stock bits and 22.7 seconds for the log spacemap bits (related graph: sdimitro.github.io/img/linux-lsm/SyncTimePerTXG.png). As a result the log spacemap bits were able to push more TXGs, which is also the reason why all graphs quantified per TXG have more entries for the log spacemap bits. Another interesting aspect in terms of txg syncs is that the stock bits had 22% of their TXGs reach sync pass 7, 55% reach sync pass 8, and 20% reach 9. The log space map bits reached sync pass 4 in 79% of their TXGs, sync pass 7 in 19%, and sync pass 8 at 1%. This emphasizes the fact that not only we spend less time on metadata but we also iterate less times to convergence in spa_sync() dirtying objects. [related graphs: stock- sdimitro.github.io/img/linux-lsm/NumberOfPassesPerTXGStock.png lsm- sdimitro.github.io/img/linux-lsm/NumberOfPassesPerTXGLSM.png] Finally, the improvement in IOPs that the userland gains from the change is approximately 40%. There is a consistent win in IOPS as you can see from the graphs below but the absolute amount of improvement that the log spacemap gives varies within each minute interval. sdimitro.github.io/img/linux-lsm/StockVsLog3Days.png sdimitro.github.io/img/linux-lsm/StockVsLog10Hours.png = Porting to Other Platforms For people that want to port this commit to other platforms below is a list of ZoL commits that this patch depends on: Make zdb results for checkpoint tests consistent db58794 Update vdev_is_spacemap_addressable() for new spacemap encoding 419ba59 Simplify spa_sync by breaking it up to smaller functions 8dc2197 Factor metaslab_load_wait() in metaslab_load() b194fab Rename range_tree_verify to range_tree_verify_not_present df72b8b Change target size of metaslabs from 256GB to 16GB c853f38 zdb -L should skip leak detection altogether 21e7cf5 vs_alloc can underflow in L2ARC vdevs 7558997 Simplify log vdev removal code 6c926f4 Get rid of space_map_update() for ms_synced_length 425d323 Introduce auxiliary metaslab histograms 928e8ad Error path in metaslab_load_impl() forgets to drop ms_sync_lock 8eef997 = References Background, Motivation, and Internals of the Feature - OpenZFS 2017 Presentation: youtu.be/jj2IxRkl5bQ - Slides: slideshare.net/SerapheimNikolaosDim/zfs-log-spacemaps-project Flushing Algorithm Internals & Performance Results (Illumos Specific) - Blogpost: sdimitro.github.io/post/zfs-lsm-flushing/ - OpenZFS 2018 Presentation: youtu.be/x6D2dHRjkxw - Slides: slideshare.net/SerapheimNikolaosDim/zfs-log-spacemap-flushing-algorithm Upstream Delphix Issues: DLPX-51539, DLPX-59659, DLPX-57783, DLPX-61438, DLPX-41227, DLPX-59320 DLPX-63385 Signed-off-by: Serapheim Dimitropoulos <serapheim@delphix.com>
Codecov Report
@@ Coverage Diff @@
## master #8442 +/- ##
==========================================
+ Coverage 78.63% 78.7% +0.07%
==========================================
Files 401 402 +1
Lines 120157 120977 +820
==========================================
+ Hits 94481 95211 +730
- Misses 25676 25766 +90
Continue to review full report at Codecov.
|

|
Will this make it into a 0.8.x point release? |
|
@satmandu this new feature will be part of the next major release. There's no plan to include in an 0.8.x point release. |
|
Ouch.. so another year or so before we can escape from wicked fragmentation issues? That's a big bummer. |
= Motivation At Delphix we've seen a lot of customer systems where fragmentation is over 75% and random writes take a performance hit because a lot of time is spend on I/Os that update on-disk space accounting metadata. Specifically, we seen cases where 20% to 40% of sync time is spend after sync pass 1 and ~30% of the I/Os on the system is spent updating spacemaps. The problem is that these pools have existed long enough that we've touched almost every metaslab at least once, and random writes scatter frees across all metaslabs every TXG, thus appending to their spacemaps and resulting in many I/Os. To give an example, assuming that every VDEV has 200 metaslabs and our writes fit within a single spacemap block (generally 4K) we have 200 I/Os. Then if we assume 2 levels of indirection, we need 400 additional I/Os and since we are talking about metadata for which we keep 2 extra copies for redundancy we need to triple that number, leading to a total of 1800 I/Os per VDEV every TXG. We could try and decrease the number of metaslabs so we have less I/Os per TXG but then each metaslab would cover a wider range on disk and thus would take more time to be loaded in memory from disk. In addition, after it's loaded, it's range tree would consume more memory. Another idea would be to just increase the spacemap block size which would allow us to fit more entries within an I/O block resulting in fewer I/Os per metaslab and a speedup in loading time. The problem is still that we don't deal with the number of I/Os going up as the number of metaslabs is increasing and the fact is that we generally write a lot to a few metaslabs and a little to the rest of them. Thus, just increasing the block size would actually waste bandwidth because we won't be utilizing our bigger block size. = About this patch This patch introduces the Log Spacemap project which provides the solution to the above problem while taking into account all the aforementioned tradeoffs. The details on how it achieves that can be found in the references sections below and in the code (see Big Theory Statement in spa_log_spacemap.c). Even though the change is fairly constraint within the metaslab and lower-level SPA codepaths, there is a side-change that is user-facing. The change is that