[BUG] long_callback short interval makes job run in loop #1769
Comments
|
Thanks for the report @sam1902, I managed to whittle down the issue to the behavior of from dash import dcc, html, Dash, Input, Output
from time import sleep
# App gets stuck if interval_s <= callback_sleep_s
interval_s = 1
callback_sleep_s = 2
app = Dash(__name__)
app.layout = html.Div([
dcc.Interval(id="interval", disabled=False, interval=interval_s * 1000),
html.Div(id="n_intervals_display")
])
@app.callback(
Output("interval", "disabled"),
Input('interval', 'n_intervals'),
)
def update_output(n_intervals):
sleep(callback_sleep_s)
return True
@app.callback(
Output("n_intervals_display", "children"),
Input('interval', 'n_intervals'),
)
def update_interval(n_intervals):
return f"n_intervals: {n_intervals}"
if __name__ == '__main__':
app.run_server(port=8051)It's seems that it's impossible to disable an interval from a callback with duration that exceeds the interval duration. In the long callback case, @alexcjohnson @chriddyp is this the expected (and desirable) behavior of the renderer? |
|
After looking through the long_callback's
I arrived at that scenario after a lot of ugly logging in my custom fork. Here is a pseudo-code of what goes on: def callback(user_store_data, args):
pending_key = cache.build_key(args)
current_key = user_store_data["current_key"]
should_cancel = (pending_key == current_key)
## Call Number 2:
# current_key == None
# pending_key == 52c...
# should_cancel == False
if should_cancel:
return cancel()
if results_ready(pending_key):
## Call Number 1:
# current_key == None
# pending_key == 52c...
# should_cancel == False
results = get_results()
# Set this so that next interval call, we have
# current_key == pending_key and therefore cancel happens.
# But the thing is, it never does happen ....
user_store_data["current_key"] = pending_key
return dict(
results=results,
interval_disabled=False,
user_store_data=user_store_data
)I think the only solution is to not rely on setting interval_disabled = True
user_store_data["current_key"] = None
user_store_data["pending_key"] = None
user_store_data["pending_job"] = None
callback_manager.terminate_job(pending_job)but this didn't help either. I think that returning a large amount of data makes the callback return chain slow, which let the interval trigger in that time frame, and since the return callback chain has not finished yet, we still have I'm not familiar enough with Dash's insides to restructure how |
|
Thanks for the detailed debugging @sam1902!
I think this has the same root cause as the example I posted above (#1769 (comment)). In both cases, it looks like the updates returned by the callback are ignored if another interval is scheduled during the execution of the callback. In this example, the update was to disable the interval. In the long callback case, the update is to update the Store component with the new |
|
I think so too, but the reason another interval is scheduled during the execution of the callback is that fetching the results of my callbacks takes too long (because of the I/O size). Earlier I mentionned that setting The Ideally, long_callback should have two different mecanism to:
|
|
I believe that this bug is an effect of a more general problem related directly to the dcc.Iterval component. If the dcc.Interval is triggering a callback whose duration is longer than the interval property of the dcc.Interval component, the callback will never be fully executed. Furthermore, if this callback is supposed to disable the dcc.Interval under certain circumstances, the dcc.Interval will never be disabled and the app will get stuck in a loop. It has been discussed here. |
|
I've got a 0% > 50% > 90% > 10% > 40% > 95% > 20% > 60% then my web browser receives three identical files 😆. I wish it only sent one file and that the final progress was 100% after the I'm very excited to switch to |
|
My app was relying heavily on Here is the tutorial I got mainly inspired by, but I added the whole socket.io layer so that I could get the updates client side without having to ask for them explicitly to the server. Whenever it has progress to report, the celery task makes an HTTP request to the FastAPI backend, which upon receiving it transfers it to the approriate client over Socket.io, making the Celery task able to report any progress update (even large pictures) to the client. Overall that stack is rather solid, but it required a full rewrite. Dash could also forgo using a |
Cool solution, and I wish some of those ideas got incorporated into Dash's |
@amarvin how do you determine the frequency of the interval? Could you share an example of your approach? |
|
Hi there, I came across the same issue, when returning large responses as a result of a long_callback.
This way, the result-fetching part only starts when the interval is already stopped. I'd be willing to make a PR for this, if someone agrees that the concept is reasonable. |
|
That looks like a fine solution, I'll be happy to review if you make a PR. |
|
Hi, is this planned for the next release or is it deeper in the backlog? |
|
@vkolevrestec I am working on this, my plan is to remove the interval component and handle the polling in the renderer so there can be only one request at a time. |
I'm really excited to use
long_callbacks because it helps a lot for my use-cases, but while reading the doc (Example 5) I found that there exists an undocumented parameterintervalwhich is set to1000in this example.I tried setting it to
1000too, but the progress updates were too slow, so I progressively lowered it. It behaved as I wanted when setting it to100(ms), but when running my job withinterval=100, when the job finishes, it is immediatly executed again, even though the launch button's event is not triggered.Minimal replication code
If you can't replicate this exact looping bug on your setup, try reducing the
intervalvalue until you see a looping behaviour with somediskcacheI/O errors, and when you do, progressively set it to something higher until the looping remains, but that the error disappear.Here is what such diskcache I/O errors look like, though in my real application I never witnessed these. There simply were no warnings !
Those are not critical errors causing the server to crash. It simply ends one of the processes, but the callback still loops back. Also, those happen anywhere within the loop (at any iteration, not just at the end).
Environment
pip list | grep dash:if frontend related, tell us your Browser, Version and OS
Describe the bug
When setting an
intervaltoo small, the callback runs, but once it finishes it runs again, and again etc in a loop fashion.From my replication attempts, this seems to be due to passing too large values to the long_callback's Output or
progress=[Output(..)], either during progress updates or at the end of the callback.I ran into this in my code because I dealt with large images encoded as data URIs, and the file size here are approximated by
"A"*4_000_000, which should weigh around 3.8MB, which is comparable to my image weight.Expected behavior
The callback should only be called once, no matter the progress callback frequency (i.e. interval time)
Screenshots
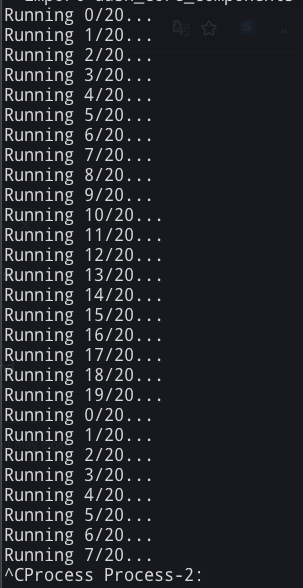
As you can see, it loops from
Runnning 19/20back toRunning 0/20without any warning or error:The text was updated successfully, but these errors were encountered: