Branch 2.3 #21614
Closed
Branch 2.3 #21614
Conversation
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
… API or functions ## What changes were proposed in this pull request? Update the description and tests of three external API or functions `createFunction `, `length` and `repartitionByRange ` ## How was this patch tested? N/A Author: gatorsmile <gatorsmile@gmail.com> Closes #20495 from gatorsmile/updateFunc. (cherry picked from commit c36fecc) Signed-off-by: gatorsmile <gatorsmile@gmail.com>
…rReplaceTempView ## What changes were proposed in this pull request? Replace `registerTempTable` by `createOrReplaceTempView`. ## How was this patch tested? N/A Author: gatorsmile <gatorsmile@gmail.com> Closes #20523 from gatorsmile/updateExamples. (cherry picked from commit 9775df6) Signed-off-by: hyukjinkwon <gurwls223@gmail.com>
## What changes were proposed in this pull request? When `DebugFilesystem` closes opened stream, if any exception occurs, we still need to remove the open stream record from `DebugFilesystem`. Otherwise, it goes to report leaked filesystem connection. ## How was this patch tested? Existing tests. Author: Liang-Chi Hsieh <viirya@gmail.com> Closes #20524 from viirya/SPARK-23345. (cherry picked from commit 9841ae0) Signed-off-by: gatorsmile <gatorsmile@gmail.com>
…by default ## What changes were proposed in this pull request? This is to revert the changes made in #19499 , because this causes a regression. We should not ignore the table-specific compression conf when the Hive serde tables are converted to the data source tables. ## How was this patch tested? The existing tests. Author: gatorsmile <gatorsmile@gmail.com> Closes #20536 from gatorsmile/revert22279. (cherry picked from commit 3473fda) Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…ta types ## What changes were proposed in this pull request? For inserting/appending data to an existing table, Spark should adjust the data types of the input query according to the table schema, or fail fast if it's uncastable. There are several ways to insert/append data: SQL API, `DataFrameWriter.insertInto`, `DataFrameWriter.saveAsTable`. The first 2 ways create `InsertIntoTable` plan, and the last way creates `CreateTable` plan. However, we only adjust input query data types for `InsertIntoTable`, and users may hit weird errors when appending data using `saveAsTable`. See the JIRA for the error case. This PR fixes this bug by adjusting data types for `CreateTable` too. ## How was this patch tested? new test. Author: Wenchen Fan <wenchen@databricks.com> Closes #20527 from cloud-fan/saveAsTable. (cherry picked from commit 7f5f5fb) Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request? This is a followup of #20435. While reorganizing the packages for streaming data source v2, the top level stream read/write support interfaces should not be in the reader/writer package, but should be in the `sources.v2` package, to follow the `ReadSupport`, `WriteSupport`, etc. ## How was this patch tested? N/A Author: Wenchen Fan <wenchen@databricks.com> Closes #20509 from cloud-fan/followup. (cherry picked from commit a75f927) Signed-off-by: Wenchen Fan <wenchen@databricks.com>
… Drivers ## What changes were proposed in this pull request? Since some JDBC Drivers have class initialization code to call `DriverManager`, we need to initialize `DriverManager` first in order to avoid potential executor-side **deadlock** situations like the following (or [STORM-2527](https://issues.apache.org/jira/browse/STORM-2527)). ``` Thread 9587: (state = BLOCKED) - sun.reflect.NativeConstructorAccessorImpl.newInstance0(java.lang.reflect.Constructor, java.lang.Object[]) bci=0 (Compiled frame; information may be imprecise) - sun.reflect.NativeConstructorAccessorImpl.newInstance(java.lang.Object[]) bci=85, line=62 (Compiled