A.02 Matrices
Matrices are mathematical objects associated with functions. This means that a matrix can represent a transformation we can use to manipulate the coordinates of points and vectors, allowing us to change the position, orientation, or size of 3D objects within a rendering scene.
Basically, a matrix is just a rectangular table of real numbers arranged in rows and columns.
The dimensions of a matrix are determined by the number of its rows and columns. For instance, an
In computer graphics, it is common to work with square matrices
We can also use them to specify the rows or columns of a matrix. For example, we can write the following
where
There are several interesting operations that can be performed with matrices, including addition, subtraction, and two different types of multiplication.
The addition of two matrices
The difference of two matrices is defined in a similar way.
We can multiply a matrix
Since addition and scalar multiplication are performed element-wise on matrices, they inherit the following properties from real numbers:
| Commutative | |
| Associative | |
| Distributive (scalar) | |
| Distributive (matrix) |
In order to multiply two matrices
where
As an example, the following illustration shows that if we multiply a
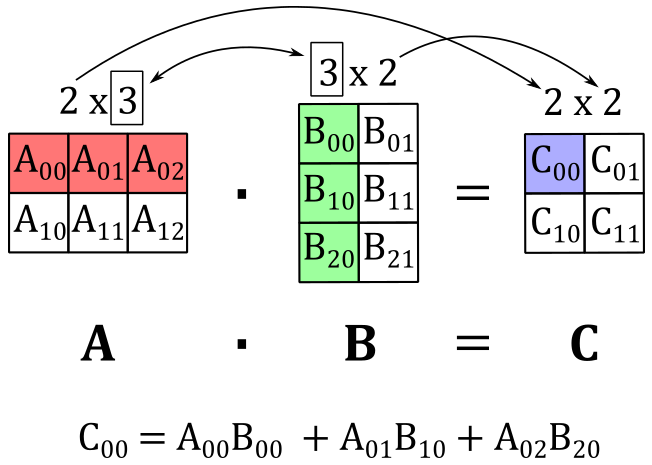
Observe that matrix multiplication is always defined for square matrices of the same dimension, and the resulting matrix will have the same dimension as the operands, with both the number of rows and columns remaining unchanged.
A column vector is a
The result is a column vector with three elements (just like
So, the matrix-vector multiplication can be seen as a sum of the columns of the matrix, scaled by the elements of the column vector. This is an example of linear combination: a sum of vectors multiplied (scaled) by scalar coefficients. In this case, the vectors are the column vectors of the matrix, while the scalar coefficients are the elements of the column vector. We can also write this linear combination as the product of a row vector and a column vector.
As you may have observed, the multiplication of a row vector and a column vector is closely related to the concept of dot product. Indeed, we have that
That is, we can consider the operands of a dot product as row and column vectors, rather than just ordinary vectors.
What we have discussed so far in this section applies in general. That is, if we have a
We can also multiply a
The result is a row vector with three elements where each entry is the dot product of
Therefore, the product of a row vector and a matrix is a linear combination of the rows of the matrix, scaled by the elements of the row vector.
Since matrix multiplication is performed element-wise, it inherits the following properties from real numbers:
| Associative | |
| Distributive |
The commutative property does not apply for two reasons. Firstly, as mentioned earlier, matrix multiplication is only defined when the number of columns in the left matrix is equal to the number of rows in the right matrix. Secondly, even with square matrices of the same dimension (where matrix multiplication is always defined), swapping the order of the operands can lead to a different resultant matrix. Consider equation
To conclude this section, as mentioned in Appendix 01 on Vectors, we stated that the cross product can be computed by multiplying a matrix and a column vector. We can now verify this statement using the following equation.
Also, it’s interesting to note that we can compute the orthogonal projection of a vector
Indeed, observe that the i-th component of
The transpose of a matrix
As you can see, interchanging rows and columns in a matrix is equivalent to flipping the matrix over its diagonal. As a result, if we have a matrix
Below are the properties of the matrix transpose.
