Releases: ultralytics/yolov5
v7.0 - YOLOv5 SOTA Realtime Instance Segmentation

Our new YOLOv5 v7.0 instance segmentation models are the fastest and most accurate in the world, beating all current SOTA benchmarks. We've made them super simple to train, validate and deploy. See full details in our Release Notes and visit our YOLOv5 Segmentation Colab Notebook for quickstart tutorials.
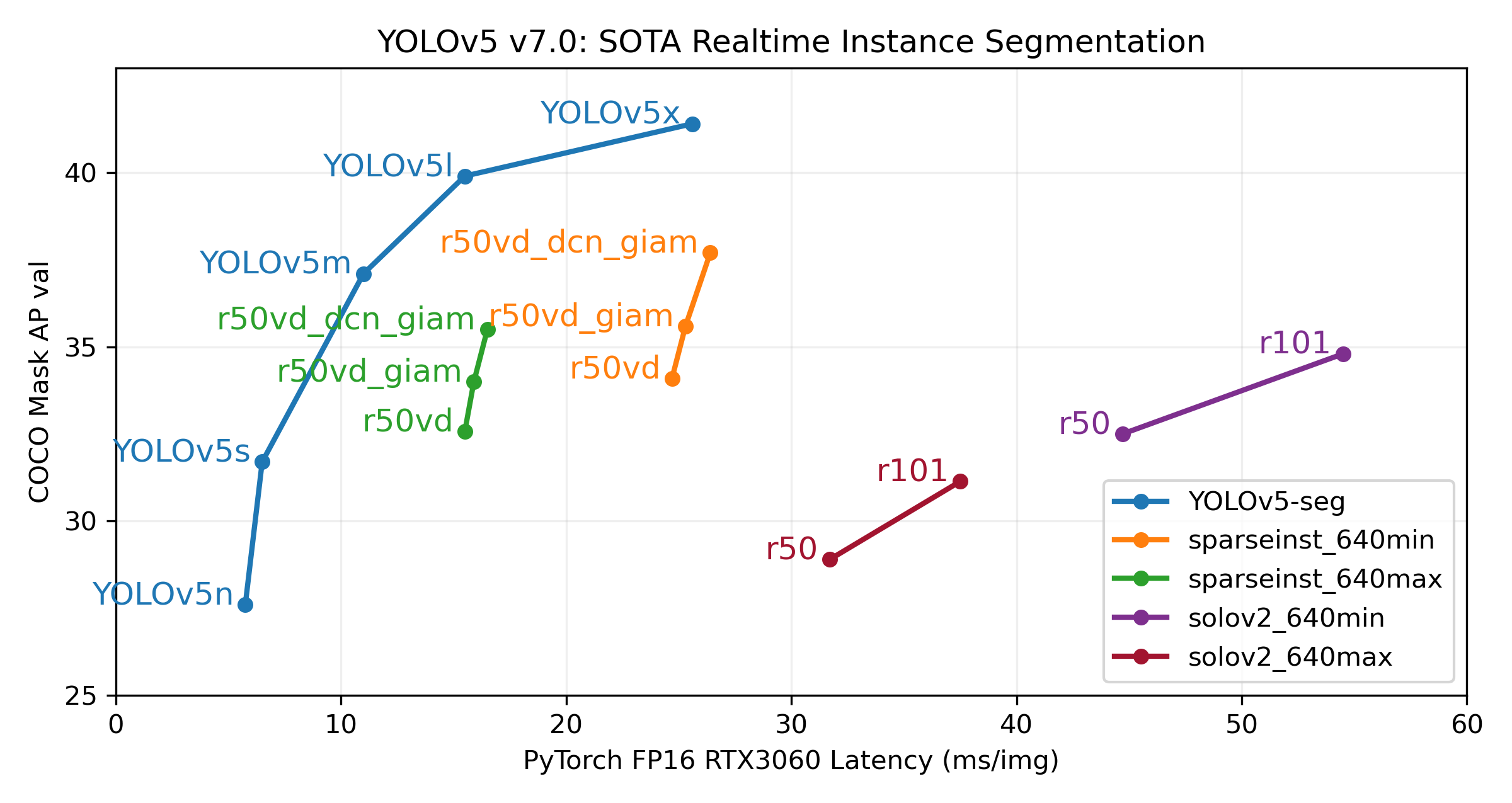
Our primary goal with this release is to introduce super simple YOLOv5 segmentation workflows just like our existing object detection models. The new v7.0 YOLOv5-seg models below are just a start, we will continue to improve these going forward together with our existing detection and classification models. We'd love your feedback and contributions on this effort!
This release incorporates 280 PRs from 41 contributors since our last release in August 2022.
Important Updates
- Segmentation Models ⭐ NEW: SOTA YOLOv5-seg COCO-pretrained segmentation models are now available for the first time (#9052 by @glenn-jocher, @AyushExel and @Laughing-q)
- Paddle Paddle Export: Export any YOLOv5 model (cls, seg, det) to Paddle format with python export.py --include paddle (#9459 by @glenn-jocher)
- YOLOv5 AutoCache: Use
python train.py --cache ramwill now scan available memory and compare against predicted dataset RAM usage. This reduces risk in caching and should help improve adoption of the dataset caching feature, which can significantly speed up training. (#10027 by @glenn-jocher) - Comet Logging and Visualization Integration: Free forever, Comet lets you save YOLOv5 models, resume training, and interactively visualise and debug predictions. (#9232 by @DN6)
New Segmentation Checkpoints
We trained YOLOv5 segmentations models on COCO for 300 epochs at image size 640 using A100 GPUs. We exported all models to ONNX FP32 for CPU speed tests and to TensorRT FP16 for GPU speed tests. We ran all speed tests on Google Colab Pro notebooks for easy reproducibility.
| Model | size (pixels) |
mAPbox 50-95 |
mAPmask 50-95 |
Train time 300 epochs A100 (hours) |
Speed ONNX CPU (ms) |
Speed TRT A100 (ms) |
params (M) |
FLOPs @640 (B) |
|---|---|---|---|---|---|---|---|---|
| YOLOv5n-seg | 640 | 27.6 | 23.4 | 80:17 | 62.7 | 1.2 | 2.0 | 7.1 |
| YOLOv5s-seg | 640 | 37.6 | 31.7 | 88:16 | 173.3 | 1.4 | 7.6 | 26.4 |
| YOLOv5m-seg | 640 | 45.0 | 37.1 | 108:36 | 427.0 | 2.2 | 22.0 | 70.8 |
| YOLOv5l-seg | 640 | 49.0 | 39.9 | 66:43 (2x) | 857.4 | 2.9 | 47.9 | 147.7 |
| YOLOv5x-seg | 640 | 50.7 | 41.4 | 62:56 (3x) | 1579.2 | 4.5 | 88.8 | 265.7 |
- All checkpoints are trained to 300 epochs with SGD optimizer with
lr0=0.01andweight_decay=5e-5at image size 640 and all default settings.
Runs logged to https://wandb.ai/glenn-jocher/YOLOv5_v70_official - Accuracy values are for single-model single-scale on COCO dataset.
Reproduce bypython segment/val.py --data coco.yaml --weights yolov5s-seg.pt - Speed averaged over 100 inference images using a Colab Pro A100 High-RAM instance. Values indicate inference speed only (NMS adds about 1ms per image).
Reproduce bypython segment/val.py --data coco.yaml --weights yolov5s-seg.pt --batch 1 - Export to ONNX at FP32 and TensorRT at FP16 done with
export.py.
Reproduce bypython export.py --weights yolov5s-seg.pt --include engine --device 0 --half
New Segmentation Usage Examples
Train
YOLOv5 segmentation training supports auto-download COCO128-seg segmentation dataset with --data coco128-seg.yaml argument and manual download of COCO-segments dataset with bash data/scripts/get_coco.sh --train --val --segments and then python train.py --data coco.yaml.