frame) - sun.reflect.DelegatingConstructorAccessorImpl.newInstance(java.lang.Object[]) bci=5, line=45 (Compiled frame) - java.lang.reflect.Constructor.newInstance(java.lang.Object[]) bci=79, line=423 (Compiled frame) - java.lang.Class.newInstance() bci=138, line=442 (Compiled frame) - java.util.ServiceLoader$LazyIterator.nextService() bci=119, line=380 (Interpreted frame) - java.util.ServiceLoader$LazyIterator.next() bci=11, line=404 (Interpreted frame) - java.util.ServiceLoader$1.next() bci=37, line=480 (Interpreted frame) - java.sql.DriverManager$2.run() bci=21, line=603 (Interpreted frame) - java.sql.DriverManager$2.run() bci=1, line=583 (Interpreted frame) - java.security.AccessController.doPrivileged(java.security.PrivilegedAction) bci=0 (Compiled frame) - java.sql.DriverManager.loadInitialDrivers() bci=27, line=583 (Interpreted frame) - java.sql.DriverManager.<clinit>() bci=32, line=101 (Interpreted frame) - org.apache.phoenix.mapreduce.util.ConnectionUtil.getConnection(java.lang.String, java.lang.Integer, java.lang.String, java.util.Properties) bci=12, line=98 (Interpreted frame) - org.apache.phoenix.mapreduce.util.ConnectionUtil.getInputConnection(org.apache.hadoop.conf.Configuration, java.util.Properties) bci=22, line=57 (Interpreted frame) - org.apache.phoenix.mapreduce.PhoenixInputFormat.getQueryPlan(org.apache.hadoop.mapreduce.JobContext, org.apache.hadoop.conf.Configuration) bci=61, line=116 (Interpreted frame) - org.apache.phoenix.mapreduce.PhoenixInputFormat.createRecordReader(org.apache.hadoop.mapreduce.InputSplit, org.apache.hadoop.mapreduce.TaskAttemptContext) bci=10, line=71 (Interpreted frame) - org.apache.spark.rdd.NewHadoopRDD$$anon$1.<init>(org.apache.spark.rdd.NewHadoopRDD, org.apache.spark.Partition, org.apache.spark.TaskContext) bci=233, line=156 (Interpreted frame) Thread 9170: (state = BLOCKED) - org.apache.phoenix.jdbc.PhoenixDriver.<clinit>() bci=35, line=125 (Interpreted frame) - sun.reflect.NativeConstructorAccessorImpl.newInstance0(java.lang.reflect.Constructor, java.lang.Object[]) bci=0 (Compiled frame) - sun.reflect.NativeConstructorAccessorImpl.newInstance(java.lang.Object[]) bci=85, line=62 (Compiled frame) - sun.reflect.DelegatingConstructorAccessorImpl.newInstance(java.lang.Object[]) bci=5, line=45 (Compiled frame) - java.lang.reflect.Constructor.newInstance(java.lang.Object[]) bci=79, line=423 (Compiled frame) - java.lang.Class.newInstance() bci=138, line=442 (Compiled frame) - org.apache.spark.sql.execution.datasources.jdbc.DriverRegistry$.register(java.lang.String) bci=89, line=46 (Interpreted frame) - org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$createConnectionFactory$2.apply() bci=7, line=53 (Interpreted frame) - org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$createConnectionFactory$2.apply() bci=1, line=52 (Interpreted frame) - org.apache.spark.sql.execution.datasources.jdbc.JDBCRDD$$anon$1.<init>(org.apache.spark.sql.execution.datasources.jdbc.JDBCRDD, org.apache.spark.Partition, org.apache.spark.TaskContext) bci=81, line=347 (Interpreted frame) - org.apache.spark.sql.execution.datasources.jdbc.JDBCRDD.compute(org.apache.spark.Partition, org.apache.spark.TaskContext) bci=7, line=339 (Interpreted frame) ``` ## How was this patch tested? N/A Author: Dongjoon Hyun <dongjoon@apache.org> Closes #20359 from dongjoon-hyun/SPARK-23186. (cherry picked from commit 8cbcc33) Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…ce when 'to_replace' is not a dictionary
## What changes were proposed in this pull request?
This PR proposes to disallow default value None when 'to_replace' is not a dictionary.
It seems weird we set the default value of `value` to `None` and we ended up allowing the case as below:
```python
>>> df.show()
```
```
+----+------+-----+
| age|height| name|
+----+------+-----+
| 10| 80|Alice|
...