$(\mathbf{A}^T)^T=\mathbf{A}$ $(k\mathbf{A}^T)=k\mathbf{A}^T$ $(\mathbf{A}+\mathbf{B})^T=\mathbf{A}^T+\mathbf{B}^T$ $(\mathbf{AB})^T=\mathbf{B}^T\mathbf{A}^T$
The first three properties are straightforward to prove. For the last property, we can demonstrate it by computing the ji-th entry of both
$(\mathbf{AB})^T$ and$\mathbf{B}^T\mathbf{A}^T$ , and showing that they are equal. Specifically, we have:
$(\mathbf{AB})_ {ij}^T=(\mathbf{AB})_ {ji}=\mathbf{A}_ {j\ast}\cdot\mathbf{B}_ {\ast i}$
$(\mathbf{B}^T\mathbf{A}^T)_ {ij}=\mathbf{B}_ {i\ast}^T\cdot\mathbf{A}_ {\ast j}^T=\mathbf{B}_ {\ast i}\cdot\mathbf{A}_ {j\ast}$ The two expressions are the same since the dot product is commutative. Also, observe how we flipped the subscripts to refer to the corresponding entry in the transpose.
The identity matrix is a square matrix in which all the elements are zero, except for the entries on the main diagonal, which are all 1. The main diagonal consists of elements
The identity matrix is named as such because it serves as the multiplicative identity. That is, for an
Observe that the multiplication with the identity matrix is commutative by definition, meaning that the order of multiplication does not matter. This is an exception to the general operation of matrix multiplication, where the order of multiplication typically matters, and matrix multiplication is not commutative.
The determinant of a matrix is closely related to the concept of hypervolume, which represents the measure of length in 1D, area in 2D, and volume in 3D. It is important to note that the determinant is only defined for square matrices. Now, you may be wondering what it means to have a signed length, area, or volume. As mentioned earlier in this tutorial (and as we will formally demonstrate in a subsequent appendix), matrices are associated with transformations, and the sign of the determinant indicates whether a transformation preserves or reverses the orientation of the standard basis vectors. In simpler terms, when multiplying (transforming) the standard basis vectors
Before delving into the calculation of the determinant of a matrix, we first need to introduce the concept of matrix minors.
By matrix minor of an
Now, let's see how to calculate the determinant
Observe that the dot in the equation above represents scalar multiplication, not a dot product. The only variable in the equation is
The equation
Now that we know how to calculate the determinants of
As can be observed, the result obtained is similar to the outcome of the scalar triple product discussed in Appendix 01. This means that the determinant of a
On the other hand, it’s much easier to prove that the determinant of a
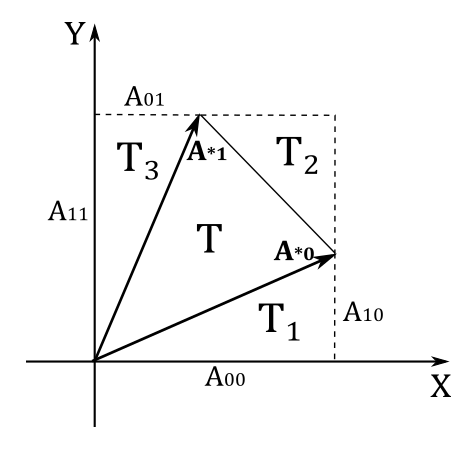
In the illustration above, we have that the area
where
Substituting and simplifying, we get
However, we want to calculate the area of the parallelogram
By now, you might have figured out how to compute the determinant of a
It can be proven that if we add a scaled column (or row) of a matrix to another column (or row) of the same matrix, the determinant does not change. However, we won’t provide a formal proof here as a practical example is more than enough. Indeed, below you can verify that if we scale the second column of a simple
The cofactor
Computing the cofactor of every element of the matrix
The adjoint
Please note the swap between subscripts in the matrix minor to select the corresponding entry in the transpose.