# Single-GPU
python segment/train.py --model yolov5s-seg.pt --data coco128-seg.yaml --epochs 5 --img 640
# Multi-GPU DDP
python -m torch.distributed.run --nproc_per_node 4 --master_port 1 segment/train.py --model yolov5s-seg.pt --data coco128-seg.yaml --epochs 5 --img 640 --device 0,1,2,3Val
Validate YOLOv5m-seg accuracy on ImageNet-1k dataset:
bash data/scripts/get_coco.sh --val --segments # download COCO val segments split (780MB, 5000 images)
python segment/val.py --weights yolov5s-seg.pt --data coco.yaml --img 640 # validatePredict
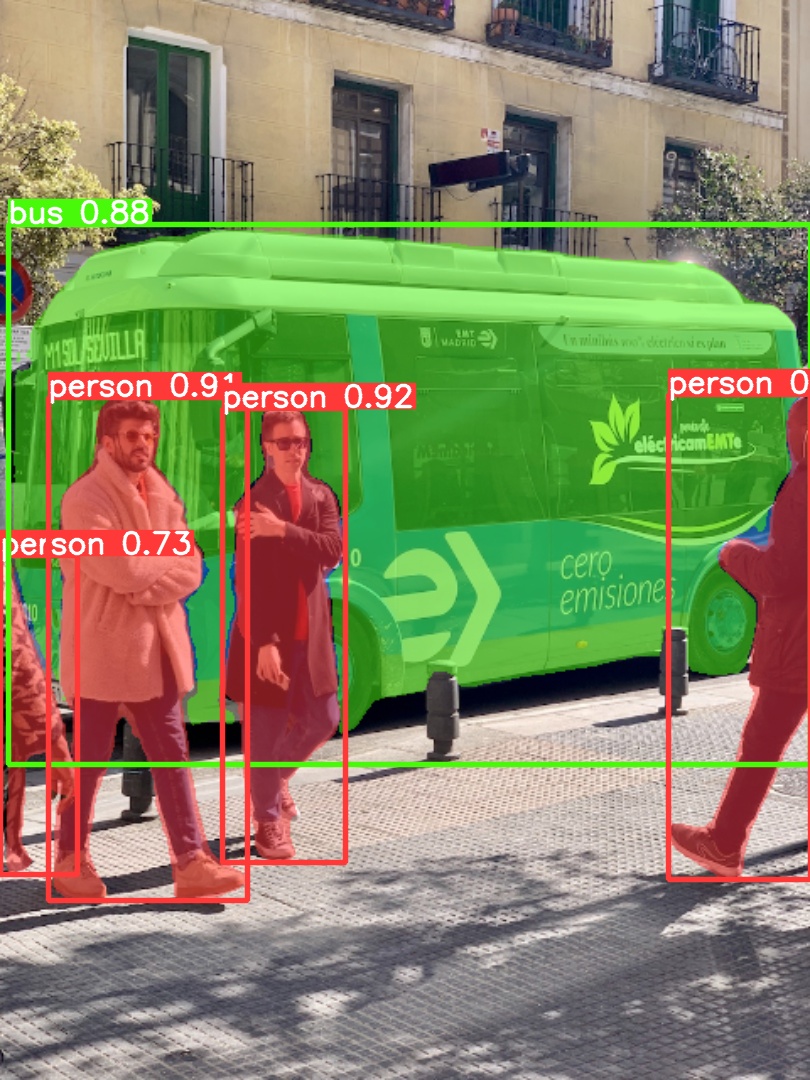
Use pretrained YOLOv5m-seg to predict bus.jpg:
python segment/predict.py --weights yolov5m-seg.pt --data data/images/bus.jpgmodel = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5m-seg.pt') # load from PyTorch Hub (WARNING: inference not yet supported)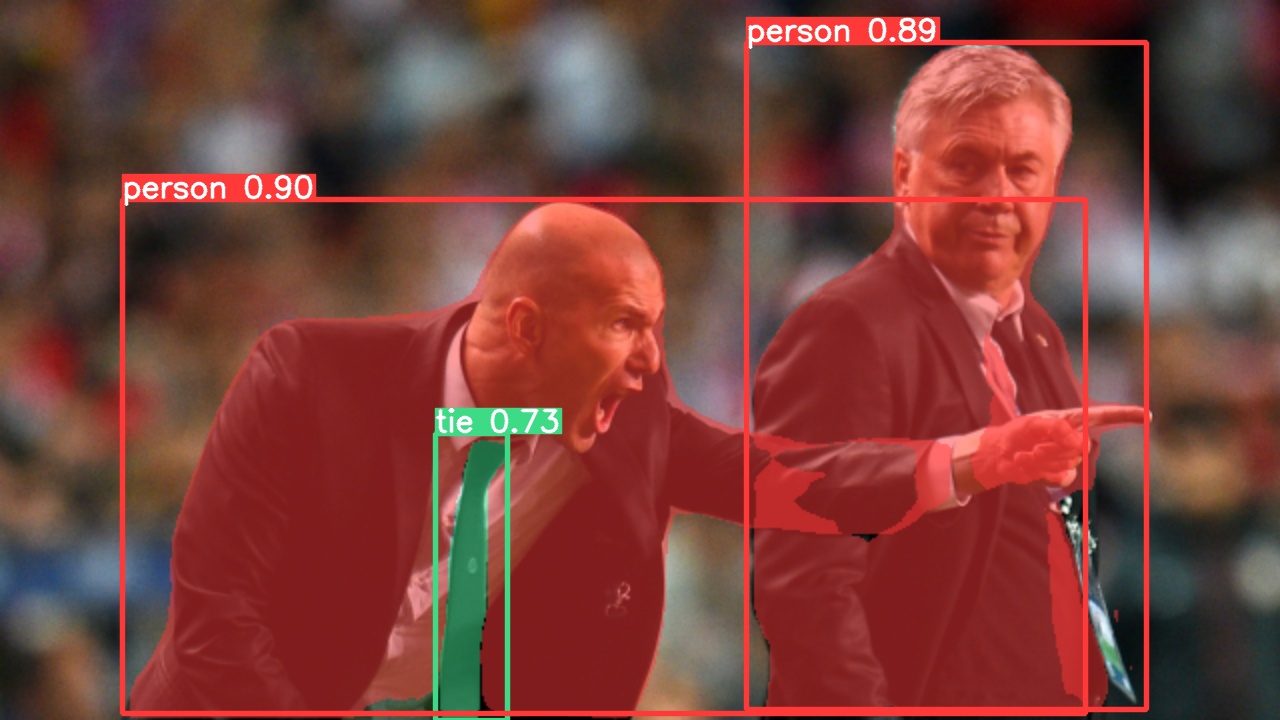 |
 |
|---|
Export
Export YOLOv5s-seg model to ONNX and TensorRT:
python export.py --weights yolov5s-seg.pt --include onnx engine --img 640 --device 0Changelog
- Changes between previous release and this release: v6.2...v7.0
- Changes since this release: v7.0...HEAD
🛠️ New Features and Bug Fixes (280)
* Improve classification comments by @glenn-jocher in https://github.com//pull/8997 * Update `attempt_download(release='v6.2')` by @glenn-jocher in https://github.com//pull/8998 * Update README_cn.md by @KieraMengru0907 in https://github.com//pull/9001 * Update dataset `names` from array to dictionary by @glenn-jocher in https://github.com//pull/9000 * [segment]: Allow inference on dirs and videos by @AyushExel in https://github.com//pull/9003 * DockerHub tag update Usage example by @glenn-jocher in https://github.com//pull/9005 * Add weight `decay` to argparser by @glenn-jocher in https://github.com//pull/9006 * Add glob quotes to detect.py usage example by @glenn-jocher in https://github.com//pull/9007 * Fix TorchScript JSON string key bug by @glenn-jocher in https://github.com//pull/9015 * EMA FP32 assert classification bug fix by @glenn-jocher in https://github.com//pull/9016 * Faster pre-processing for gray image input by @cher-liang in https://github.com//pull/9009 * Improved `Profile()` inference timing by @glenn-jocher in https://github.com//pull/9024 * `torch.empty()` for speed improvements by @glenn-jocher in https://github.com//pull/9025 * Remove unused `time_sync` import by @glenn-jocher in https://github.com//pull/9026 * Add PyTorch Hub classification CI checks by @glenn-jocher in https://github.com//pull/9027 *...Contributors
Assets 49
- 10.3 MB
2022-11-22T00:14:59Z - 15.2 MB
2022-11-22T00:15:04Z - 17.7 MB
2022-11-22T00:15:10Z - 23.8 MB
2022-11-22T00:15:16Z - 110 MB
2022-11-26T03:53:33Z - 48.7 MB
2022-11-26T04:40:38Z - 37.6 MB
2022-12-15T18:06:26Z - 12.9 MB
2022-12-13T19:46:58Z - 174 MB
2022-11-26T03:54:13Z - 297 MB
2022-12-06T22:08:08Z -
2022-11-22T15:23:47Z -
2022-11-22T15:23:47Z - Loading
v6.2 - YOLOv5 Classification Models, Apple M1, Reproducibility, ClearML and Deci.ai integrations

This release incorporates 401 PRs from 41 contributors since our last release in February 2022. It adds Classification training, validation, prediction and export (to all 11 formats), and also provides ImageNet-pretrained YOLOv5m-cls, ResNet (18, 34, 50, 101) and EfficientNet (b0-b3) models.
My main goal with this release is to introduce super simple YOLOv5 classification workflows just like our existing object detection models. The new v6.2 YOLOv5-cls models below are just a start, we will continue to improve these going forward together with our existing detection models. We'd love your contributions on this effort!
Our next release, v6.3 is scheduled for September and will bring official instance segmentation support to YOLOv5, with a major v7.0 release later this year updating architectures across all 3 tasks - classification, detection and segmentation.
Important Updates
- Classification Models ⭐ NEW: YOLOv5-cls ImageNet-pretrained classification models are now available for the first time (#8956 by @glenn-jocher)
- ClearML logging ⭐ NEW: Integration with the open-source experiment tracker ClearML. Installing with
pip install clearmlwill enable the integration and allow users to track every training run in ClearML. This in turn allows users to track and compare runs and even schedule runs remotely. (#8620 by @thepycoder) - Deci.ai optimization ⭐ NEW: Automatically compile and quantize YOLOv5 for better inference performance in one click at Deci (#8956 by @glenn-jocher).
- GPU Export Benchmarks: Benchmark (mAP and speed) all YOLOv5 export formats with
python utils/benchmarks.py --weights yolov5s.pt --device 0for GPU benchmarks or--device cpufor CPU benchmarks (#6963 by @glenn-jocher). - Training Reproducibility: Single-GPU YOLOv5 training with
torch>=1.12.0is now fully reproducible, and a new--seedargument can be used (default seed=0) (#8213 by @AyushExel). - Apple Metal Performance Shader (MPS) Support: MPS support for Apple M1/M2 devices with
--device mps(full functionality is pending torch updates in pytorch/pytorch#77764) (#7878 by @glenn-jocher)
New Classification Checkpoints
We trained YOLOv5-cls classification models on ImageNet for 90 epochs using a 4xA100 instance, and we trained ResNet and EfficientNet models alongside with the same default training settings to compare. We exported all models to ONNX FP32 for CPU speed tests and to TensorRT FP16 for GPU speed tests. We ran all speed tests on Google Colab Pro for easy reproducibility.