VDEV IDs from VDEV holes will no longer be reused. To give some background and reasoning for this, when a log device is removed and its VDEV structure was replaced with a hole (or was compacted; if at the end of the vdev array), its vdev_id could be reused by devices added after that. Now with the pool-wide space maps recording the vdev ID, this behavior can cause problems (e.g. is this entry referring to a segment in the new vdev or the removed log?). Thus, to simplify things the ID reuse behavior is gone and now vdev IDs for top-level vdevs are truly unique within a pool. = Testing The illumos implementation of this feature has been used internally for a year and has been in production for ~6 months. For this patch specifically there don't seem to be any regressions introduced to ZTS and I have been running zloop for a week without any related problems. = Performance Analysis (Linux Specific) All performance results and analysis for illumos can be found in the links of the references. Redoing the same experiments in Linux gave similar results. Below are the specifics of the Linux run. After the pool reached stable state the percentage of the time spent in pass 1 per TXG was 64% on average for the stock bits while the log spacemap bits stayed at 95% during the experiment (graph: sdimitro.github.io/img/linux-lsm/PercOfSyncInPassOne.png). Sync times per TXG were 37.6 seconds on average for the stock bits and 22.7 seconds for the log spacemap bits (related graph: sdimitro.github.io/img/linux-lsm/SyncTimePerTXG.png). As a result the log spacemap bits were able to push more TXGs, which is also the reason why all graphs quantified per TXG have more entries for the log spacemap bits. Another interesting aspect in terms of txg syncs is that the stock bits had 22% of their TXGs reach sync pass 7, 55% reach sync pass 8, and 20% reach 9. The log space map bits reached sync pass 4 in 79% of their TXGs, sync pass 7 in 19%, and sync pass 8 at 1%. This emphasizes the fact that not only we spend less time on metadata but we also iterate less times to convergence in spa_sync() dirtying objects. [related graphs: stock- sdimitro.github.io/img/linux-lsm/NumberOfPassesPerTXGStock.png lsm- sdimitro.github.io/img/linux-lsm/NumberOfPassesPerTXGLSM.png] Finally, the improvement in IOPs that the userland gains from the change is approximately 40%. There is a consistent win in IOPS as you can see from the graphs below but the absolute amount of improvement that the log spacemap gives varies within each minute interval. sdimitro.github.io/img/linux-lsm/StockVsLog3Days.png sdimitro.github.io/img/linux-lsm/StockVsLog10Hours.png = Porting to Other Platforms For people that want to port this commit to other platforms below is a list of ZoL commits that this patch depends on: Make zdb results for checkpoint tests consistent db58794 Update vdev_is_spacemap_addressable() for new spacemap encoding 419ba59 Simplify spa_sync by breaking it up to smaller functions 8dc2197 Factor metaslab_load_wait() in metaslab_load() b194fab Rename range_tree_verify to range_tree_verify_not_present df72b8b Change target size of metaslabs from 256GB to 16GB c853f38 zdb -L should skip leak detection altogether 21e7cf5 vs_alloc can underflow in L2ARC vdevs 7558997 Simplify log vdev removal code 6c926f4 Get rid of space_map_update() for ms_synced_length 425d323 Introduce auxiliary metaslab histograms 928e8ad Error path in metaslab_load_impl() forgets to drop ms_sync_lock 8eef997 = References Background, Motivation, and Internals of the Feature - OpenZFS 2017 Presentation: youtu.be/jj2IxRkl5bQ - Slides: slideshare.net/SerapheimNikolaosDim/zfs-log-spacemaps-project Flushing Algorithm Internals & Performance Results (Illumos Specific) - Blogpost: sdimitro.github.io/post/zfs-lsm-flushing/ - OpenZFS 2018 Presentation: youtu.be/x6D2dHRjkxw - Slides: slideshare.net/SerapheimNikolaosDim/zfs-log-spacemap-flushing-algorithm Upstream Delphix Issues: DLPX-51539, DLPX-59659, DLPX-57783, DLPX-61438, DLPX-41227, DLPX-59320 DLPX-63385 Reviewed-by: Sean Eric Fagan <sef@ixsystems.com> Reviewed-by: Matt Ahrens <matt@delphix.com> Reviewed-by: George Wilson <gwilson@delphix.com> Reviewed-by: Brian Behlendorf <behlendorf1@llnl.gov> Signed-off-by: Serapheim Dimitropoulos <serapheim@delphix.com> Closes openzfs#8442
= Motivation At Delphix we've seen a lot of customer systems where fragmentation is over 75% and random writes take a performance hit because a lot of time is spend on I/Os that update on-disk space accounting metadata. Specifically, we seen cases where 20% to 40% of sync time is spend after sync pass 1 and ~30% of the I/Os on the system is spent updating spacemaps. The problem is that these pools have existed long enough that we've touched almost every metaslab at least once, and random writes scatter frees across all metaslabs every TXG, thus appending to their spacemaps and resulting in many I/Os. To give an example, assuming that every VDEV has 200 metaslabs and our writes fit within a single spacemap block (generally 4K) we have 200 I/Os. Then if we assume 2 levels of indirection, we need 400 additional I/Os and since we are talking about metadata for which we keep 2 extra copies for redundancy we need to triple that number, leading to a total of 1800 I/Os per VDEV every TXG. We could try and decrease the number of metaslabs so we have less I/Os per TXG but then each metaslab would cover a wider range on disk and thus would take more time to be loaded in memory from disk. In addition, after it's loaded, it's range tree would consume more memory. Another idea