The adjoint of a matrix, and in particular the equation
In matrix algebra, the concept of inverse only applies to square matrices and is similar to the concept of inverse (or reciprocal) for real numbers. Specifically, for an
Just like with real numbers, if we multiply a matrix by its inverse we get the the multiplicative identity (in this case, the identity matrix). Observe that the inverse of
Given a
$2\times 2$ matrix$\mathbf{A}$ and its inverse$\mathbf{A}^{-1}$
$\mathbf{A}=\left\lbrack\matrix{a&b\cr c&d}\right\rbrack\quad\quad\quad\quad\mathbf{A}^{-1}=\left\lbrack\matrix{v_{00}&v_{01}\cr v_{10}&v_{11}}\right\rbrack$
Since
$\mathbf{A}\mathbf{A}^{-1}=\mathbf{I}$ we have that
$\left\lbrack\matrix{a&b}\right\rbrack\ \mathbf{A}^{-1}=\left\lbrack\matrix{1&0}\right\rbrack$
$\left\lbrack\matrix{c&d}\right\rbrack\ \mathbf{A}^{-1}=\left\lbrack\matrix{0&1}\right\rbrack$
From these two expressions, we can derive the following system of four equations with four unknowns
$v_{ij}$ .
$$ \begin{cases} a\ v_{00}+b\ v_{01} &=1 \cr a\ v_{10}+b\ v_{11} &=0 \cr c\ v_{00}+d\ v_{01} &=0 \cr c\ v_{10}+d\ v_{11} &=1 \end{cases}$$
If we solve this system for
$v_{00}$ we get
$v_{00}=\displaystyle {d \over ad-bc}$
That’s exactly the ratio between the cofactor of the 00-th element of
$\mathbf{A}$ and the its determinant. The same applies to the other unknowns and to matrices of higher dimensions as well, since it always ends up with a system of$n$ equations with$n$ unknowns.
As you may have noticed, in
Below are the properties of the matrix inverse.
$(\mathbf{A}^{-1})^T=(\mathbf{A}^T)^{-1}$ $(\mathbf{AB})^{-1}=\mathbf{B}^{-1}\mathbf{A}^{-1}$
For the first property, we need to show that
$(\mathbf{A}^{-1})^T$ is the inverse of$\mathbf{A}^T$ . And indeed, from$(\mathbf{AB})^T=\mathbf{B}^T\mathbf{A}^T$ we have that
$(\mathbf{A}^{-1})^T\mathbf{A}^T=(\mathbf{A}\mathbf{A}^{-1})^T=\mathbf{I}^T=\mathbf{I}$ For the second property, assuming that
$\mathbf{A}$ and$\mathbf{B}$ are square and invertible matrices, we need to show that$(\mathbf{AB})(\mathbf{B}^{-1}\mathbf{A}^{-1})=\mathbf{I}$ and$(\mathbf{B}^{-1}\mathbf{A}^{-1})(\mathbf{AB})=\mathbf{I}$ . Indeed, using the associative property of matrix multiplication, we have that
$(\mathbf{AB})(\mathbf{B}^{-1}\mathbf{A}^{-1})=\mathbf{A}(\mathbf{B}\mathbf{B}^{-1})\mathbf{A}^{-1}=\mathbf{AI}\mathbf{A}^{-1}=\mathbf{A}\mathbf{A}^{-1}=\mathbf{I}$
$(\mathbf{B}^{-1}\mathbf{A}^{-1})(\mathbf{AB})=\mathbf{B}^{-1}(\mathbf{A}\mathbf{A}^{-1})\mathbf{B}=\mathbf{B}^{-1}\mathbf{IB}=\mathbf{B}^{-1}\mathbf{B}=\mathbf{I}$
The elements of matrices used in C++ applications are stored contiguously row by row in CPU memory (RAM), as illustrated below.
We refer to this arrangement of elements as row-major order.
Of course, the elements of matrices defined and used in shader code are stored contiguously in device memory as well. However, by default, they are considered as stored column by column by the device. We refer to this arrangement as column-major order. Then, to represent the same matrix in shader code, its elements should have the following layout when stored in device memory.
Now, a problem arises whenever we have to pass matrix data from our C++ applications to shader programs. As stated in a previous tutorial, the transfer of data from host to device memory is just a bit stream. Then, if we simply copy the matrix data from our application to host-visible device memory, the transpose of the matrix will be passed because the contiguous elements of the rows in host memory will be considered columns in device memory by the GPU during the execution of the shader code.