| Model | size (pixels) |
accuracy top1 |
accuracy top5 |
Train time 90 epochs 4x A100 (hours) |
Speed ONNX-CPU (ms) |
Speed TensorRT-V100 (ms) |
params (M) |
FLOPs @224 (B) |
|---|---|---|---|---|---|---|---|---|
| YOLOv5n-cls | 224 | 64.6 | 85.4 | 7:59 | 3.3 | 0.5 | 2.5 | 0.5 |
| YOLOv5s-cls | 224 | 71.5 | 90.2 | 8:09 | 6.6 | 0.6 | 5.4 | 1.4 |
| YOLOv5m-cls | 224 | 75.9 | 92.9 | 10:06 | 15.5 | 0.9 | 12.9 | 3.9 |
| YOLOv5l-cls | 224 | 78.0 | 94.0 | 11:56 | 26.9 | 1.4 | 26.5 | 8.5 |
| YOLOv5x-cls | 224 | 79.0 | 94.4 | 15:04 | 54.3 | 1.8 | 48.1 | 15.9 |
| ResNet18 | 224 | 70.3 | 89.5 | 6:47 | 11.2 | 0.5 | 11.7 | 3.7 |
| ResNet34 | 224 | 73.9 | 91.8 | 8:33 | 20.6 | 0.9 | 21.8 | 7.4 |
| ResNet50 | 224 | 76.8 | 93.4 | 11:10 | 23.4 | 1.0 | 25.6 | 8.5 |
| ResNet101 | 224 | 78.5 | 94.3 | 17:10 | 42.1 | 1.9 | 44.5 | 15.9 |
| EfficientNet_b0 | 224 | 75.1 | 92.4 | 13:03 | 12.5 | 1.3 | 5.3 | 1.0 |
| EfficientNet_b1 | 224 | 76.4 | 93.2 | 17:04 | 14.9 | 1.6 | 7.8 | 1.5 |
| EfficientNet_b2 | 224 | 76.6 | 93.4 | 17:10 | 15.9 | 1.6 | 9.1 | 1.7 |
| EfficientNet_b3 | 224 | 77.7 | 94.0 | 19:19 | 18.9 | 1.9 | 12.2 | 2.4 |
- All checkpoints are trained to 90 epochs with SGD optimizer with
lr0=0.001andweight_decay=5e-5at image size 224 and all default settings.
Runs logged to https://wandb.ai/glenn-jocher/YOLOv5-Classifier-v6-2 - Accuracy values are for single-model single-scale on ImageNet-1k dataset.
Reproduce bypython classify/val.py --data ../datasets/imagenet --img 224 - Speed averaged over 100 inference images using a Colab Pro V100 High-RAM instance.
Reproduce bypython classify/val.py --data ../datasets/imagenet --img 224 --batch 1 - Export to ONNX at FP32 and TensorRT at FP16 done with `export....
v6.1 - TensorRT, TensorFlow Edge TPU and OpenVINO Export and Inference
This release incorporates many new features and bug fixes (271 PRs from 48 contributors) since our last release in October 2021. It adds TensorRT, Edge TPU and OpenVINO support, and provides retrained models at --batch-size 128 with new default one-cycle linear LR scheduler. YOLOv5 now officially supports 11 different formats, not just for export but for inference (both detect.py and PyTorch Hub), and validation to profile mAP and speed results after export.
| Format | export.py --include |
Model |
|---|---|---|
| PyTorch | - | yolov5s.pt |
| TorchScript | torchscript |
yolov5s.torchscript |
| ONNX | onnx |
yolov5s.onnx |
| OpenVINO | openvino |
yolov5s_openvino_model/ |
| TensorRT | engine |
yolov5s.engine |
| CoreML | coreml |
yolov5s.mlmodel |
| TensorFlow SavedModel | saved_model |
yolov5s_saved_model/ |
| TensorFlow GraphDef | pb |
yolov5s.pb |
| TensorFlow Lite | tflite |
yolov5s.tflite |
| TensorFlow Edge TPU | edgetpu |
yolov5s_edgetpu.tflite |
| TensorFlow.js | tfjs |
yolov5s_web_model/ |
Usage examples (ONNX shown):
Export: python export.py --weights yolov5s.pt --include onnx
Detect: python detect.py --weights yolov5s.onnx
PyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s.onnx')
Validate: python val.py --weights yolov5s.onnx
Visualize: https://netron.appImportant Updates
- TensorRT support: TensorFlow, Keras, TFLite, TF.js model export now fully integrated using
python export.py --include saved_model pb tflite tfjs(#5699 by @imyhxy) - Tensorflow Edge TPU support ⭐ NEW: New smaller YOLOv5n (1.9M params) model below YOLOv5s (7.5M params), exports to 2.1 MB INT8 size, ideal for ultralight mobile solutions. (#3630 by @zldrobit)
- OpenVINO support: YOLOv5 ONNX models are now compatible with both OpenCV DNN and ONNX Runtime (#6057 by @glenn-jocher).
- Export Benchmarks: Benchmark (mAP and speed) all YOLOv5 export formats with
python utils/benchmarks.py --weights yolov5s.pt. Currently operates on CPU, future updates will implement GPU support. (#6613 by @glenn-jocher). - Architecture: no changes
- Hyperparameters: minor change
- hyp-scratch-large.yaml
lrfreduced from 0.2 to 0.1 (#6525 by @glenn-jocher).
- hyp-scratch-large.yaml
- Training: Default Learning Rate (LR) scheduler updated
- One-cycle with cosine replace with one-cycle linear for improved results (#6729 by @glenn-jocher).
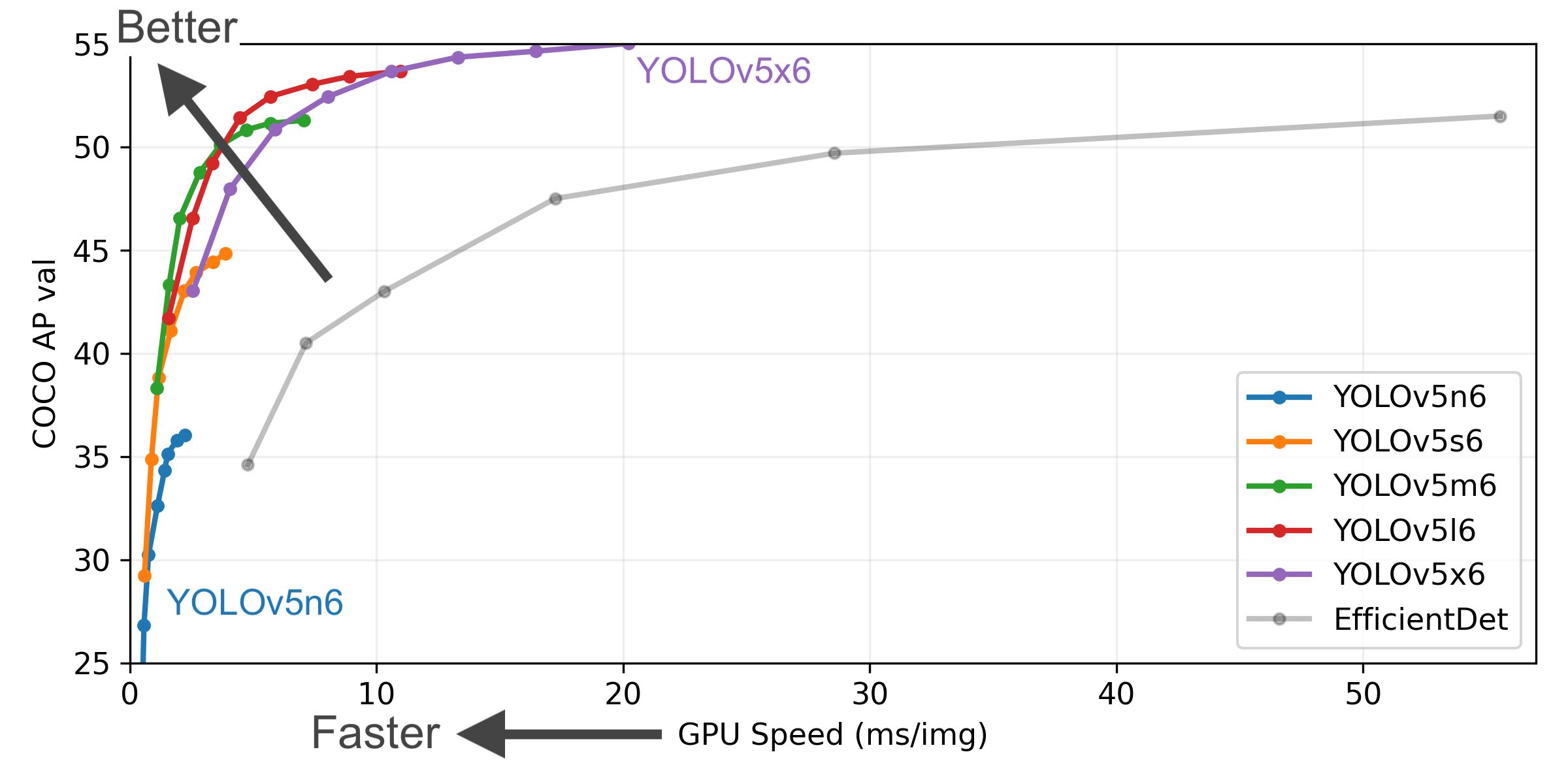
New Results
All model trainings logged to https://wandb.ai/glenn-jocher/YOLOv5_v61_official
YOLOv5-P5 640 Figure (click to expand)
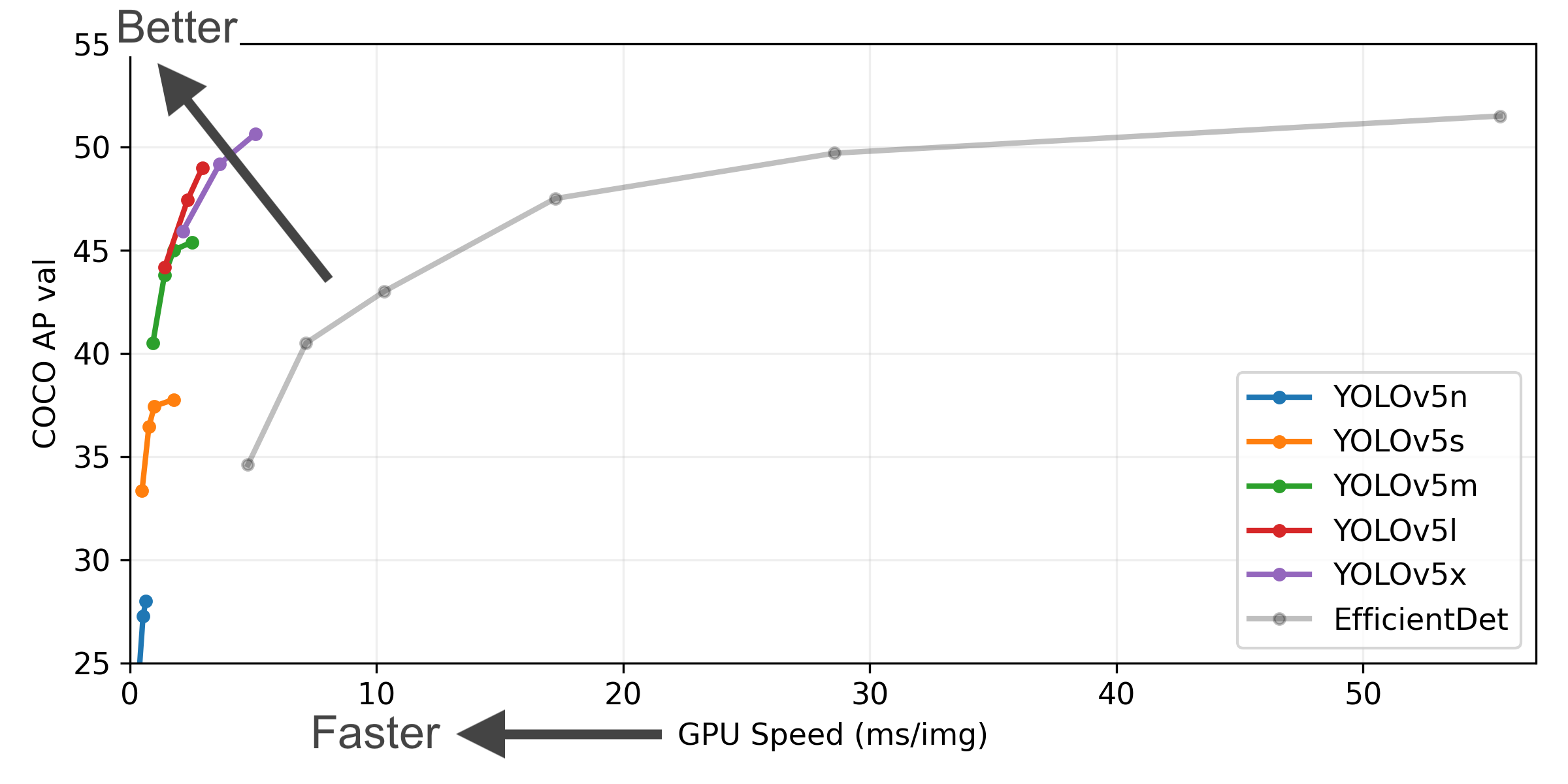
Figure Notes (click to expand)
- COCO AP val denotes mAP@0.5:0.95 metric measured on the 5000-image COCO val2017 dataset over various inference sizes from 256 to 1536.
- GPU Speed measures average inference time per image on COCO val2017 dataset using a AWS p3.2xlarge V100 instance at batch-size 32.
