A curated list for Efficient Large Language Models
- Network Pruning / Sparsity
- Knowledge Distillation
- Quantization
- Inference Acceleration
- Efficient MOE
- Efficient Architecture of LLM
- KV Cache Compression
- Text Compression
- Low-Rank Decomposition
- Hardware / System
- Tuning
- Survey
- Leaderboard
Please check out all the papers by selecting the sub-area you're interested in. On this main page, we're showing papers released in the past 90 days.
- May 29, 2024: We've had this awesome list for a year now 🥰! It's grown pretty long, so we're reorganizing it and would divide the list by their specific areas into different readme.
- Sep 27, 2023: Add tag
for papers accepted at NeurIPS'23.
- Sep 6, 2023: Add a new subdirectory project/ to organize those projects that are designed for developing a lightweight LLM.
- July 11, 2023: In light of the numerous publications that conduct experiments using PLMs (such as BERT, BART) currently, a new subdirectory efficient_plm/ is created to house papers that are applicable to PLMs but have yet to be verified for their effectiveness on LLMs (not implying that they are not suitable on LLM).
If you'd like to include your paper, or need to update any details such as conference information or code URLs, please feel free to submit a pull request. You can generate the required markdown format for each paper by filling in the information in generate_item.py and execute python generate_item.py. We warmly appreciate your contributions to this list. Alternatively, you can email me with the links to your paper and code, and I would add your paper to the list at my earliest convenience.
For each topic, we have curated a list of recommended papers that have garnered relatively high GitHub stars or citations.
Paper from June 13, 2024 - Now (see Full List from May 22, 2023 here)
- Network Pruning / Sparsity
- Knowledge Distillation
- Quantization
- Inference Acceleration