```
```python
>>> df.na.replace('Alice').show()
```
```
+----+------+----+
| age|height|name|
+----+------+----+
| 10| 80|null|
...
```
**After**
This PR targets to disallow the case above:
```python
>>> df.na.replace('Alice').show()
```
```
...
TypeError: value is required when to_replace is not a dictionary.
```
while we still allow when `to_replace` is a dictionary:
```python
>>> df.na.replace({'Alice': None}).show()
```
```
+----+------+----+
| age|height|name|
+----+------+----+
| 10| 80|null|
...
```
## How was this patch tested?
Manually tested, tests were added in `python/pyspark/sql/tests.py` and doctests were fixed.
Author: hyukjinkwon <gurwls223@gmail.com>
Closes #20499 from HyukjinKwon/SPARK-19454-followup.
(cherry picked from commit 4b4ee26)
Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…8, it will result in an error result ## What changes were proposed in this pull request? In the `checkIndexAndDataFile`,the `blocks` is the ` Int` type, when it is greater than 2^28, `blocks*8` will overflow, and this will result in an error result. In fact, `blocks` is actually the number of partitions. ## How was this patch tested? Manual test Author: liuxian <liu.xian3@zte.com.cn> Closes #20544 from 10110346/overflow. (cherry picked from commit f77270b) Signed-off-by: Sean Owen <sowen@cloudera.com>
## What changes were proposed in this pull request? Typo fixes (with expanding a Hive property) ## How was this patch tested? local build. Awaiting Jenkins Author: Jacek Laskowski <jacek@japila.pl> Closes #20550 from jaceklaskowski/hiveutils-typos. (cherry picked from commit 557938e) Signed-off-by: Sean Owen <sowen@cloudera.com>
## What changes were proposed in this pull request? This is a follow up of #20441. The two lines actually can trigger the hive metastore bug: https://issues.apache.org/jira/browse/HIVE-16844 The two configs are not in the default `ObjectStore` properties, so any run hive commands after these two lines will set the `propsChanged` flag in the `ObjectStore.setConf` and then cause thread leaks. I don't think the two lines are very useful. They can be removed safely. ## How was this patch tested? (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Feng Liu <fengliu@databricks.com> Closes #20562 from liufengdb/fix-omm. (cherry picked from commit 6d7c383) Signed-off-by: gatorsmile <gatorsmile@gmail.com>
…tz, or dateutil. ## What changes were proposed in this pull request? Currently we use `tzlocal()` to get Python local timezone, but it sometimes causes unexpected behavior. I changed the way to get Python local timezone to use pytz if the timezone is specified in environment variable, or timezone file via dateutil . ## How was this patch tested? Added a test and existing tests. Author: Takuya UESHIN <ueshin@databricks.com> Closes #20559 from ueshin/issues/SPARK-23360/master. (cherry picked from commit 97a224a) Signed-off-by: hyukjinkwon <gurwls223@gmail.com>
…mestamps in Arrow codepath to deal with dst ## What changes were proposed in this pull request? When tz_localize a tz-naive timetamp, pandas will throw exception if the timestamp is during daylight saving time period, e.g., `2015-11-01 01:30:00`. This PR fixes this issue by setting `ambiguous=False` when calling tz_localize, which is the same default behavior of pytz. ## How was this patch tested? Add `test_timestamp_dst` Author: Li Jin <ice.xelloss@gmail.com> Closes #20537 from icexelloss/SPARK-23314. (cherry picked from commit a34fce1) Signed-off-by: hyukjinkwon <gurwls223@gmail.com>
…al to branch-2.3. ## What changes were proposed in this pull request? When backporting a pr with tests using `assertPandasEqual` from master to branch-2.3, the tests fail because `assertPandasEqual` doesn't exist in branch-2.3. We should backport `assertPandasEqual` to branch-2.3 to avoid the failures. ## How was this patch tested? Modified tests. Author: Takuya UESHIN <ueshin@databricks.com> Closes #20577 from ueshin/issues/SPARK-23387/branch-2.3.