- EfficientDet data from google/automl at batch size 8.
- Reproduce by
python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5n6.pt yolov5s6.pt yolov5m6.pt yolov5l6.pt yolov5x6.pt
Example YOLOv5l before and after metrics:
| YOLOv5l Large |
size (pixels) |
mAPval 0.5:0.95 |
mAPval 0.5 |
Speed CPU b1 (ms) |
Speed V100 b1 (ms) |
Speed V100 b32 (ms) |
params (M) |
FLOPs @640 (B) |
|---|---|---|---|---|---|---|---|---|
| v5.0 | 640 | 48.2 | 66.9 | 457.9 | 11.6 | 2.8 | 47.0 | 115.4 |
| v6.0 (previous) | 640 | 48.8 | 67.2 | 424.5 | 10.9 | 2.7 | 46.5 | 109.1 |
| v6.1 (this release) | 640 | 49.0 | 67.3 | 430.0 | 10.1 | 2.7 | 46.5 | 109.1 |
Pretrained Checkpoints
| Model | size (pixels) |
mAPval 0.5:0.95 |
mAPval 0.5 |
Speed CPU b1 (ms) |
Speed V100 b1 (ms) |
Speed V100 b32 (ms) |
params (M) |
FLOPs @640 (B) |
|---|---|---|---|---|---|---|---|---|
| YOLOv5n | 640 | 28.0 | 45.7 | 45 | 6.3 | 0.6 | 1.9 | 4.5 |
| YOLOv5s | 640 | 37.4 | 56.8 | 98 | 6.4 | 0.9 | 7.2 | 16.5 |
| YOLOv5m | 640 | 45.4 | 64.1 | 224 | 8.2 | 1.7 | 21.2 | 49.0 |
| YOLOv5l | 640 | 49.0 | 67.3 | 430 | 10.1 | 2.7 | 46.5 | 109.1 |
| YOLOv5x | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 |
| YOLOv5n6 | 1280 | 36.0 | 54.4 | 153 | 8.1 | 2.1 | 3.2 | 4.6 |
| YOLOv5s6 | 1280 | 44.8 | 63.7 | 385 | 8.2 | 3.6 | 12.6 | 16.8 |
| YOLOv5m6 | 1280 | 51.3 | 69.3 | 887 | 11.1 | 6.8 | 35.7 | 50.0 |
| YOLOv5l6 | 1280 | 53.7 | 71.3 | 1784 | 15.8 | 10.5 | 76.8 | 111.4 |
| YOLOv5x6 + TTA |
1280 1536 |
55.0 55.8 |
72.7 72.7 |
3136 - |
26.2 - |
19.4 - |
140.7 - |
209.8 - |
Table Notes (click to expand)
- All checkpoints are trained to 300 epochs with default settings. Nano and Small models use hyp.scratch-low.yaml hyps, all others use hyp.scratch-high.yaml.
- mAPval values are for single-model single-scale on COCO val2017 dataset.
Reproduce bypython val.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65 - Speed averaged over COCO val images using a AWS p3.2xlarge instance. NMS times (~1 ms/img) not included.
Reproduce bypython val.py --data coco.yaml --img 640 --task speed --batch 1 - TTA Test Time Augmentation includes reflection and scale augmentations.
Reproduce bypython val.py --data coco.yaml --img 1536 --iou 0.7 --augment
Changelog
Changes between previous release and this release: v6.0...v6.1
Changes since this release: v6.1...HEAD
New Features and Bug Fixes (271)
- fix
tfconversion in new v6 models by @YoniChechik in #5153 - Use YOLOv5n for CI testing by @glenn-jocher in #5154
- Update stale.yml by @glenn-jocher in #5156
- Check
'onnxruntime-gpu' if torch.has_cudaby @glenn-jocher in #5087 - Add class filtering to
LoadImagesAndLabels()dataloader by @glenn-jocher in #5172 - W&B: fix dpp with wandb disabled by @AyushExel in #5163
- Update autodownload fallbacks to v6.0 assets by @glenn-jocher in #5177
- W&B: DDP fix by @AyushExel in #5176
- Adjust legend labels for classes without instances by @NauchtanRobotics in #5174
- Improved check_suffix() robustness to
''and""by @glenn-jocher in #5192 - Highlight contributors in README by @glenn-jocher in https://github.com/ultralytics/yolov5/pul...
v6.0 - YOLOv5n 'Nano' models, Roboflow integration, TensorFlow export, OpenCV DNN support
This release incorporates many new features and bug fixes (465 PRs from 73 contributors) since our last release v5.0 in April, brings architecture tweaks, and also introduces new P5 and P6 'Nano' models: YOLOv5n and YOLOv5n6. Nano models maintain the YOLOv5s depth multiple of 0.33 but reduce the YOLOv5s width multiple from 0.50 to 0.25, resulting in ~75% fewer parameters, from 7.5M to 1.9M, ideal for mobile and CPU solutions.
Example usage:
python detect.py --weights yolov5n.pt --img 640 # Nano P5 model trained at --img 640 (28.4 mAP@0.5:0.95)
python detect.py --weights yolov5n6.pt --img 1280 # Nano P6 model trained at --img 1280 (34.0 mAP0.5:0.95)Important Updates
-
Roboflow Integration ⭐ NEW: Train YOLOv5 models directly on any Roboflow dataset with our new integration! (#4975 by @Jacobsolawetz)
-
YOLOv5n 'Nano' models ⭐ NEW: New smaller YOLOv5n (1.9M params) model below YOLOv5s (7.5M params), exports to 2.1 MB INT8 size, ideal for ultralight mobile solutions. (#5027 by @glenn-jocher)
-
TensorFlow and Keras Export: TensorFlow, Keras, TFLite, TF.js model export now fully integrated using
python export.py --include saved_model pb tflite tfjs(#1127 by @zldrobit) -
OpenCV DNN: YOLOv5 ONNX models are now compatible with both OpenCV DNN and ONNX Runtime (#4833 by @SamFC10).
-
Model Architecture: Updated backbones are slightly smaller, faster and more accurate.