would be to just increase the spacemap block size which would allow us to fit more entries within an I/O block resulting in fewer I/Os per metaslab and a speedup in loading time. The problem is still that we don't deal with the number of I/Os going up as the number of metaslabs is increasing and the fact is that we generally write a lot to a few metaslabs and a little to the rest of them. Thus, just increasing the block size would actually waste bandwidth because we won't be utilizing our bigger block size. = About this patch This patch introduces the Log Spacemap project which provides the solution to the above problem while taking into account all the aforementioned tradeoffs. The details on how it achieves that can be found in the references sections below and in the code (see Big Theory Statement in spa_log_spacemap.c). Even though the change is fairly constraint within the metaslab and lower-level SPA codepaths, there is a side-change that is user-facing. The change is that VDEV IDs from VDEV holes will no longer be reused. To give some background and reasoning for this, when a log device is removed and its VDEV structure was replaced with a hole (or was compacted; if at the end of the vdev array), its vdev_id could be reused by devices added after that. Now with the pool-wide space maps recording the vdev ID, this behavior can cause problems (e.g. is this entry referring to a segment in the new vdev or the removed log?). Thus, to simplify things the ID reuse behavior is gone and now vdev IDs for top-level vdevs are truly unique within a pool. = Testing The illumos implementation of this feature has been used internally for a year and has been in production for ~6 months. For this patch specifically there don't seem to be any regressions introduced to ZTS and I have been running zloop for a week without any related problems. = Performance Analysis (Linux Specific) All performance results and analysis for illumos can be found in the links of the references. Redoing the same experiments in Linux gave similar results. Below are the specifics of the Linux run. After the pool reached stable state the percentage of the time spent in pass 1 per TXG was 64% on average for the stock bits while the log spacemap bits stayed at 95% during the experiment (graph: sdimitro.github.io/img/linux-lsm/PercOfSyncInPassOne.png). Sync times per TXG were 37.6 seconds on average for the stock bits and 22.7 seconds for the log spacemap bits (related graph: sdimitro.github.io/img/linux-lsm/SyncTimePerTXG.png). As a result the log spacemap bits were able to push more TXGs, which is also the reason why all graphs quantified per TXG have more entries for the log spacemap bits. Another interesting aspect in terms of txg syncs is that the stock bits had 22% of their TXGs reach sync pass 7, 55% reach sync pass 8, and 20% reach 9. The log space map bits reached sync pass 4 in 79% of their TXGs, sync pass 7 in 19%, and sync pass 8 at 1%. This emphasizes the fact that not only we spend less time on metadata but we also iterate less times to convergence in spa_sync() dirtying objects. [related graphs: stock- sdimitro.github.io/img/linux-lsm/NumberOfPassesPerTXGStock.png lsm- sdimitro.github.io/img/linux-lsm/NumberOfPassesPerTXGLSM.png] Finally, the improvement in IOPs that the userland gains from the change is approximately 40%. There is a consistent win in IOPS as you can see from the graphs below but the absolute amount of improvement that the log spacemap gives varies within each minute interval. sdimitro.github.io/img/linux-lsm/StockVsLog3Days.png sdimitro.github.io/img/linux-lsm/StockVsLog10Hours.png = Porting to Other Platforms For people that want to port this commit to other platforms below is a list of ZoL commits that this patch depends on: Make zdb results for checkpoint tests consistent db58794 Update vdev_is_spacemap_addressable() for new spacemap encoding 419ba59 Simplify spa_sync by breaking it up to smaller functions 8dc2197 Factor metaslab_load_wait() in metaslab_load() b194fab Rename range_tree_verify to range_tree_verify_not_present df72b8b Change target size of metaslabs from 256GB to 16GB c853f38 zdb -L should skip leak detection altogether 21e7cf5 vs_alloc can underflow in L2ARC vdevs 7558997 Simplify log vdev removal code 6c926f4 Get rid of space_map_update() for ms_synced_length 425d323 Introduce auxiliary metaslab histograms 928e8ad Error path in metaslab_load_impl() forgets to drop ms_sync_lock 8eef997 = References Background, Motivation, and Internals of the Feature - OpenZFS 2017 Presentation: youtu.be/jj2IxRkl5bQ - Slides: slideshare.net/SerapheimNikolaosDim/zfs-log-spacemaps-project Flushing Algorithm Internals & Performance Results (Illumos Specific) - Blogpost: sdimitro.github.io/post/zfs-lsm-flushing/ - OpenZFS 2018 Presentation: youtu.be/x6D2dHRjkxw - Slides: slideshare.net/SerapheimNikolaosDim/zfs-log-spacemap-flushing-algorithm Upstream Delphix Issues: DLPX-51539, DLPX-59659, DLPX-57783, DLPX-61438, DLPX-41227, DLPX-59320 DLPX-63385 Reviewed-by: Sean Eric Fagan <sef@ixsystems.com> Reviewed-by: Matt Ahrens <matt@delphix.com> Reviewed-by: George Wilson <gwilson@delphix.com> Reviewed-by: Brian Behlendorf <behlendorf1@llnl.gov> Signed-off-by: Serapheim Dimitropoulos <serapheim@delphix.com> Closes openzfs#8442