…ap may fail ## What changes were proposed in this pull request? This is a long-standing bug in `UnsafeKVExternalSorter` and was reported in the dev list multiple times. When creating `UnsafeKVExternalSorter` with `BytesToBytesMap`, we need to create a `UnsafeInMemorySorter` to sort the data in `BytesToBytesMap`. The data format of the sorter and the map is same, so no data movement is required. However, both the sorter and the map need a point array for some bookkeeping work. There is an optimization in `UnsafeKVExternalSorter`: reuse the point array between the sorter and the map, to avoid an extra memory allocation. This sounds like a reasonable optimization, the length of the `BytesToBytesMap` point array is at least 4 times larger than the number of keys(to avoid hash collision, the hash table size should be at least 2 times larger than the number of keys, and each key occupies 2 slots). `UnsafeInMemorySorter` needs the pointer array size to be 4 times of the number of entries, so we are safe to reuse the point array. However, the number of keys of the map doesn't equal to the number of entries in the map, because `BytesToBytesMap` supports duplicated keys. This breaks the assumption of the above optimization and we may run out of space when inserting data into the sorter, and hit error ``` java.lang.IllegalStateException: There is no space for new record at org.apache.spark.util.collection.unsafe.sort.UnsafeInMemorySorter.insertRecord(UnsafeInMemorySorter.java:239) at org.apache.spark.sql.execution.UnsafeKVExternalSorter.<init>(UnsafeKVExternalSorter.java:149) ... ``` This PR fixes this bug by creating a new point array if the existing one is not big enough. ## How was this patch tested? a new test Author: Wenchen Fan <wenchen@databricks.com> Closes #20561 from cloud-fan/bug. (cherry picked from commit 4bbd744) Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…k 2.3/hadoop 2.7 ## What changes were proposed in this pull request? This test only fails with sbt on Hadoop 2.7, I can't reproduce it locally, but here is my speculation by looking at the code: 1. FileSystem.delete doesn't delete the directory entirely, somehow we can still open the file as a 0-length empty file.(just speculation) 2. ORC intentionally allow empty files, and the reader fails during reading without closing the file stream. This PR improves the test to make sure all files are deleted and can't be opened. ## How was this patch tested? N/A Author: Wenchen Fan <wenchen@databricks.com> Closes #20584 from cloud-fan/flaky-test. (cherry picked from commit 6efd5d1) Signed-off-by: Sameer Agarwal <sameerag@apache.org>
## What changes were proposed in this pull request? This is a regression in Spark 2.3. In Spark 2.2, we have a fragile UI support for SQL data writing commands. We only track the input query plan of `FileFormatWriter` and display its metrics. This is not ideal because we don't know who triggered the writing(can be table insertion, CTAS, etc.), but it's still useful to see the metrics of the input query. In Spark 2.3, we introduced a new mechanism: `DataWritigCommand`, to fix the UI issue entirely. Now these writing commands have real children, and we don't need to hack into the `FileFormatWriter` for the UI. This also helps with `explain`, now `explain` can show the physical plan of the input query, while in 2.2 the physical writing plan is simply `ExecutedCommandExec` and it has no child. However there is a regression in CTAS. CTAS commands don't extend `DataWritigCommand`, and we don't have the UI hack in `FileFormatWriter` anymore, so the UI for CTAS is just an empty node. See https://issues.apache.org/jira/browse/SPARK-22977 for more information about this UI issue. To fix it, we