Fortunately, we showed that
In practice, in most cases when using the GLM library, there is no need to worry about the memory layout of matrix elements in our applications. Indeed, GLM defines matrices as arrays of column vectors and performs matrix operations accordingly. This means that, unless you need to manually build a matrix (element by element) without the assistance of any helper function provided by the library, you can simply rely on the memory management provided by the library for matrices and forget about these concerns. In the next section and subsequent appendices, we will explore more details about how GLM handles matrices and their operations.
Matrices play a crucial role in computer graphics, making them a fundamental tool to use in Vulkan as well. They are widely used in both C++ (within the application code) and in GLSL (within shader code).
In HLSL, we can use the built-in types mat2x2, mat3x3, and mat4x4 to represent
The components of a matrix can be accessed using array subscripting syntax. Applying a single subscript to a matrix treats the matrix as an array of column vectors, and selects a single column, where the leftmost column is column 0. A second subscript would then operate on the resulting vector, as defined in the previous appendix for vectors.
// mat2x2 fMatrix = {0.0, 0.1,2.1, 2.2};
mat2x2 fMatrix =
{
{0.0f, 0.1f}, // column 0
{2.1f, 2.2f} // column 1
};
mat4x4 M =
{ // Initialize M
vec4(1.0f, 2.0f, 3.0f, 4.0f), // first column
vec4(5.0f, 6.0f, 7.0f, 8.0f), // second column
// ... // third column
// ... // fourth column
};
//
// (0.0f, 0.0f, 0.0f) column 0
// (1.0f, 1.0f, 1.0f) column 1
// (2.0f, 2.0f, 2.0f) column 2
mat3 T = mat3(0.0f, 0.0f, 0.0f, 1.0f, 1.0f, 1.0f, 2.0f, 2.0f, 2.0f);
mat3(M); // takes the upper-left 3x3 sub-matrix of the 4x4 matrix M
// Identity matrix; initialize the diagonal of a matrix with all other elements set to zero
mat4(1.0);
vec4 v = { 4.0f, 3.0f, 2.0f, 1.0f };
float f0 = M[0][1]; // f0 = 01-th element of M; second element of the first column of M
M[0] = v; // First column of M = vIn C++, the GLM library provides various matrix types to represent matrices of different dimensions, such as 2x3, 3x3, and so on.
typedef mat<2, 2, float, defaultp> mat2x2;
typedef mat<2, 3, float, defaultp> mat2x3;
typedef mat<2, 4, float, defaultp> mat2x4;
typedef mat<3, 2, float, defaultp> mat3x2;
typedef mat<3, 3, float, defaultp> mat3x3;
typedef mat<3, 4, float, defaultp> mat3x4;
typedef mat<4, 2, float, defaultp> mat4x2;
typedef mat<4, 3, float, defaultp> mat4x3;
typedef mat<4, 4, float, defaultp> mat4x4;
typedef mat<2, 2, float, defaultp> mat2;
typedef mat<3, 3, float, defaultp> mat3;
typedef mat<4, 4, float, defaultp> mat4;
// Similar structures are provided for matrices of different dimensions
template<typename T, qualifier Q>
struct mat<4, 4, T, Q>
{
typedef vec<4, T, Q> col_type;
typedef vec<4, T, Q> row_type;
typedef mat<4, 4, T, Q> type;
typedef mat<4, 4, T, Q> transpose_type;
typedef T value_type;
private:
col_type value[4];
// ...
}As you can see, in GLM a matrix is stored as an array of column vectors.
Refer to the complete source code to see how conversions and constructors are implemented to mimic the GLSL behaviour. This approach will allow you to understand the practical implementation details without necessarily consulting the GLSL specification directly. For example, in C++ we can build a diagonal matrix from a scalar value, just like we can do in GLSL, as demonstrated in the code listing above.