= Motivation At Delphix we've seen a lot of customer systems where fragmentation is over 75% and random writes take a performance hit because a lot of time is spend on I/Os that update on-disk space accounting metadata. Specifically, we seen cases where 20% to 40% of sync time is spend after sync pass 1 and ~30% of the I/Os on the system is spent updating spacemaps. The problem is that these pools have existed long enough that we've touched almost every metaslab at least once, and random writes scatter frees across all metaslabs every TXG, thus appending to their spacemaps and resulting in many I/Os. To give an example, assuming that every VDEV has 200 metaslabs and our writes fit within a single spacemap block (generally 4K) we have 200 I/Os. Then if we assume 2 levels of indirection, we need 400 additional I/Os and since we are talking about metadata for which we keep 2 extra copies for redundancy we need to triple that number, leading to a total of 1800 I/Os per VDEV every TXG. We could try and decrease the number of metaslabs so we have less I/Os per TXG but then each metaslab would cover a wider range on disk and thus would take more time to be loaded in memory from disk. In addition, after it's loaded, it's range tree would consume more memory. Another idea would be to just increase the spacemap block size which would allow us to fit more entries within an I/O block resulting in fewer I/Os per metaslab and a speedup in loading time. The problem is still that we don't deal with the number of I/Os going up as the number of metaslabs is increasing and the fact is that we generally write a lot to a few metaslabs and a little to the rest of them. Thus, just increasing the block size would actually waste bandwidth because we won't be utilizing our bigger block size. = About this patch This patch introduces the Log Spacemap project which provides the solution to the above problem while taking into account all the aforementioned tradeoffs. The details on how it achieves that can be found in the references sections below and in the code (see Big Theory Statement in spa_log_spacemap.c). Even though the change is fairly constraint within the metaslab and lower-level SPA codepaths, there is a side-change that is user-facing. The change is that VDEV IDs from VDEV holes will no longer be reused. To give some background and reasoning for this, when a log device is removed and its VDEV structure was replaced with a hole (or was compacted; if at the end of the vdev array), its vdev_id could be reused by devices added after that. Now with the pool-wide space maps recording the vdev ID, this behavior can cause problems (e.g. is this entry referring to a segment in the new vdev or the removed log?). Thus, to simplify things the ID reuse behavior is gone and now vdev IDs for top-level vdevs are truly unique within a pool. = Testing The illumos implementation of this feature has been used internally for a year and has been in production for ~6 months. For this patch specifically there don't seem to be any regressions introduced to ZTS and I have been running zloop for a week without any related problems. = Performance Analysis (Linux Specific) All performance results and analysis for illumos can be found in the links of the references. Redoing the same experiments in Linux gave similar results. Below are the specifics of the Linux run. After the pool reached stable state the percentage of the time spent in pass 1 per TXG was 64% on average for the stock bits while the log spacemap bits stayed at 95% during the experiment (graph: sdimitro.github.io/img/linux-lsm/PercOfSyncInPassOne.png). Sync times per TXG were 37.6 seconds on average for the stock bits and 22.7 seconds for the log spacemap bits (related graph: sdimitro.github.io/img/linux-lsm/SyncTimePerTXG.png). As a result the log spacemap bits were able to push more TXGs, which is also the reason why all graphs quantified per TXG have more entries for the log spacemap bits. Another interesting aspect in terms of txg syncs is that the stock bits had 22% of their TXGs reach sync pass 7, 55% reach sync pass 8, and 20% reach 9. The log space map bits reached sync pass 4 in 79% of their TXGs, sync pass 7 in 19%, and sync pass 8 at 1%. This emphasizes the fact that not only we spend less time on metadata but we also iterate less times to convergence in spa_sync() dirtying objects. [related graphs: stock- sdimitro.github.io/img/linux-lsm/NumberOfPassesPerTXGStock.png lsm- sdimitro.github.io/img/linux-lsm/NumberOfPassesPerTXGLSM.png] Finally, the improvement in IOPs that the userland gains from the change is approximately 40%. There is a consistent win in IOPS as you can see from the graphs below but the absolute amount of improvement that the log spacemap gives varies within each minute interval. sdimitro.github.io/img/linux-lsm/StockVsLog3Days.png sdimitro.github.io/img/linux-lsm/StockVsLog10Hours.png = Porting to Other Platforms For people that want to port this commit to other platforms below is a list of ZoL commits that this patch depends on: Make zdb results for checkpoint tests consistent db58794 Update vdev_is_spacemap_addressable() for new spacemap encoding 419ba59 Simplify spa_sync by breaking it up to smaller functions 8dc2197 Factor metaslab_load_wait() in metaslab_load() b194fab Rename range_tree_verify to range_tree_verify_not_present df72b8b Change target size of metaslabs from 256GB to 16GB c853f38 zdb -L should skip leak detection altogether 21e7cf5 vs_alloc can underflow in L2ARC vdevs 7558997 Simplify log vdev removal code 6c926f4 Get rid of space_map_update() for ms_synced_length 425d323 Introduce auxiliary metaslab histograms 928e8ad Error path in metaslab_load_impl() forgets to drop ms_sync_lock 8eef997 = References Background, Motivation, and Internals of the Feature - OpenZFS 2017 Presentation: youtu.be/jj2IxRkl5bQ - Slides: slideshare.net/SerapheimNikolaosDim/zfs-log-spacemaps-project Flushing Algorithm Internals & Performance Results (Illumos Specific) - Blogpost: sdimitro.github.io/post/zfs-lsm-flushing/ - OpenZFS 2018 Presentation: youtu.be/x6D2dHRjkxw - Slides: slideshare.net/SerapheimNikolaosDim/zfs-log-spacemap-flushing-algorithm Upstream Delphix Issues: DLPX-51539, DLPX-59659, DLPX-57783, DLPX-61438, DLPX-41227, DLPX-59320 DLPX-63385 Reviewed-by: Sean Eric Fagan <sef@ixsystems.com> Reviewed-by: Matt Ahrens <matt@delphix.com> Reviewed-by: George Wilson <gwilson@delphix.com> Reviewed-by: Brian Behlendorf <behlendorf1@llnl.gov> Signed-off-by: Serapheim Dimitropoulos <serapheim@delphix.com> Closes openzfs#8442