should apply the `DataWritigCommand` mechanism to CTAS commands. TODO: In the future, we should refactor this part and create some physical layer code pieces for data writing, and reuse them in different writing commands. We should have different logical nodes for different operators, even some of them share some same logic, e.g. CTAS, CREATE TABLE, INSERT TABLE. Internally we can share the same physical logic. ## How was this patch tested? manually tested. For data source table <img width="644" alt="1" src="https://user-images.githubusercontent.com/3182036/35874155-bdffab28-0ba6-11e8-94a8-e32e106ba069.png"> For hive table <img width="666" alt="2" src="https://user-images.githubusercontent.com/3182036/35874161-c437e2a8-0ba6-11e8-98ed-7930f01432c5.png"> Author: Wenchen Fan <wenchen@databricks.com> Closes #20521 from cloud-fan/UI. (cherry picked from commit 0e2c266) Signed-off-by: Wenchen Fan <wenchen@databricks.com>
{kind=link}
{kind=link}
…cation ## What changes were proposed in this pull request? In the `getBlockData`,`blockId.reduceId` is the `Int` type, when it is greater than 2^28, `blockId.reduceId*8` will overflow In the `decompress0`, `len` and `unitSize` are Int type, so `len * unitSize` may lead to overflow ## How was this patch tested? N/A Author: liuxian <liu.xian3@zte.com.cn> Closes #20581 from 10110346/overflow2. (cherry picked from commit 4a4dd4f) Signed-off-by: Sean Owen <sowen@cloudera.com>
…edColumnReader ## What changes were proposed in this pull request? Re-add support for parquet binary DecimalType in VectorizedColumnReader ## How was this patch tested? Existing test suite Author: James Thompson <jamesthomp@users.noreply.github.com> Closes #20580 from jamesthomp/jt/add-back-binary-decimal. (cherry picked from commit 5bb1141) Signed-off-by: gatorsmile <gatorsmile@gmail.com>
…l schema doesn't have metadata. ## What changes were proposed in this pull request? This is a follow-up pr of #19231 which modified the behavior to remove metadata from JDBC table schema. This pr adds a test to check if the schema doesn't have metadata. ## How was this patch tested? Added a test and existing tests. Author: Takuya UESHIN <ueshin@databricks.com> Closes #20585 from ueshin/issues/SPARK-22002/fup1. (cherry picked from commit 0c66fe4) Signed-off-by: gatorsmile <gatorsmile@gmail.com>
## What changes were proposed in this pull request? This PR adds a migration guide documentation for ORC. 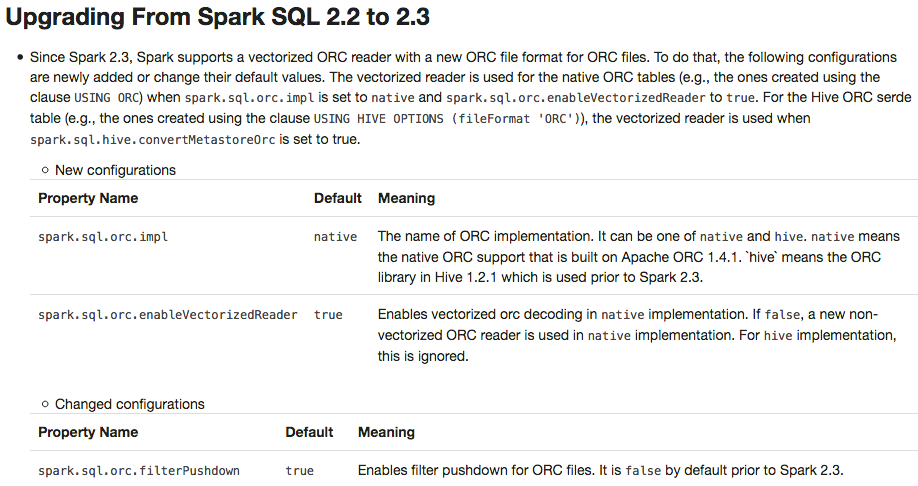 ## How was this patch tested? N/A. Author: Dongjoon Hyun <dongjoon@apache.org> Closes #20484 from dongjoon-hyun/SPARK-23313. (cherry picked from commit 6cb5970) Signed-off-by: gatorsmile <gatorsmile@gmail.com>
{kind=link}
…e types, create textfile table cause a serde error When hive.default.fileformat is other kinds of file types, create textfile table cause a serde error. We should take the default type of textfile and sequencefile both as org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe. ``` set hive.default.fileformat=orc; create table tbl( i string ) stored as textfile; desc formatted tbl; Serde Library org.apache.hadoop.hive.ql.io.orc.OrcSerde InputFormat org.apache.hadoop.mapred.TextInputFormat OutputFormat org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat ``` Author: sychen <sychen@ctrip.com> Closes #20406 from cxzl25/default_serde. (cherry picked from commit 4104b68) Signed-off-by: gatorsmile <gatorsmile@gmail.com>