- Replacement of
Focus()with an equivalentConv(k=6, s=2, p=2)layer (#4825 by @thomasbi1) for improved exportability - New
SPPF()replacement forSPP()layer for reduced ops (#4420 by @glenn-jocher) - Reduction in P3 backbone layer
C3()repeats from 9 to 6 for improved speeds - Reorder places
SPPF()at end of backbone - Reintroduction of shortcut in the last
C3()backbone layer - Updated hyperparameters with increased mixup and copy-paste augmentation
- Replacement of
New Results
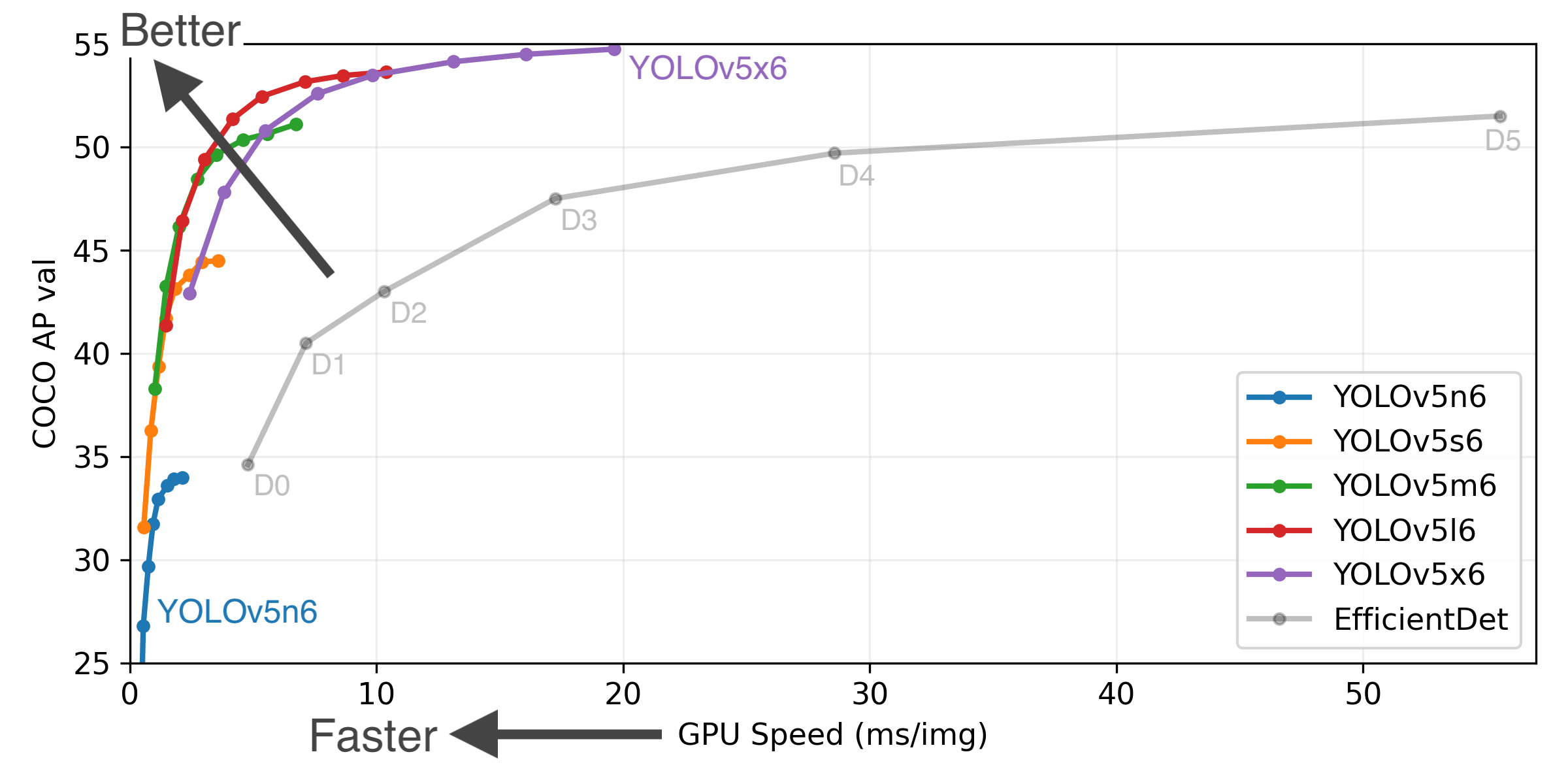
YOLOv5-P5 640 Figure (click to expand)
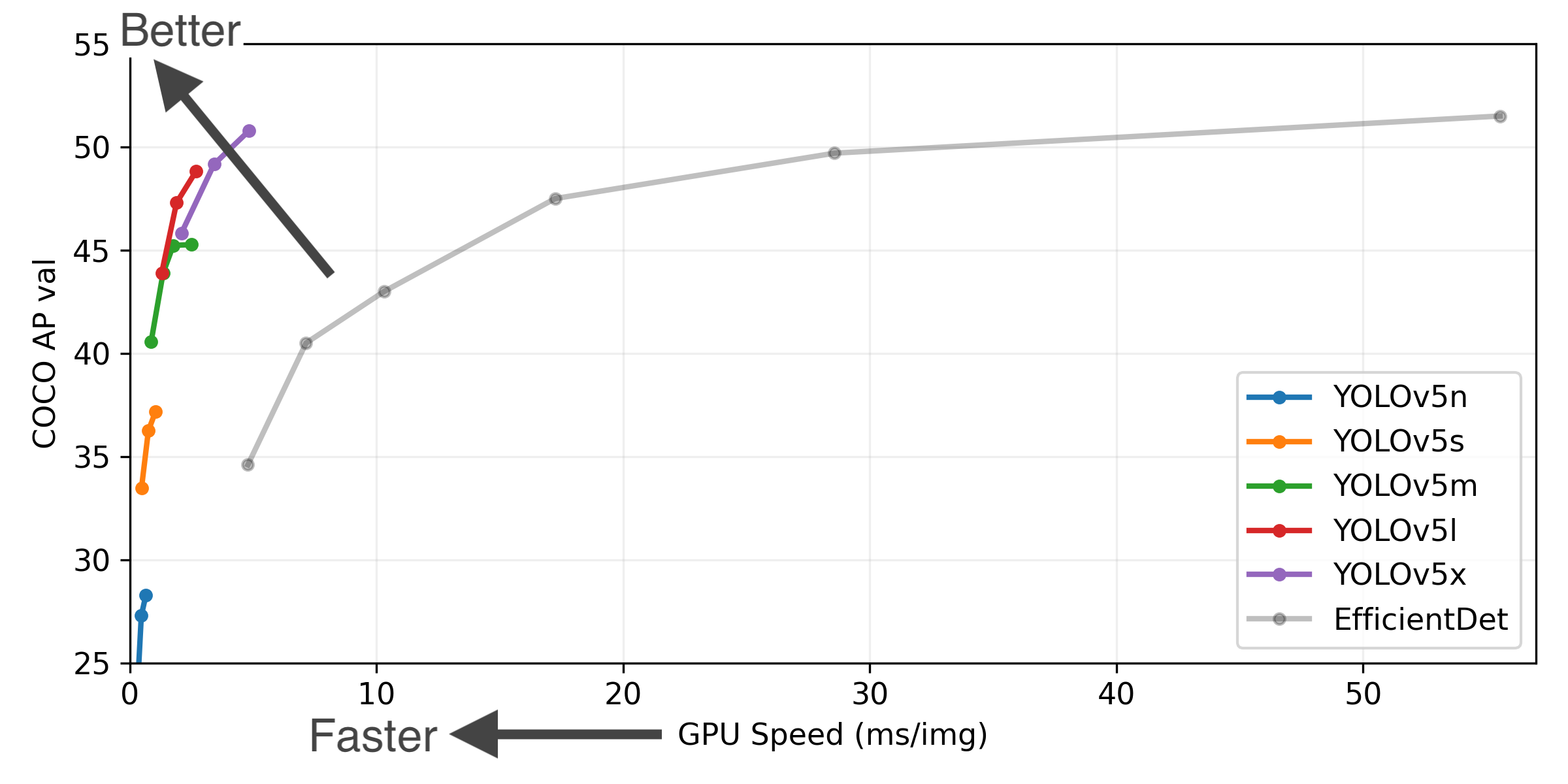
Figure Notes (click to expand)
- COCO AP val denotes mAP@0.5:0.95 metric measured on the 5000-image COCO val2017 dataset over various inference sizes from 256 to 1536.
- GPU Speed measures average inference time per image on COCO val2017 dataset using a AWS p3.2xlarge V100 instance at batch-size 32.
- EfficientDet data from google/automl at batch size 8.
- Reproduce by
python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5n6.pt yolov5s6.pt yolov5m6.pt yolov5l6.pt yolov5x6.pt
mAP improves from +0.3% to +1.1% across all models, and ~5% FLOPs reduction produces slight speed improvements and a reduced CUDA memory footprint. Example YOLOv5l before and after metrics:
| YOLOv5l Large |
size (pixels) |
mAPval 0.5:0.95 |
mAPval 0.5 |
Speed CPU b1 (ms) |
Speed V100 b1 (ms) |
Speed V100 b32 (ms) |
params (M) |
FLOPs @640 (B) |
|---|---|---|---|---|---|---|---|---|
| v5.0 (previous) | 640 | 48.2 | 66.9 | 457.9 | 11.6 | 2.8 | 47.0 | 115.4 |
| v6.0 (this release) | 640 | 48.8 | 67.2 | 424.5 | 10.9 | 2.7 | 46.5 | 109.1 |
Pretrained Checkpoints
| Model | size (pixels) |
mAPval 0.5:0.95 |
mAPval 0.5 |
Speed CPU b1 (ms) |
Speed V100 b1 (ms) |
Speed V100 b32 (ms) |
params (M) |
FLOPs @640 (B) |
|---|---|---|---|---|---|---|---|---|
| YOLOv5n | 640 | 28.4 | 46.0 | 45 | 6.3 | 0.6 | 1.9 | 4.5 |
| YOLOv5s | 640 | 37.2 | 56.0 | 98 | 6.4 | 0.9 | 7.2 | 16.5 |
| YOLOv5m | 640 | 45.2 | 63.9 | 224 | 8.2 | 1.7 | 21.2 | 49.0 |
| YOLOv5l | 640 | 48.8 | 67.2 | 430 | 10.1 | 2.7 | 46.5 | 109.1 |
| YOLOv5x | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 |
| YOLOv5n6 | 1280 | 34.0 | 50.7 | 153 | 8.1 | 2.1 | 3.2 | 4.6 |
| YOLOv5s6 | 1280 | 44.5 | 63.0 | 385 | 8.2 | 3.6 | 16.8 | 12.6 |
| YOLOv5m6 | 1280 | 51.0 | 69.0 | 887 | 11.1 | 6.8 | 35.7 | 50.0 |
| YOLOv5l6 | 1280 | 53.6 | 71.6 | 1784 | 15.8 | 10.5 | 76.8 | 111.4 |
| YOLOv5x6 + TTA |
1280 1536 |
54.7 55.4 |
72.4 72.3 |
3136 - |
26.2 - |
19.4 - |
140.7 - |
209.8 - |
Table Notes (click to expand)
- All checkpoints are trained to 300 epochs with default settings. Nano models use hyp.scratch-low.yaml hyperparameters, all others use hyp.scratch-high.yaml.