- Unbreak on CURRENT Includes the new Log Spacemap functionality: openzfs/zfs#8442 PR: 239342 Sponsored by: iXsystems git-svn-id: svn+ssh://svn.freebsd.org/ports/head@507006 35697150-7ecd-e111-bb59-0022644237b5
- Unbreak on CURRENT Includes the new Log Spacemap functionality: openzfs/zfs#8442 PR: 239342 Sponsored by: iXsystems
- Unbreak on CURRENT Includes the new Log Spacemap functionality: openzfs/zfs#8442 PR: 239342 Sponsored by: iXsystems git-svn-id: svn+ssh://svn.freebsd.org/ports/head@507006 35697150-7ecd-e111-bb59-0022644237b5
= Motivation At Delphix we've seen a lot of customer systems where fragmentation is over 75% and random writes take a performance hit because a lot of time is spend on I/Os that update on-disk space accounting metadata. Specifically, we seen cases where 20% to 40% of sync time is spend after sync pass 1 and ~30% of the I/Os on the system is spent updating spacemaps. The problem is that these pools have existed long enough that we've touched almost every metaslab at least once, and random writes scatter frees across all metaslabs every TXG, thus appending to their spacemaps and resulting in many I/Os. To give an example, assuming that every VDEV has 200 metaslabs and our writes fit within a single spacemap block (generally 4K) we have 200 I/Os. Then if we assume 2 levels of indirection, we need 400 additional I/Os and since we are talking about metadata for which we keep 2 extra copies for redundancy we need to triple that number, leading to a total of 1800 I/Os per VDEV every TXG. We could try and decrease the number of metaslabs so we have less I/Os per TXG but then each metaslab would cover a wider range on disk and thus would take more time to be loaded in memory from disk. In addition, after it's loaded, it's range tree would consume more memory. Another idea would be to just increase the spacemap block size which would allow us to fit more entries within an I/O block resulting in fewer I/Os per metaslab and a speedup in loading time. The problem is still that we don't deal with the number of I/Os going up as the number of metaslabs is increasing and the fact is that we generally write a lot to a few metaslabs and a little to the rest of them. Thus, just increasing the block size would actually waste bandwidth because we won't be utilizing our bigger block size. = About this patch This patch introduces the Log Spacemap project which provides the solution to the above problem while taking into account all the aforementioned tradeoffs. The details on how it achieves that can be found in the references sections below and in the code (see Big Theory Statement in spa_log_spacemap.c). Even though the change is fairly constraint within the metaslab and lower-level SPA codepaths, there is a side-change that is user-facing. The change is that VDEV IDs from VDEV holes will no longer be reused. To give some background and reasoning for this, when a log device is removed and its VDEV structure was replaced with a hole (or was compacted; if at the end of the vdev array), its vdev_id could be reused by devices added after that. Now with the pool-wide space maps recording the vdev ID, this behavior can cause problems (e.g. is this entry referring to a segment in the new vdev or the removed log?). Thus, to simplify things the ID reuse behavior is gone and now vdev IDs for top-level vdevs are truly unique within a pool. = Testing The illumos implementation of this feature has been used internally for a year and has been in production for ~6 months. For this patch specifically there don't seem to be any regressions introduced to ZTS and I have been running zloop for a week without any related problems. = Performance Analysis (Linux Specific) All performance results and analysis for illumos can be found in the links of the references. Redoing the same experiments in Linux gave similar results. Below are the specifics of the Linux run. After the pool reached stable state the percentage of the time spent in pass 1 per TXG was 64% on average for the stock bits while the log spacemap bits stayed at 95% during the experiment (graph: sdimitro.github.io/img/linux-lsm/PercOfSyncInPassOne.png). Sync times per TXG were 37.6 seconds on average for the stock bits and 22.7 seconds for the log spacemap bits (related graph: sdimitro.github.io/img/linux-lsm/SyncTimePerTXG.png). As a result the log spacemap bits were able to push more TXGs, which is also the reason why all graphs quantified per TXG have more entries for the log spacemap bits. Another interesting aspect in terms of txg syncs is that the stock bits had 22% of their TXGs reach sync pass 7, 55% reach sync pass 8, and 20% reach 9. The log space map bits reached sync pass 4 in 79% of their TXGs, sync pass 7 in 19%, and sync pass 8 at 1%. This emphasizes the fact that not only we spend less time on metadata but we also iterate less times to convergence