…in Pandas UDFs ## What changes were proposed in this pull request? This PR backports #20531: It explicitly specifies supported types in Pandas UDFs. The main change here is to add a deduplicated and explicit type checking in `returnType` ahead with documenting this; however, it happened to fix multiple things. 1. Currently, we don't support `BinaryType` in Pandas UDFs, for example, see: ```python from pyspark.sql.functions import pandas_udf pudf = pandas_udf(lambda x: x, "binary") df = spark.createDataFrame([[bytearray(1)]]) df.select(pudf("_1")).show() ``` ``` ... TypeError: Unsupported type in conversion to Arrow: BinaryType ``` We can document this behaviour for its guide. 2. Since we can check the return type ahead, we can fail fast before actual execution. ```python # we can fail fast at this stage because we know the schema ahead pandas_udf(lambda x: x, BinaryType()) ``` ## How was this patch tested? Manually tested and unit tests for `BinaryType` and `ArrayType(...)` were added. Author: hyukjinkwon <gurwls223@gmail.com> Closes #20588 from HyukjinKwon/PR_TOOL_PICK_PR_20531_BRANCH-2.3.
## What changes were proposed in this pull request? Deprecating the field `name` in PySpark is not expected. This PR is to revert the change. ## How was this patch tested? N/A Author: gatorsmile <gatorsmile@gmail.com> Closes #20595 from gatorsmile/removeDeprecate. (cherry picked from commit 407f672) Signed-off-by: hyukjinkwon <gurwls223@gmail.com>
…ns found, the last updated time is not formatted and client local time zone is not show in history server web ui. ## What changes were proposed in this pull request? When it has no incomplete(completed) applications found, the last updated time is not formatted and client local time zone is not show in history server web ui. It is a bug. fix before:  fix after:  ## How was this patch tested? (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. Author: guoxiaolong <guo.xiaolong1@zte.com.cn> Closes #20573 from guoxiaolongzte/SPARK-23384. (cherry picked from commit 300c40f) Signed-off-by: Sean Owen <sowen@cloudera.com>
{kind=link}
{kind=link}
…late in DagScheduler.submitMissingTasks should keep the same RDD checkpoint status ## What changes were proposed in this pull request? When we run concurrent jobs using the same rdd which is marked to do checkpoint. If one job has finished running the job, and start the process of RDD.doCheckpoint, while another job is submitted, then submitStage and submitMissingTasks will be called. In [submitMissingTasks](https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/scheduler/DAGScheduler.scala#L961), will serialize taskBinaryBytes and calculate task partitions which are both affected by the status of checkpoint, if the former is calculated before doCheckpoint finished, while the latter is calculated after doCheckpoint finished, when run task, rdd.compute will be called, for some rdds with particular partition type such as [UnionRDD](https://github.com/apache/spark/blob/master/core/src/main/scala/org/apache/spark/rdd/UnionRDD.scala) who will do partition type cast, will get a ClassCastException because the part params is actually a CheckpointRDDPartition. This error occurs because rdd.doCheckpoint occurs in the same thread that called sc.runJob, while the task serialization occurs in the DAGSchedulers event loop. ## How was this patch tested? the exist uts and also add a test case in DAGScheduerSuite to show the exception case. Author: huangtengfei <huangtengfei@huangtengfeideMacBook-Pro.local> Closes #20244 from ivoson/branch-taskpart-mistype. (cherry picked from commit 091a000) Signed-off-by: Imran Rashid <irashid@cloudera.com>
…plain column assignment ## What changes were proposed in this pull request? Added sections to pandas_udf docs, in the grouped map section, to indicate columns are assigned by position. Backported to branch-2.3. ## How was this patch tested? NA Author: Bryan Cutler <cutlerb@gmail.com> Closes #21478 from BryanCutler/arrow-doc-pandas_udf-column_by_pos-2_3_1-SPARK-21427.