- Efficient MOE
- Efficient Architecture of LLM
- KV Cache Compression
- Text Compression
- Low-Rank Decomposition
- Hardware / System
- Tuning
- Survey

































| Title & Authors | Introduction | Links |
|---|---|---|
| ⭐ Knowledge Distillation of Large Language Models Yuxian Gu, Li Dong, Furu Wei, Minlie Huang |
 |
Github Paper |
 The Mamba in the Llama: Distilling and Accelerating Hybrid Models Junxiong Wang, Daniele Paliotta, Avner May, Alexander M. Rush, Tri Dao |
 |
Github Paper |
| FIRST: Teach A Reliable Large Language Model Through Efficient Trustworthy Distillation KaShun Shum, Minrui Xu, Jianshu Zhang, Zixin Chen, Shizhe Diao, Hanze Dong, Jipeng Zhang, Muhammad Omer Raza |
 |
Paper |
| Interactive DualChecker for Mitigating Hallucinations in Distilling Large Language Models Meiyun Wang, Masahiro Suzuki, Hiroki Sakaji, Kiyoshi Izumi |
 |
Paper |
| Transformers to SSMs: Distilling Quadratic Knowledge to Subquadratic Models Aviv Bick, Kevin Y. Li, Eric P. Xing, J. Zico Kolter, Albert Gu |
 |
Paper |
| Concept Distillation from Strong to Weak Models via Hypotheses-to-Theories Prompting Emmanuel Aboah Boateng, Cassiano O. Becker, Nabiha Asghar, Kabir Walia, Ashwin Srinivasan, Ehi Nosakhare, Victor Dibia, Soundar Srinivasan |
 |
Paper |
| LaDiMo: Layer-wise Distillation Inspired MoEfier Sungyoon Kim, Youngjun Kim, Kihyo Moon, Minsung Jang |
 |
Paper |
| BOND: Aligning LLMs with Best-of-N Distillation Pier Giuseppe Sessa, Robert Dadashi, Léonard Hussenot, Johan Ferret, Nino Vieillard et al |
 |
Paper |
| Enhancing Data-Limited Graph Neural Networks by Actively Distilling Knowledge from Large Language Models Quan Li, Tianxiang Zhao, Lingwei Chen, Junjie Xu, Suhang Wang |
 |
Paper |
| DDK: Distilling Domain Knowledge for Efficient Large Language Models Jiaheng Liu, Chenchen Zhang, Jinyang Guo, Yuanxing Zhang, Haoran Que, Ken Deng, Zhiqi Bai, Jie Liu, Ge Zhang, Jiakai Wang, Yanan Wu, Congnan Liu, Wenbo Su, Jiamang Wang, Lin Qu, Bo Zheng |