in spa_sync() dirtying objects. [related graphs: stock- sdimitro.github.io/img/linux-lsm/NumberOfPassesPerTXGStock.png lsm- sdimitro.github.io/img/linux-lsm/NumberOfPassesPerTXGLSM.png] Finally, the improvement in IOPs that the userland gains from the change is approximately 40%. There is a consistent win in IOPS as you can see from the graphs below but the absolute amount of improvement that the log spacemap gives varies within each minute interval. sdimitro.github.io/img/linux-lsm/StockVsLog3Days.png sdimitro.github.io/img/linux-lsm/StockVsLog10Hours.png = Porting to Other Platforms For people that want to port this commit to other platforms below is a list of ZoL commits that this patch depends on: Make zdb results for checkpoint tests consistent db58794 Update vdev_is_spacemap_addressable() for new spacemap encoding 419ba59 Simplify spa_sync by breaking it up to smaller functions 8dc2197 Factor metaslab_load_wait() in metaslab_load() b194fab Rename range_tree_verify to range_tree_verify_not_present df72b8b Change target size of metaslabs from 256GB to 16GB c853f38 zdb -L should skip leak detection altogether 21e7cf5 vs_alloc can underflow in L2ARC vdevs 7558997 Simplify log vdev removal code 6c926f4 Get rid of space_map_update() for ms_synced_length 425d323 Introduce auxiliary metaslab histograms 928e8ad Error path in metaslab_load_impl() forgets to drop ms_sync_lock 8eef997 = References Background, Motivation, and Internals of the Feature - OpenZFS 2017 Presentation: youtu.be/jj2IxRkl5bQ - Slides: slideshare.net/SerapheimNikolaosDim/zfs-log-spacemaps-project Flushing Algorithm Internals & Performance Results (Illumos Specific) - Blogpost: sdimitro.github.io/post/zfs-lsm-flushing/ - OpenZFS 2018 Presentation: youtu.be/x6D2dHRjkxw - Slides: slideshare.net/SerapheimNikolaosDim/zfs-log-spacemap-flushing-algorithm Upstream Delphix Issues: DLPX-51539, DLPX-59659, DLPX-57783, DLPX-61438, DLPX-41227, DLPX-59320 DLPX-63385 Reviewed-by: Sean Eric Fagan <sef@ixsystems.com> Reviewed-by: Matt Ahrens <matt@delphix.com> Reviewed-by: George Wilson <gwilson@delphix.com> Reviewed-by: Brian Behlendorf <behlendorf1@llnl.gov> Signed-off-by: Serapheim Dimitropoulos <serapheim@delphix.com> Closes openzfs#8442 Signed-off-by: Bryant G. Ly <bly@catalogicsoftware.com> Conflicts: include/zfeature_common.h man/man5/zfs-module-parameters.5 module/zfs/dsl_pool.c module/zfs/spa.c tests/zfs-tests/tests/functional/cli_root/zpool_get/zpool_get.cfg
Motivation
At Delphix we've seen a lot of customer systems where fragmentation is over 75% and random writes take a performance hit because a lot of time is spend on I/Os that update on-disk space accounting metadata. Specifically, we seen cases where 20% to 40% of sync time is spend after sync pass 1 and ~30% of the I/Os on the system is spent updating spacemaps.
The problem is that these pools have existed long enough that we've touched almost every metaslab at least once, and random writes scatter frees across all metaslabs every TXG, thus appending to their spacemaps and resulting in many I/Os. To give an example, assuming that every VDEV has 200 metaslabs and our writes fit within a single spacemap block (generally 4K) we have 200 I/Os. Then if we assume 2 levels of indirection, we need 400 additional I/Os and since we are talking about metadata for which we keep 2 extra copies for redundancy we need to triple that number, leading to a total of 1800 I/Os per VDEV every TXG.
We could try and decrease the number of metaslabs so we have less I/Os per TXG but then each metaslab would cover a wider range on disk and thus would take more time to be loaded in memory from disk. In addition, after it's loaded, it's range tree would consume more memory.
Another idea would be to just increase the spacemap block size which would allow us to fit more entries within an I/O block resulting in fewer I/Os per metaslab and a speedup in loading time. The problem is still that we don't deal with the number of I/Os going up as the number of metaslabs is increasing and the fact is that we generally write a lot to a few metaslabs and a little to the rest of them. Thus, just increasing the block size would actually waste bandwidth because we won't be utilizing our bigger block size.
About this patch
This patch introduces the Log Spacemap project which provides the solution to the above problem while taking into account all the aforementioned tradeoffs. The details on how it achieves that can be found in the references sections below and in the code (see Big Theory Statement in spa_log_spacemap.c).
Even though the change is fairly constraint within the metaslab and lower-level SPA codepaths, there is a side-change that is user-facing. The change is that VDEV IDs from VDEV holes will no longer be reused. To give some background and reasoning for this, when a log device is removed and its VDEV structure was replaced with a hole (or was compacted; if at the end of the vdev array), its vdev_id could be reused by devices added after that. Now with the pool-wide space maps recording the vdev ID, this behavior can cause problems (e.g. is this entry refering to a segment in the new vdev or the removed log?). Thus, to simplify things the ID reuse behavior is gone and now vdev IDs for top-level vdevs are truly unique within a pool.
Testing
The illumos implementation of this feature has been used internally for a year and has been in production for ~6 months. For this patch specifically there don't seem to be any regressions introduced to ZTS and I have been running zloop for a week without any related problems.
Per Matt's request I also made sure that opening the pool readonly from older versions of ZFS is possible:
I created 2 VMs -
[A] latest bits but without the Log Spacemap feature,
[B] latest bits patched with the Log Spacemap feature.
Performance Analysis (Linux Specific)
All performance results and analysis for illumos can be found in the links of the references. Redoing the same experiments in Linux gave similar results. Below are the specifics of the Linux run.
After the pool reached stable state the percentage of the time spent in pass 1 per TXG was 64% on average for the stock bits while the log spacemap bits stayed at 95% during the experiment.
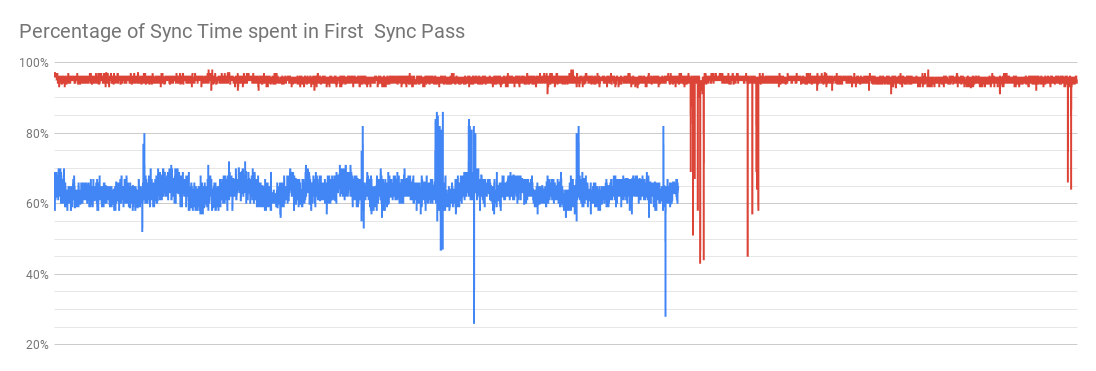
Sync times per TXG were 37.6 seconds on average for the stock bits and 22.7 seconds for the log spacemap bits.
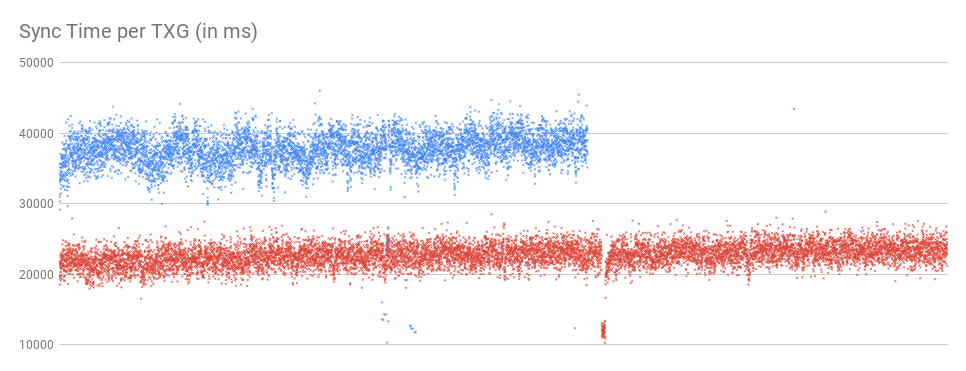
As a result the log spacemap bits were able to push more TXGs, which is also the reason why all graphs quantified per TXG have more entries for the log spacemap bits.
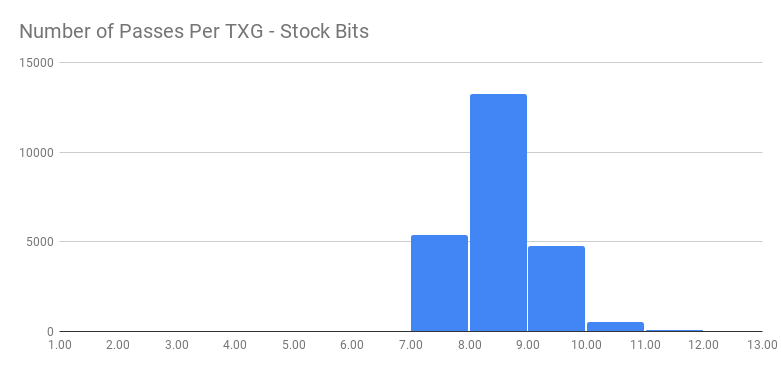
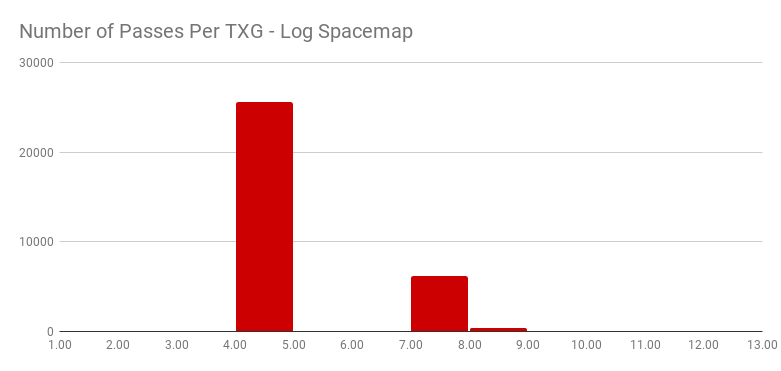
Another interesting aspect in terms of txg syncs is that the stock bits had 22% of their TXGs reach sync pass 7, 55% reach sync pass 8, and 20% reach 9. The log space map bits reached sync pass 4 in 79% of their TXGs, sync pass 7 in 19%, and sync pass 8 at 1%. This emphasizes the fact that not only we spend less time on metadata but we also iterate less times to convergence in spa_sync() dirtying objects.