// -- Constructors --
GLM_FUNC_DECL explicit GLM_CONSTEXPR mat(T const& x);
template<typename T, qualifier Q>
GLM_FUNC_QUALIFIER GLM_CONSTEXPR mat<4, 4, T, Q>::mat(T const& s)
: value{col_type(s, 0, 0, 0), col_type(0, s, 0, 0), col_type(0, 0, s, 0), col_type(0, 0, 0, s)}
{ }In a similar way, the following conversion means that we can also build a mat4 from a mat3, both in C++ and GLSL.
// -- Matrix conversions --
GLM_FUNC_DECL GLM_EXPLICIT GLM_CONSTEXPR mat(mat<3, 3, T, Q> const& x);
// Put the mat3x3 in the upper-left, set the lower right component to 1, and the rest to 0
template<typename T, qualifier Q>
GLM_FUNC_QUALIFIER GLM_CONSTEXPR mat<4, 4, T, Q>::mat(mat<3, 3, T, Q> const& m)
: value{col_type(m[0], 0), col_type(m[1], 0), col_type(m[2], 0), col_type(0, 0, 0, 1)}
{ }C++
// Odd way to build a 4x4 identity matrix.
glm::mat3 m33 = glm::mat3(1.0f); // 3x3 identity matrix
glm::mat4 m44(m33); // 4x4 identity matrixGLSL
// 4x4 Identity matrix; initialize the diagonal of a matrix with all other elements set to zero
mat4 m44 = mat4(mat3(1.0));Obviously, all the basic matrix operations discussed in this tutorial (sum, difference and various types of multiplication) are both defined in GLSL and implemented by GLM, along with other helper functions that can be performed on matrices such as inversion, transposition and determinant calculation. For example, the sum of two mat3 in GLM is defined exactly as per the definition (sum of the corresponding elements). Observe that, in this case, we can achieve the same result by simply summing the corresponding column vectors.
// -- Binary arithmetic operators --
template<typename T, qualifier Q>
GLM_FUNC_DECL mat<3, 3, T, Q> operator+(mat<3, 3, T, Q> const& m1, mat<3, 3, T, Q> const& m2);
template<typename T, qualifier Q>
GLM_FUNC_QUALIFIER mat<3, 3, T, Q> operator+(mat<3, 3, T, Q> const& m1, mat<3, 3, T, Q> const& m2)
{
return mat<3, 3, T, Q>(
m1[0] + m2[0],
m1[1] + m2[1],
m1[2] + m2[2]);
}However, the fact that GLM stores matrices using a column-major order has consequences for matrix multiplication. Indeed, we need to flips the indices with respect to the subscripts in equation
Observe that mat3x2 in GLM denotes a matrix with 3 columns of two elements, that is a
$2\times 3$ matrix.
template<typename T, qualifier Q>
GLM_FUNC_QUALIFIER mat<3, 2, T, Q> operator*(mat<2, 2, T, Q> const& m1, mat<3, 2, T, Q> const& m2)
{
return mat<3, 2, T, Q>(
m1[0][0] * m2[0][0] + m1[1][0] * m2[0][1],
m1[0][1] * m2[0][0] + m1[1][1] * m2[0][1],
m1[0][0] * m2[1][0] + m1[1][0] * m2[1][1],
m1[0][1] * m2[1][0] + m1[1][1] * m2[1][1],
m1[0][0] * m2[2][0] + m1[1][0] * m2[2][1],
m1[0][1] * m2[2][0] + m1[1][1] * m2[2][1]);
}You can also verify that the transpose of a matrix
transpose(M) = T[i][j] = M[j][i]; return T // swap subscripts
With respect to matrix transpose and inverse, GLM uses direct solutions derived from the recursive formulas presented in this tutorial. The process of deriving iterative or direct solutions from recursive formulas can sometimes lead to complex or convoluted code, especially for
In the next appendix, we will discuss other functions that operate on matrix to perform transformations.
Source code: LearnVulkan
[1] Practical Linear Algebra: A Geometry Toolbox (Farin, Hansford)
If you found the content of this tutorial somewhat useful or interesting, please consider supporting this project by clicking on the Sponsor button. Whether a small tip, a one time donation, or a recurring payment, it's all welcome! Thank you!