 |
Paper |
| Key-Point-Driven Mathematical Reasoning Distillation of Large Language Model Xunyu Zhu, Jian Li, Yong Liu, Can Ma, Weiping Wang |
 |
Paper |
| Don't Throw Away Data: Better Sequence Knowledge Distillation Jun Wang, Eleftheria Briakou, Hamid Dadkhahi, Rishabh Agarwal, Colin Cherry, Trevor Cohn |
Paper | |
| Multi-Granularity Semantic Revision for Large Language Model Distillation Xiaoyu Liu, Yun Zhang, Wei Li, Simiao Li, Xudong Huang, Hanting Chen, Yehui Tang, Jie Hu, Zhiwei Xiong, Yunhe Wang |
 |
Paper |
| BiLD: Bi-directional Logits Difference Loss for Large Language Model Distillation Minchong Li, Feng Zhou, Xiaohui Song |
 |
Paper |













































































| Title & Authors | Introduction | Links |
|---|---|---|
 ⭐ Fast Inference of Mixture-of-Experts Language Models with Offloading Artyom Eliseev, Denis Mazur |
 |
Github Paper |
| Diversifying the Expert Knowledge for Task-Agnostic Pruning in Sparse Mixture-of-Experts Zeliang Zhang, Xiaodong Liu, Hao Cheng, Chenliang Xu, Jianfeng Gao |
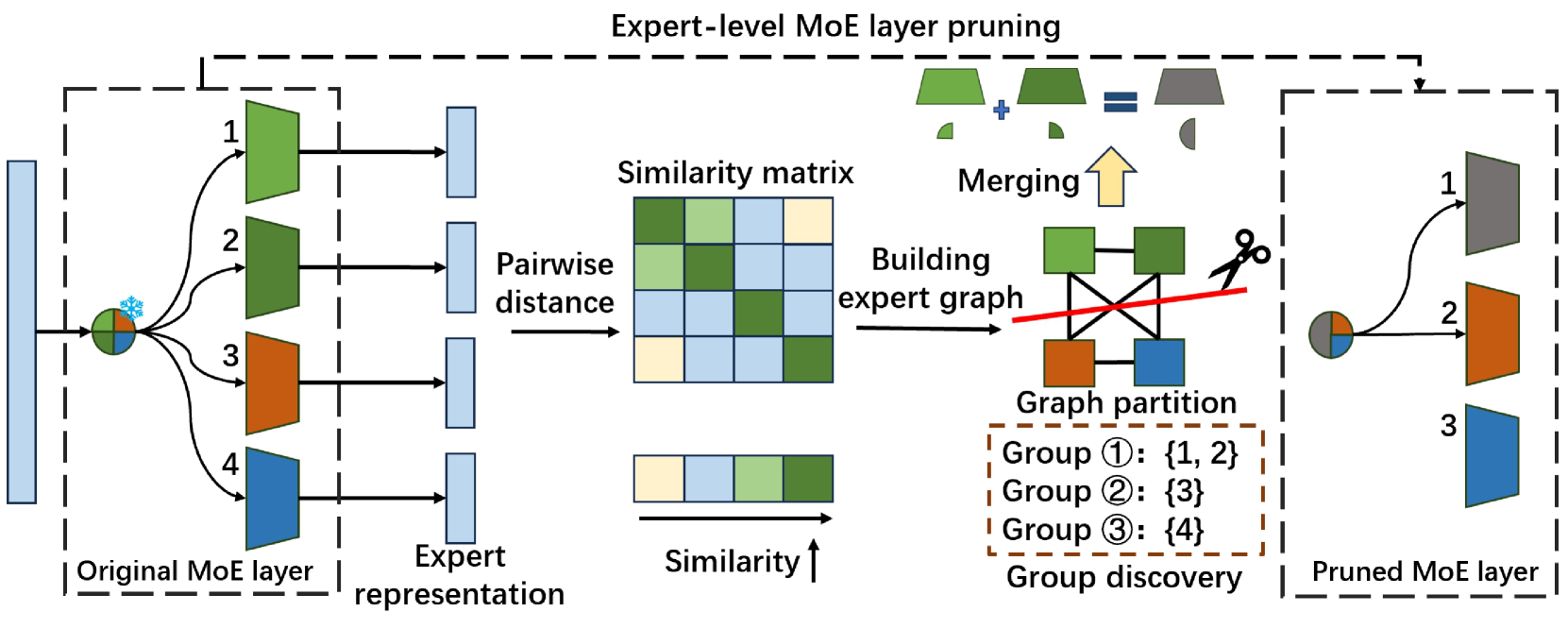 |
Paper |
 Efficient Expert Pruning for Sparse Mixture-of-Experts Language Models: Enhancing Performance and Reducing Inference Costs Enshu Liu, Junyi Zhu, Zinan Lin, Xuefei Ning, Matthew B. Blaschko, Shengen Yan, Guohao Dai, Huazhong Yang, Yu Wang |
 |
Github Paper |
 Examining Post-Training Quantization for Mixture-of-Experts: A Benchmark Pingzhi Li, Xiaolong Jin, Yu Cheng, Tianlong Chen |
 |
Github Paper |
| ME-Switch: A Memory-Efficient Expert Switching Framework for Large Language Models Jing Liu, Ruihao Gong, Mingyang Zhang, Yefei He, Jianfei Cai, Bohan Zhuang |
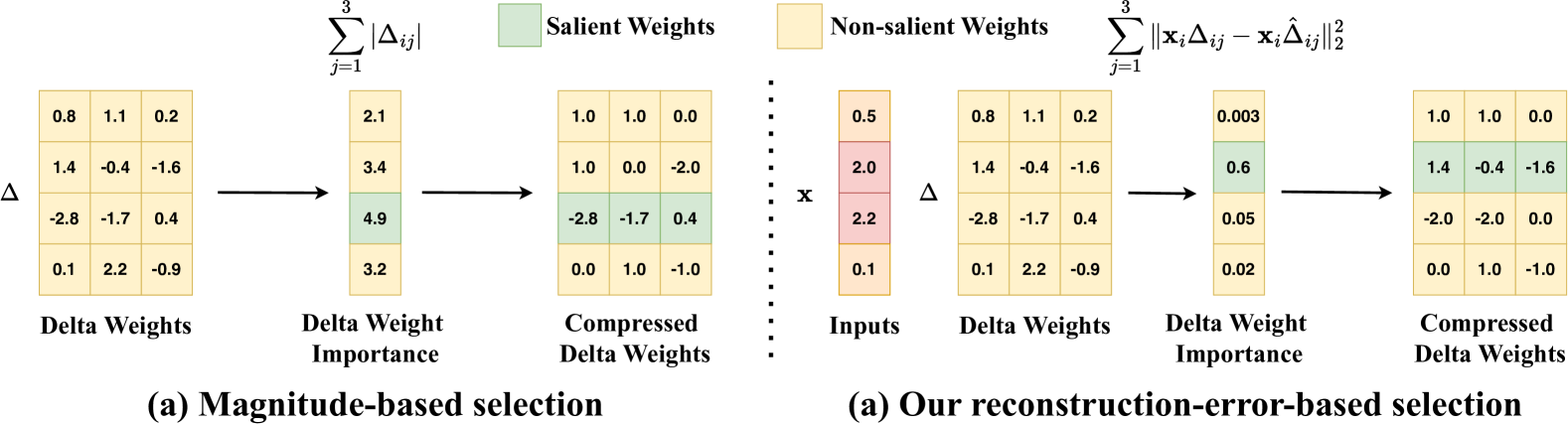 |
Paper |
| Title & Authors | Introduction | Links |
|---|---|---|
 ⭐ MobiLlama: Towards Accurate and Lightweight Fully Transparent GPT Omkar Thawakar, Ashmal Vayani, Salman Khan, Hisham Cholakal, Rao M. Anwer, Michael Felsberg, Tim Baldwin, Eric P. Xing, Fahad Shahbaz Khan |
 |
Github Paper Model |
 ⭐ Megalodon: Efficient LLM Pretraining and Inference with Unlimited Context Length Xuezhe Ma, Xiaomeng Yang, Wenhan Xiong, Beidi Chen, Lili Yu, Hao Zhang, Jonathan May, Luke Zettlemoyer, Omer Levy, Chunting Zhou |
 |
Github Paper |
| SentenceVAE: Enable Next-sentence Prediction for Large Language Models with Faster Speed, Higher Accuracy and Longer Context Hongjun An, Yifan Chen, Zhe Sun, Xuelong Li |
 |
Paper |
 Efficient LLM Training and Serving with Heterogeneous Context Sharding among Attention Heads Xihui Lin, Yunan Zhang, Suyu Ge, Barun Patra, Vishrav Chaudhary, Xia Song |
 |
Github Paper |
 Beyond KV Caching: Shared Attention for Efficient LLMs Bingli Liao, Danilo Vasconcellos Vargas |
 |
Github Paper |
| Title & Authors | Introduction | Links |
|---|---|---|
| ⭐ Model Tells You What to Discard: Adaptive KV Cache Compression for LLMs Suyu Ge, Yunan Zhang, Liyuan Liu, Minjia Zhang, Jiawei Han, Jianfeng Gao |
 |
Paper |
| A First Look At Efficient And Secure On-Device LLM Inference Against KV Leakage Huan Yang, Deyu Zhang, Yudong Zhao, Yuanchun Li, Yunxin Liu |
 |
Paper |
 Post-Training Sparse Attention with Double Sparsity Shuo Yang, Ying Sheng, Joseph E. Gonzalez, Ion Stoica, Lianmin Zheng |
 |
Github Paper |
 Eigen Attention: Attention in Low-Rank Space for KV Cache Compression Utkarsh Saxena, Gobinda Saha, Sakshi Choudhary, Kaushik Roy |
 |
Github Paper |
| Zero-Delay QKV Compression for Mitigating KV Cache and Network Bottlenecks in LLM Inference Zeyu Zhang,Haiying Shen |
 |
Paper |
| Finch: Prompt-guided Key-Value Cache Compression Giulio Corallo, Paolo Papotti |
 |
Paper |
 Palu: Compressing KV-Cache with Low-Rank Projection Chi-Chih Chang, Wei-Cheng Lin, Chien-Yu Lin, Chong-Yan Chen, Yu-Fang Hu, Pei-Shuo Wang, Ning-Chi Huang, Luis Ceze, Kai-Chiang Wu |
 |
Github Paper |
| ThinK: Thinner Key Cache by Query-Driven Pruning Yuhui Xu, Zhanming Jie, Hanze Dong, Lei Wang, Xudong Lu, Aojun Zhou, Amrita Saha, Caiming Xiong, Doyen Sahoo |
 |
Paper |
| RazorAttention: Efficient KV Cache Compression Through Retrieval Heads Hanlin Tang, Yang Lin, Jing Lin, Qingsen Han, Shikuan Hong, Yiwu Yao, Gongyi Wang |
 |
Paper |
| PQCache: Product Quantization-based KVCache for Long Context LLM Inference Hailin Zhang, Xiaodong Ji, Yilin Chen, Fangcheng Fu, Xupeng Miao, Xiaonan Nie, Weipeng Chen, Bin Cui |
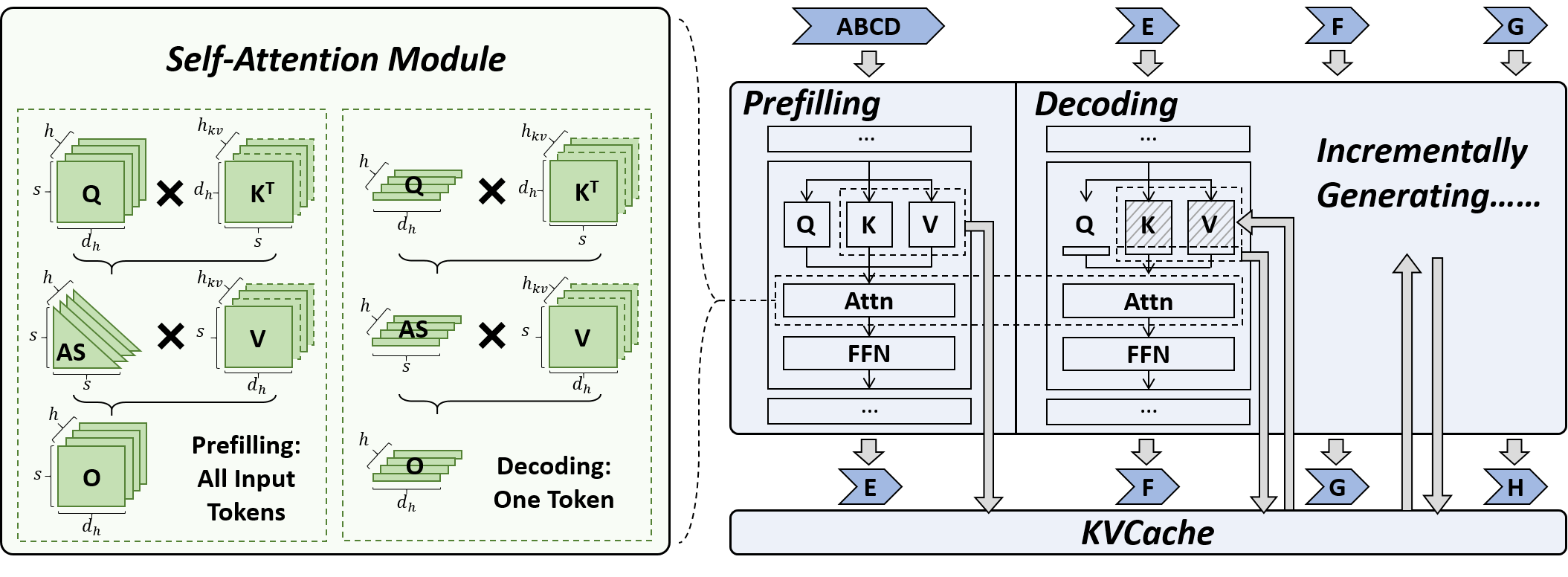 |
Paper |
 GoldFinch: High Performance RWKV/Transformer Hybrid with Linear Pre-Fill and Extreme KV-Cache Compression Daniel Goldstein, Fares Obeid, Eric Alcaide, Guangyu Song, Eugene Cheah |
 |
Github Paper |
 Efficient Sparse Attention needs Adaptive Token Release Chaoran Zhang, Lixin Zou, Dan Luo, Min Tang, Xiangyang Luo, Zihao Li, Chenliang Li |
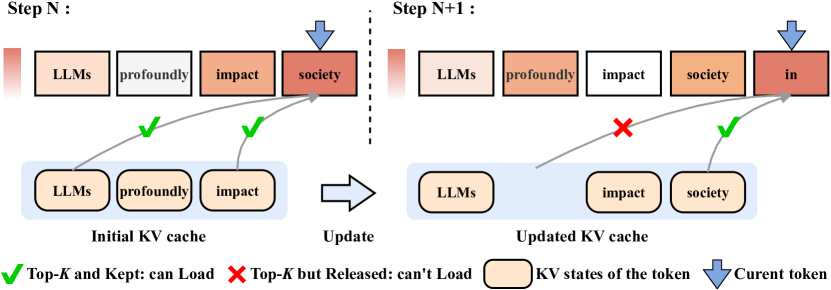 |
Github Paper |
 KV Cache Compression, But What Must We Give in Return? A Comprehensive Benchmark of Long Context Capable Approaches Jiayi Yuan, Hongyi Liu, Shaochen (Henry)Zhong, Yu-Neng Chuang, Songchen Li et al |
 |
Github Paper |
 MLKV: Multi-Layer Key-Value Heads for Memory Efficient Transformer Decoding Zayd Muhammad Kawakibi Zuhri, Muhammad Farid Adilazuarda, Ayu Purwarianti, Alham Fikri Aji |
 |
Github Paper |












| Title & Authors | Introduction | Links |
|---|---|---|
| MoDeGPT: Modular Decomposition for Large Language Model Compression Chi-Heng Lin, Shangqian Gao, James Seale Smith, Abhishek Patel, Shikhar Tuli, Yilin Shen, Hongxia Jin, Yen-Chang Hsu |
 |
Paper |
| MCNC: Manifold Constrained Network Compression Chayne Thrash, Ali Abbasi, Parsa Nooralinejad, Soroush Abbasi Koohpayegani, Reed Andreas, Hamed Pirsiavash, Soheil Kolouri |
 |
Paper |












| Title & Authors | Introduction | Links |
|---|---|---|
| Tensor Train Low-rank Approximation (TT-LoRA): Democratizing AI with Accelerated LLMs Afia Anjum, Maksim E. Eren, Ismael Boureima, Boian Alexandrov, Manish Bhattarai |
 |
Paper |
| Code Less, Align More: Efficient LLM Fine-tuning for Code Generation with Data Pruning Yun-Da Tsai, Mingjie Liu, Haoxing Ren |
 |
Paper |
PocketLLM: Enabling On-Device Fine-Tuning for Personalized LLMs Dan Peng, Zhihui Fu, Jun Wang |
Paper | |
 Increasing Model Capacity for Free: A Simple Strategy for Parameter Efficient Fine-tuning Haobo Song, Hao Zhao, Soumajit Majumder, Tao Lin |
 |
Github Paper |
| Compress then Serve: Serving Thousands of LoRA Adapters with Little Overhead Rickard Brüel-Gabrielsson, Jiacheng Zhu, Onkar Bhardwaj, Leshem Choshen et al |
 |
Paper |
| BlockLLM: Memory-Efficient Adaptation of LLMs by Selecting and Optimizing the Right Coordinate Blocks Amrutha Varshini Ramesh, Vignesh Ganapathiraman, Issam H. Laradji, Mark Schmidt |
 |
Paper |
| Title & Authors | Introduction | Links |
|---|---|---|
| Hardware Acceleration of LLMs: A comprehensive survey and comparison Nikoletta Koilia, Christoforos Kachris |
Paper | |
| A Survey on Symbolic Knowledge Distillation of Large Language Models Kamal Acharya, Alvaro Velasquez, Houbing Herbert Song |
 |
Paper |
Inference Optimization of Foundation Models on AI Accelerators Youngsuk Park, Kailash Budhathoki, Liangfu Chen, Jonas Kübler, Jiaji Huang, Matthäus Kleindessner, Jun Huan, Volkan Cevher, Yida Wang, George Karypis |
Paper | |
| Survey on Knowledge Distillation for Large Language Models: Methods, Evaluation, and Application Chuanpeng Yang, Wang Lu, Yao Zhu, Yidong Wang, Qian Chen, Chenlong Gao, Bingjie Yan, Yiqiang Chen |
 |
Paper |
| Memory Is All You Need: An Overview of Compute-in-Memory Architectures for Accelerating Large Language Model Inference Christopher Wolters, Xiaoxuan Yang, Ulf Schlichtmann, Toyotaro Suzumura |
 |
Paper |