- mAPval values are for single-model single-scale on COCO val2017 dataset.
Reproduce bypython val.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65 - Speed averaged over COCO val images using a AWS p3.2xlarge instance. NMS times (~1 ms/img) not included.
Reproduce bypython val.py --data coco.yaml --img 640 --conf 0.25 --iou 0.45 - TTA Test Time Augmentation includes reflection and scale augmentations.
Reproduce bypython val.py --data coco.yaml --img 1536 --iou 0.7 --augment
Changelog
Changes between previous release and this release: v5.0...v6.0
Changes since this release: v6.0...HEAD
New Features and Bug Fixes (465)
- YOLOv5 v5.0 Release patch 1 by @glenn-jocher in #2764
- Flask REST API Example by @robmarkcole in #2732
- ONNX Simplifier by @glenn-jocher in #2815
- YouTube Bug Fix by @glenn-jocher in #2818
- PyTorch Hub cv2 .save() .show() bug fix by @glenn-jocher in #2831
- Create FUNDING.yml by @glenn-jocher in #2832
- Update FUNDING.yml by @glenn-jocher in #2833
- Fix ONNX dynamic axes export support with onnx simplifier, make onnx simplifier optional by @timstokman in #2856
- Update increment_path() to handle file paths by @glenn-jocher in #2867
- Detection cropping+saving feature addition for detect.py and PyTorch Hub by @Ab-Abdurrahman in #2827
- Implement yaml.safe_load() by @glenn-jocher in #2876
- Cleanup load_image() by @JoshSong in #2871
- bug fix: switched rows and cols for correct detections in confusion matrix by @MichHeilig in #2883
- VisDrone2019-DET Dataset Auto-Download by @glenn-jocher in #2882
- Uppercase model filenames enabled by @r-blmnr in #2890
- ACON activation function by @glenn-jocher in #2893
- Explicit opt function arguments by @fcakyon in #2817
- Update yolo.py by @glenn-jocher in #2899
- Update google_utils.py by @glenn-jocher in #2900
- Add detect.py --hide-conf --hide-labels --line-thickness options by @Ashafix in #2658
- Default optimize_for_mobile() on TorchScript models by @glenn-jocher in #2908
- Update export.py onnx -> ct print bug fix by @glenn-jocher in #2909
- Update export.py for 2 dry runs by @glenn-jocher in #2910
- Add file_size() function by @glenn-jocher in #2911
- Update download() for tar.gz files by @glenn-jocher in #2919
- Update visdrone.yaml bug fix by @glenn-jocher in #2921
- changed default value of hide label argument to False by @albinxavi...
Contributors
Assets 30
v5.0 - YOLOv5-P6 1280 models, AWS, Supervise.ly and YouTube integrations
This release implements YOLOv5-P6 models and retrained YOLOv5-P5 models. All model sizes YOLOv5s/m/l/x are now available in both P5 and P6 architectures:
- YOLOv5-P5 models (same architecture as v4.0 release): 3 output layers P3, P4, P5 at strides 8, 16, 32, trained at
--img 640
python detect.py --weights yolov5s.pt # P5 models
yolov5m.pt
yolov5l.pt
yolov5x.pt- YOLOv5-P6 models: 4 output layers P3, P4, P5, P6 at strides 8, 16, 32, 64 trained at
--img 1280
python detect.py --weights yolov5s6.pt # P6 models
yolov5m6.pt
yolov5l6.pt
yolov5x6.ptExample usage:
# Command Line
python detect.py --weights yolov5m.pt --img 640 # P5 model at 640
python detect.py --weights yolov5m6.pt --img 640 # P6 model at 640
python detect.py --weights yolov5m6.pt --img 1280 # P6 model at 1280# PyTorch Hub
model = torch.hub.load('ultralytics/yolov5', 'yolov5m6') # P6 model
results = model(imgs, size=1280) # inference at 1280Notable Updates
- YouTube Inference: Direct inference from YouTube videos, i.e.
python detect.py --source 'https://youtu.be/NUsoVlDFqZg'. Live streaming videos and normal videos supported. (#2752) - AWS Integration: Amazon AWS integration and new AWS Quickstart Guide for simple EC2 instance YOLOv5 training and resuming of interrupted Spot instances. (#2185)
- Supervise.ly Integration: New integration with the Supervisely Ecosystem for training and deploying YOLOv5 models with Supervise.ly (#2518)
- Improved W&B Integration: Allows saving datasets and models directly to Weights & Biases. This allows for --resume directly from W&B (useful for temporary environments like Colab), as well as enhanced visualization tools. See this blog by @AyushExel for details. (#2125)
Updated Results
P6 models include an extra P6/64 output layer for detection of larger objects, and benefit the most from training at higher resolution. For this reason we trained all P5 models at 640, and all P6 models at 1280.

YOLOv5-P5 640 Figure (click to expand)
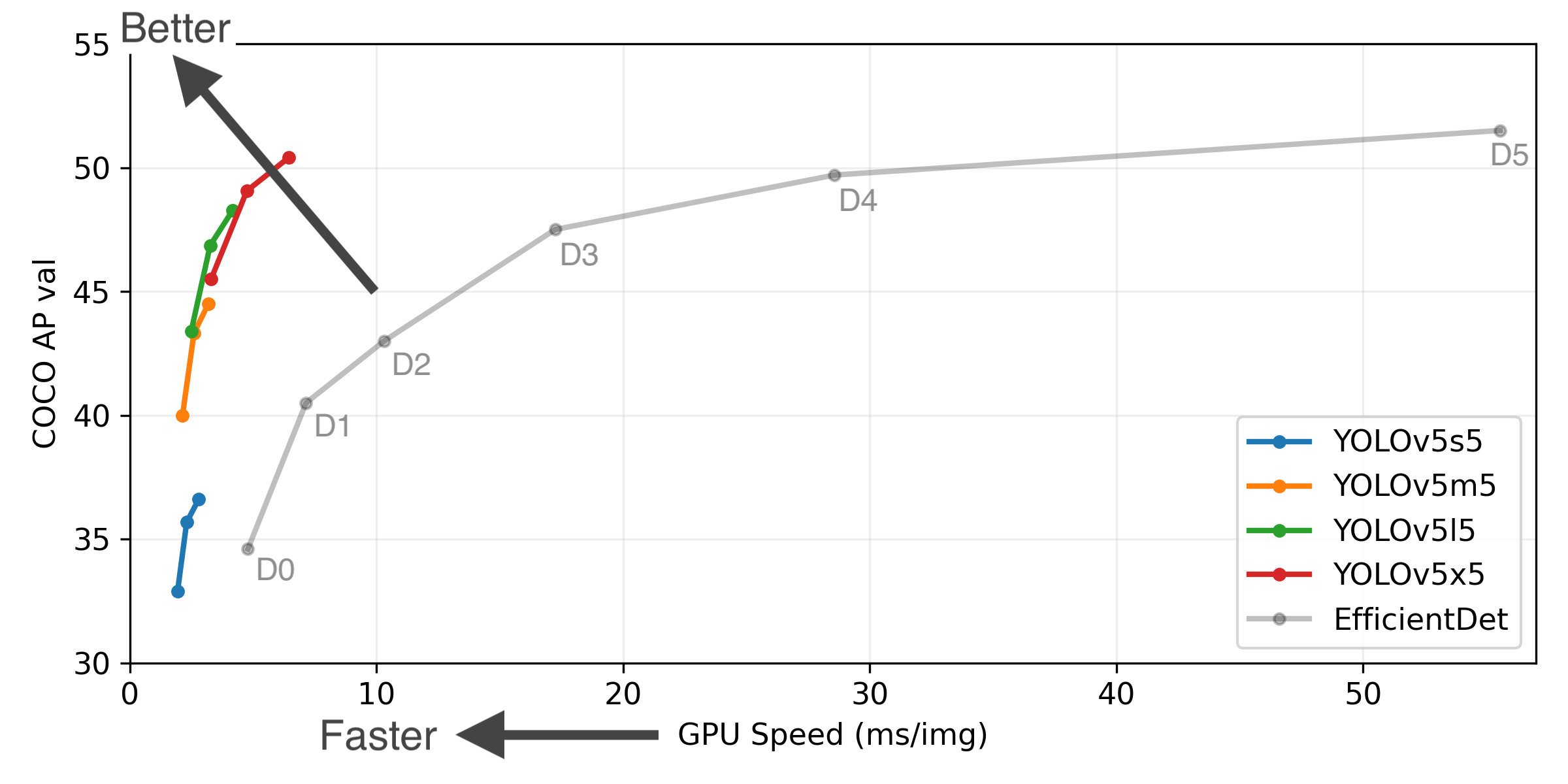
Figure Notes (click to expand)
- GPU Speed measures end-to-end time per image averaged over 5000 COCO val2017 images using a V100 GPU with batch size 32, and includes image preprocessing, PyTorch FP16 inference, postprocessing and NMS.
- EfficientDet data from google/automl at batch size 8.
- Reproduce by
python test.py --task study --data coco.yaml --iou 0.7 --weights yolov5s6.pt yolov5m6.pt yolov5l6.pt yolov5x6.pt
- April 11, 2021: v5.0 release: YOLOv5-P6 1280 models, AWS, Supervise.ly and YouTube integrations.
- January 5, 2021: v4.0 release: nn.SiLU() activations, Weights & Biases logging, PyTorch Hub integration.
- August 13, 2020: v3.0 release: nn.Hardswish() activations, data autodownload, native AMP.
- July 23, 2020: v2.0 release: improved model definition, training and mAP.
Pretrained Checkpoints
| Model | size (pixels) |
mAPval 0.5:0.95 |
mAPtest 0.5:0.95 |
mAPval 0.5 |
Speed V100 (ms) |
params (M) |
FLOPS 640 (B) |
|
|---|---|---|---|---|---|---|---|---|
| YOLOv5s | 640 | 36.7 | 36.7 | 55.4 | 2.0 | 7.3 | 17.0 | |
| YOLOv5m | 640 | 44.5 | 44.5 | 63.1 | 2.7 | 21.4 | 51.3 | |
| YOLOv5l | 640 | 48.2 | 48.2 | 66.9 | 3.8 | 47.0 | 115.4 | |
| YOLOv5x | 640 | 50.4 | 50.4 | 68.8 | 6.1 | 87.7 | 218.8 | |
| YOLOv5s6 | 1280 | 43.3 | 43.3 | 61.9 | 4.3 | 12.7 | 17.4 | |
| YOLOv5m6 | 1280 | 50.5 | 50.5 | 68.7 | 8.4 | 35.9 | 52.4 | |
| YOLOv5l6 | 1280 | 53.4 | 53.4 | 71.1 | 12.3 | 77.2 | 117.7 | |
| YOLOv5x6 | 1280 | 54.4 | 54.4 | 72.0 | 22.4 | 141.8 | 222.9 | |
| YOLOv5x6 TTA | 1280 | 55.0 | 55.0 | 72.0 | 70.8 | - | - |
Table Notes (click to expand)
- APtest denotes COCO test-dev2017 server results, all other AP results denote val2017 accuracy.
- AP values are for single-model single-scale unless otherwise noted. Reproduce mAP by
python test.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65 - SpeedGPU averaged over 5000 COCO val2017 images using a GCP n1-standard-16 V100 instance, and includes FP16 inference, postprocessing and NMS. Reproduce speed by
python test.py --data coco.yaml --img 640 --conf 0.25 --iou 0.45 - All checkpoints are trained to 300 epochs with default settings and hyperparameters (no autoaugmentation).
- Test Time Augmentation (TTA) includes reflection and scale augmentation. Reproduce TTA by
python test.py --data coco.yaml --img 1536 --iou 0.7 --augment
Changelog
Changes between previous release and this release: v4.0...v5.0
Changes since this release: v5.0...HEAD
Click a section below to expand details:
Implemented Enhancements (26)
- Return predictions as json #2703
- Single channel image training? #2609
- Images in MPO Format are considered corrupted #2446
- Improve Validation Visualization #2384
- Add ASFF (three fuse feature layers) int the Head for V5(s,m,l,x) #2348
- Dear author, can you provide a visualization scheme for YOLOV5 feature graphs during detect.py? Thank you! #2259
- Dataloader #2201
- Update Train Custom Data wiki page #2187
- Multi-class NMS #2162
- 💡Idea: Mosaic cropping using segmentation labels #2151
- Improving Confusion Matrix Interpretability: FP and FN vectors should be switched to align with Predicted and True axis #2071
- Interpreting model YoloV5 by Grad-cam #2065
- Output optimal confidence threshold based on PR curve #2048
- is it valuable that add --cache-images option to detect.py? #2004
- I want to change the anchor box to anchor circles, where do you think the change to be made ? #1987
- Support for imgaug #1954
- Any plan for Knowledge Distillation? #1762
- Is there a wasy to run detections on a video/webcam/rtrsp, etc EVERY x SECONDS? #1742
- Can yolov5 support rotated target detection? #1728
- Deploying yolov5 to TorchServe (GPU compatible) #1681
- Why diffrent colors of bboxs? #1638
- Yet another export yolov5 models to ONNX and inference with TensorRT #1597
- Rerange the blocks of Focus Layer into
row majorto be compatible with tensorflowSpaceToDepth#413 - YouTube Livestream Detection #2752 (ben-milanko)
- Add TransformerLayer, TransformerBlock, C3TR modules #2333 (dingyiwei)
- I...
Contributors
Assets 11
v4.0 - nn.SiLU() activations, Weights & Biases logging, PyTorch Hub integration
This release implements two architecture changes to YOLOv5, as well as various bug fixes and performance improvements.
Breaking Changes
- nn.SiLU() activations replace nn.LeakyReLU(0.1) and nn.Hardswish() activations used in previous versions. nn.SiLU() was introduced in PyTorch 1.7.0 (https://pytorch.org/docs/stable/generated/torch.nn.SiLU.html), and due to the recent timeframe certain export pipelines may be temporarily unavailable (CoreML possibly) without updates to the associated tools (i.e. coremltools).
Bug Fixes
- Multi-GPU --resume #1810
- leaf Variable inplace bug fix #1759
- Various additional bug fixes contained in PRs #1235 through #1837
Added Functionality
- Weights & Biases (W&B) Feature Addition #1235
- Utils reorganization #1392
- PyTorch Hub and autoShape update #1415
- W&B artifacts feature addition #1712
- Various additional feature additions contained in PRs #1235 through #1837
Updated Results
Latest models are all slightly smaller to due removal of one convolution within each bottleneck, which have been renamed as C3() modules now in light of the 3 I/O convolutions each one does vs the 4 in the standard CSP bottleneck. The previous manual concatenation and LeakyReLU(0.1) activations have both removed, simplifying the architecture, reducing parameter count, and better exploiting the .fuse() operation at inference time.
nn.SiLU() activations replace nn.LeakyReLU(0.1) and nn.Hardswish() activations throughout the model, simplifying the architecture as we now only have one single activation function used everywhere rather than the two types before.
In general the changes result in smaller models (89.0M params -> 87.7M YOLOv5x), faster inference times (6.9ms -> 6.0ms), and improved mAP (49.2 -> 50.1) for all models except YOLOv5s, which reduced mAP slightly (37.0 -> 36.8). In general the largest models benefit the most from this update. YOLOv5x in particular is now above 50.0 mAP at --img-size 640, which may be the first time this is possible at 640 resolution for any architecture I'm aware of (correct me if I'm wrong though).
 ** GPU Speed measures end-to-end time per image averaged over 5000 COCO val2017 images using a V100 GPU with batch size 32, and includes image preprocessing, PyTorch FP16 inference, postprocessing and NMS. EfficientDet data from google/automl at batch size 8.
** GPU Speed measures end-to-end time per image averaged over 5000 COCO val2017 images using a V100 GPU with batch size 32, and includes image preprocessing, PyTorch FP16 inference, postprocessing and NMS. EfficientDet data from google/automl at batch size 8.
Pretrained Checkpoints
| Model | size | APval | APtest | AP50 | SpeedV100 | FPSV100 | params | GFLOPS | |
|---|---|---|---|---|---|---|---|---|---|
| YOLOv5s | 640 | 36.8 | 36.8 | 55.6 | 2.2ms | 455 | 7.3M | 17.0 | |
| YOLOv5m | 640 | 44.5 | 44.5 | 63.1 | 2.9ms | 345 | 21.4M | 51.3 | |
| YOLOv5l | 640 | 48.1 | 48.1 | 66.4 | 3.8ms | 264 | 47.0M | 115.4 | |
| YOLOv5x | 640 | 50.1 | 50.1 | 68.7 | 6.0ms | 167 | 87.7M | 218.8 | |
| YOLOv5x + TTA | 832 | 51.9 | 51.9 | 69.6 | 24.9ms | 40 | 87.7M | 1005.3 |
v3.1 - Bug Fixes and Performance Improvements
This release aggregates various minor bug fixes and performance improvements since the main v3.0 release and incorporates PyTorch 1.7.0 compatibility updates. v3.1 models share weights with v3.0 models but contain minor module updates (inplace fields for nn.Hardswish() activations) for native PyTorch 1.7.0 compatibility. For PyTorch 1.7.0 release updates see https://github.com/pytorch/pytorch/releases/tag/v1.7.0.
Breaking Changes
- 'giou' hyperparameter has been renamed to 'box' to better reflect a criteria-agnostic regression loss term (#1120)
Bug Fixes
- PyTorch 1.7 compatibility update.
torch>=1.6.0required,torch>=1.7.0recommended (#1233) - GhostConv module bug fix (#1176)
- Rectangular padding min stride bug fix from 64 to 32 (#1165)
- Mosaic4 bug fix (#1021)
- Logging directory runs/exp bug fix (#978)
- Various additional
Added Functionality
- PyTorch Hub functionality with YOLOv5 .autoshape() method added (#1210)
- Autolabelling addition and standardization across detect.py and test.py (#1182)
- Precision-Recall Curve automatic plotting when testing (#1107)
- Self-host VOC dataset for more reliable access and faster downloading (#1077)
- Adding option to output autolabel confidence with --save-conf in test.py and detect.py (#994)
- Google App Engine deployment option (#964)
- Infinite Dataloader for faster training (#876)
- Various additional
v3.0
This releases includes nn.Hardswish() activation implementation on Conv() modules, which increases mAP for all models at the expense of about 10% in inference speed. Training speeds are not significantly affected, though CUDA memory requirements increase about 10%. Training from scratch as well as finetuning both benefit from this change. The smallest models benefit the most from the Hardswish() activations, with increases of +0.9/+0.8/+0.7/+0.2mAP@0.5:0.95 for YOLOv5s/m/l/x.
All mAP values in our README are now reported at --img-size 640 (v2.0 reported at 672, and v1.0 reported at 736), so we've succeeded in increasing mAP while reducing the required --img-size :)
We've also listed YOLOv5x Test Time Augmentation (TTA) mAP and speeds for v3.0 in our README table for the first time (and for v2.0 below). Best results are YOLOv5x with TTA at 50.8 mAP@0.5:0.95. We've also updated efficientdet results in our comparison plot to reflect recent improvements in the google/automl repo.
Breaking Changes
- This release does not contain breaking changes.
- This release is only backwards compatible with v2.0 models trained with torch>=1.6.
Bug Fixes
- Hyperparameter evolution fixed, tutorial added (#607)
Added Functionality
- PyTorch 1.6 compatible.
torch>=1.6required (43a616a) - PyTorch 1.6 native Automatic Mixed Precision (AMP) replaces NVIDIA Apex AMP (#573)
nn.Hardswish()activations replacenn.LeakyReLU(0.1)in base convolution modulemodels.Conv()- Dataset Autodownload feature added (#685)
- Model Autodownload improved (#711)
- Layer freezing code added (#679)
- TensorRT export tutorial added (#623)

- August 13, 2020: v3.0 release: nn.Hardswish() activations, data autodownload, native AMP.
- July 23, 2020: v2.0 release: improved model definition, training and mAP.
- June 22, 2020: PANet updates: new heads, reduced parameters, improved speed and mAP 364fcfd.
- June 19, 2020: FP16 as new default for smaller checkpoints and faster inference d4c6674.
- June 9, 2020: CSP updates: improved speed, size, and accuracy (credit to @WongKinYiu for CSP).
- May 27, 2020: Public release. YOLOv5 models are SOTA among all known YOLO implementations.
- April 1, 2020: Start development of future compound-scaled YOLOv3/YOLOv4-based PyTorch models.
Pretrained Checkpoints
v3.0 with nn.Hardswish()
| Model | APval | APtest | AP50 | SpeedGPU | FPSGPU | params | FLOPS | |
|---|---|---|---|---|---|---|---|---|
| YOLOv5s | 37.0 | 37.0 | 56.2 | 2.4ms | 476 | 7.5M | 13.2B | |
| YOLOv5m | 44.3 | 44.3 | 63.2 | 3.4ms | 333 | 21.8M | 39.4B | |
| YOLOv5l | 47.7 | 47.7 | 66.5 | 4.4ms | 256 | 47.8M | 88.1B | |
| YOLOv5x | 49.2 | 49.2 | 67.7 | 6.9ms | 164 | 89.0M | 166.4B | |
| YOLOv5x + TTA | 50.8 | 50.8 | 68.9 | 25.5ms | 39 | 89.0M | 354.3B | |
| YOLOv3-SPP | 45.6 | 45.5 | 65.2 | 4.5ms | 222 | 63.0M | 118.0B |
** APtest denotes COCO test-dev2017 server results, all other AP results in the table denote val2017 accuracy.
** All AP numbers are for single-model single-scale without ensemble or test-time augmentation except for TTA. Reproduce by python test.py --data coco.yaml --img 640 --conf 0.001. Test Time Augmentation (TTA) runs at 3 image sizes. Reproduce TTA results by python test.py --data coco.yaml --img 832 --augment
** SpeedGPU measures end-to-end time per image averaged over 5000 COCO val2017 images using a GCP n1-standard-16 instance with one V100 GPU, and includes image preprocessing, PyTorch FP16 image inference at --batch-size 32 --img-size 640, postprocessing and NMS. Average NMS time included in this chart is 1-2ms/img. Reproduce by python test.py --data coco.yaml --img 640 --conf 0.1
** All checkpoints are trained to 300 epochs with default settings and hyperparameters (no autoaugmentation).
v2.0 with nn.LeakyReLU(0.1)
| Model | APval | APtest | AP50 | SpeedGPU | FPSGPU | params | FLOPS | |
|---|---|---|---|---|---|---|---|---|
| YOLOv5s | 36.1 | 36.1 | 55.3 | 2.2ms | 476 | 7.5M | 13.2B | |
| YOLOv5m | 43.5 | 43.5 | 62.5 | 3.2ms | 333 | 21.8M | 39.4B | |
| YOLOv5l | 47.0 | 47.1 | 65.6 | 4.1ms | 256 | 47.8M | 88.1B | |
| YOLOv5x | 49.0 | 49.0 | 67.4 | 6.4ms | 164 | 89.0M | 166.4B | |
| YOLOv5x + TTA | 50.4 | 50.4 | 68.5 | 23.4ms | 43 | 89.0M | 354.3B | |
| YOLOv3-SPP | 45.6 | 45.5 | 65.2 | 4.5ms | 222 | 63.0M | 118.0B |
** APtest denotes COCO test-dev2017 server results, all other AP results in the table denote val2017 accuracy.
** All AP numbers are for single-model single-scale without ensemble or test-time augmentation. Reproduce by python test.py --data coco.yaml --img 672 --conf 0.001
** SpeedGPU measures end-to-end time per image averaged over 5000 COCO val2017 images using a GCP n1-standard-16 instance with one V100 GPU, and includes image preprocessing, PyTorch FP16 image inference at --batch-size 32 --img-size 640, postprocessing and NMS. Average NMS time included in this chart is 1-2ms/img. Reproduce by python test.py --data coco.yaml --img 640 --conf 0.1
** All checkpoints are trained to 300 epochs with default settings and hyperparameters (no autoaugmentation).
v2.0
Breaking Changes
IMPORTANT: v2.0 release contains breaking changes. Models trained with earlier versions will not operate correctly with v2.0. The last commit before v2.0 that operates correctly with all earlier pretrained models is:
https://github.com/ultralytics/yolov5/tree/5e970d45c44fff11d1eb29bfc21bed9553abf986
To clone last commit prior to v2.0:
git clone https://github.com/ultralytics/yolov5 # clone repo
cd yolov5
git reset --hard 5e970d4 # last commit before v2.0Bug Fixes
- Various
Added Functionality
- Various

- July 23, 2020: v2.0 release: improved model definition, training and mAP.
- June 22, 2020: PANet updates: new heads, reduced parameters, improved speed and mAP 364fcfd.
- June 19, 2020: FP16 as new default for smaller checkpoints and faster inference d4c6674.
- June 9, 2020: CSP updates: improved speed, size, and accuracy (credit to @WongKinYiu for CSP).
- May 27, 2020: Public release. YOLOv5 models are SOTA among all known YOLO implementations.
- April 1, 2020: Start development of future compound-scaled YOLOv3/YOLOv4-based PyTorch models.
Pretrained Checkpoints
| Model | APval | APtest | AP50 | SpeedGPU | FPSGPU | params | FLOPS | |
|---|---|---|---|---|---|---|---|---|
| YOLOv5s | 36.1 | 36.1 | 55.3 | 2.1ms | 476 | 7.5M | 13.2B | |
| YOLOv5m | 43.5 | 43.5 | 62.5 | 3.0ms | 333 | 21.8M | 39.4B | |
| YOLOv5l | 47.0 | 47.1 | 65.6 | 3.9ms | 256 | 47.8M | 88.1B | |
| YOLOv5x | 49.0 | 49.0 | 67.4 | 6.1ms | 164 | 89.0M | 166.4B | |
| YOLOv3-SPP | 45.6 | 45.5 | 65.2 | 4.5ms | 222 | 63.0M | 118.0B |
** APtest denotes COCO test-dev2017 server results, all other AP results in the table denote val2017 accuracy.
** All AP numbers are for single-model single-scale without ensemble or test-time augmentation. Reproduce by python test.py --data coco.yaml --img 672 --conf 0.001
** SpeedGPU measures end-to-end time per image averaged over 5000 COCO val2017 images using a GCP n1-standard-16 instance with one V100 GPU, and includes image preprocessing, PyTorch FP16 image inference at --batch-size 32 --img-size 640, postprocessing and NMS. Average NMS time included in this chart is 1-2ms/img. Reproduce by python test.py --data coco.yaml --img 640 --conf 0.1
** All checkpoints are trained to 300 epochs with default settings and hyperparameters (no autoaugmentation).
v1.0
YOLOv5 1.0 Release Notes
- June 22, 2020: PANet updates: increased layers, reduced parameters, faster inference and improved mAP 364fcfd.
- June 19, 2020: FP16 as new default for smaller checkpoints and faster inference d4c6674.
- June 9, 2020: CSP updates: improved speed, size, and accuracy. Credit to @WongKinYiu for excellent CSP work.
- May 27, 2020: Public release of repo. YOLOv5 models are SOTA among all known YOLO implementations.
- April 1, 2020: Start development of future YOLOv3/YOLOv4-based PyTorch models in a range of compound-scaled sizes.
Pretrained Checkpoints
| Model | APval | APtest | AP50 | SpeedGPU | FPSGPU | params | FLOPS | |
|---|---|---|---|---|---|---|---|---|
| YOLOv5s | 36.6 | 36.6 | 55.8 | 2.1ms | 476 | 7.5M | 13.2B | |
| YOLOv5m | 43.4 | 43.4 | 62.4 | 3.0ms | 333 | 21.8M | 39.4B | |
| YOLOv5l | 46.6 | 46.7 | 65.4 | 3.9ms | 256 | 47.8M | 88.1B | |
| YOLOv5x | 48.4 | 48.4 | 66.9 | 6.1ms | 164 | 89.0M | 166.4B | |
| YOLOv3-SPP | 45.6 | 45.5 | 65.2 | 4.5ms | 222 | 63.0M | 118.0B |
** APtest denotes COCO test-dev2017 server results, all other AP results in the table denote val2017 accuracy.
** All AP numbers are for single-model single-scale without ensemble or test-time augmentation. Reproduce by python test.py --img 736 --conf 0.001
** SpeedGPU measures end-to-end time per image averaged over 5000 COCO val2017 images using a GCP n1-standard-16 instance with one V100 GPU, and includes image preprocessing, PyTorch FP16 image inference at --batch-size 32 --img-size 640, postprocessing and NMS. Average NMS time included in this chart is 1-2ms/img. Reproduce by python test.py --img 640 --conf 0.1
** All checkpoints are trained to 300 epochs with default settings and hyperparameters (no autoaugmentation).