Finally, the improvement in IOPs that the userland gains from the change is approximately 40%. There is a consistent win in IOPS as you can see from the graphs below but the absolute amount of improvement that the log spacemap gives varies within each minute interval.
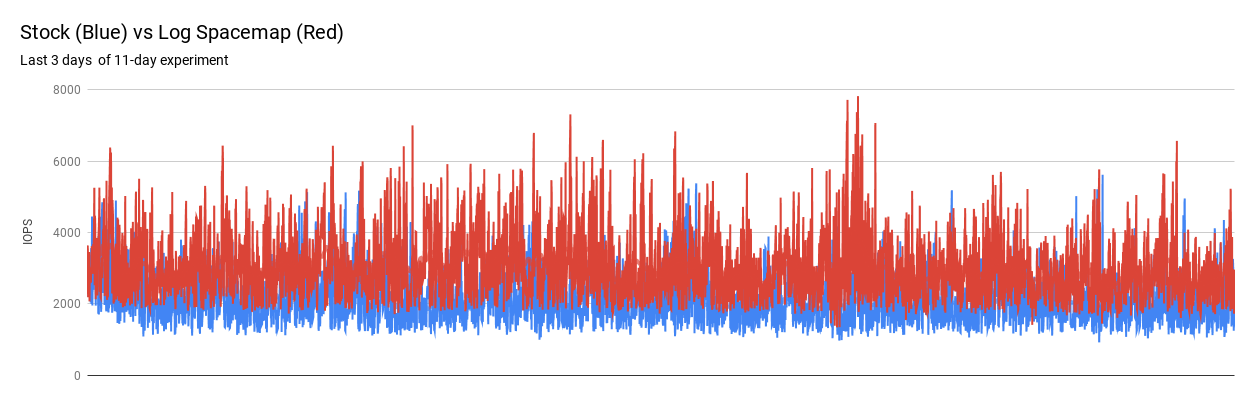
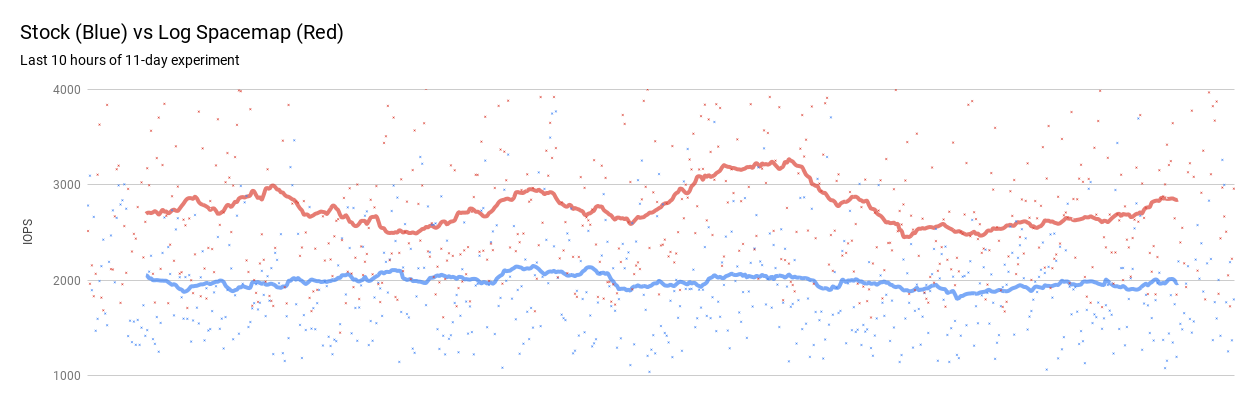
Porting to Other Platforms
For people that want to port this commit to other platforms below is a list of ZoL commits that this patch depends on:
Make zdb results for checkpoint tests consistent - db58794
Update vdev_is_spacemap_addressable() for new spacemap encoding - 419ba59
Simplify spa_sync by breaking it up to smaller functions - 8dc2197
Factor metaslab_load_wait() in metaslab_load() - b194fab
Rename range_tree_verify to range_tree_verify_not_present - df72b8b
Change target size of metaslabs from 256GB to 16GB - c853f38
zdb -L should skip leak detection altogether - 21e7cf5
vs_alloc can underflow in L2ARC vdevs - 7558997
Simplify log vdev removal code - 6c926f4
Get rid of space_map_update() for ms_synced_length - 425d323
Introduce auxiliary metaslab histograms - 928e8ad
Error path in metaslab_load_impl() forgets to drop ms_sync_lock - 8eef997
References
Background, Motivation, and Internals of the Feature
Flushing Algorithm Internals & Performance Results
(Illumos Specific)
Upstream Delphix Issues:
DLPX-51539, DLPX-59659, DLPX-57783, DLPX-61438, DLPX-41227, DLPX-59320
Signed-off-by: Serapheim Dimitropoulos serapheim@delphix.com
Types of changes
Checklist:
Signed-off-by.