…regations having the same argument set" This reverts commit 66289a3.
…s having the same argument set ## What changes were proposed in this pull request? bring back #21443 This is a different approach: just change the check to count distinct columns with `toSet` ## How was this patch tested? a new test to verify the planner behavior. Author: Wenchen Fan <wenchen@databricks.com> Author: Takeshi Yamamuro <yamamuro@apache.org> Closes #21487 from cloud-fan/back. (cherry picked from commit 416cd1f) Signed-off-by: Xiao Li <gatorsmile@gmail.com>
… decimal operations ## What changes were proposed in this pull request? In SPARK-22036 we introduced the possibility to allow precision loss in arithmetic operations (according to the SQL standard). The implementation was drawn from Hive's one, where Decimals with a negative scale are not allowed in the operations. The PR handles the case when the scale is negative, removing the assertion that it is not. ## How was this patch tested? added UTs Author: Marco Gaido <marcogaido91@gmail.com> Closes #21499 from mgaido91/SPARK-24468. (cherry picked from commit f07c506) Signed-off-by: Wenchen Fan <wenchen@databricks.com>
Apply the suggestion on the bug to fix source links. Tested with the 2.3.1 release docs. Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #21521 from vanzin/SPARK-23732.
## What changes were proposed in this pull request? `UnsafeRowSerializerSuite` calls `UnsafeProjection.create` which accesses `SQLConf.get`, while the current active SparkSession may already be stopped, and we may hit exception like this ``` sbt.ForkMain$ForkError: java.lang.IllegalStateException: LiveListenerBus is stopped. at org.apache.spark.scheduler.LiveListenerBus.addToQueue(LiveListenerBus.scala:97) at org.apache.spark.scheduler.LiveListenerBus.addToStatusQueue(LiveListenerBus.scala:80) at org.apache.spark.sql.internal.SharedState.<init>(SharedState.scala:93) at org.apache.spark.sql.SparkSession$$anonfun$sharedState$1.apply(SparkSession.scala:120) at org.apache.spark.sql.SparkSession$$anonfun$sharedState$1.apply(SparkSession.scala:120) at scala.Option.getOrElse(Option.scala:121) at org.apache.spark.sql.SparkSession.sharedState$lzycompute(SparkSession.scala:120) at org.apache.spark.sql.SparkSession.sharedState(SparkSession.scala:119) at org.apache.spark.sql.internal.BaseSessionStateBuilder.build(BaseSessionStateBuilder.scala:286) at org.apache.spark.sql.test.TestSparkSession.sessionState$lzycompute(TestSQLContext.scala:42) at org.apache.spark.sql.test.TestSparkSession.sessionState(TestSQLContext.scala:41) at org.apache.spark.sql.SparkSession$$anonfun$1$$anonfun$apply$1.apply(SparkSession.scala:95) at org.apache.spark.sql.SparkSession$$anonfun$1$$anonfun$apply$1.apply(SparkSession.scala:95) at scala.Option.map(Option.scala:146) at org.apache.spark.sql.SparkSession$$anonfun$1.apply(SparkSession.scala:95) at org.apache.spark.sql.SparkSession$$anonfun$1.apply(SparkSession.scala:94) at org.apache.spark.sql.internal.SQLConf$.get(SQLConf.scala:126) at org.apache.spark.sql.catalyst.expressions.CodeGeneratorWithInterpretedFallback.createObject(CodeGeneratorWithInterpretedFallback.scala:54) at org.apache.spark.sql.catalyst.expressions.UnsafeProjection$.create(Projection.scala:157) at org.apache.spark.sql.catalyst.expressions.UnsafeProjection$.create(Projection.scala:150) at org.apache.spark.sql.execution.UnsafeRowSerializerSuite.org$apache$spark$sql$execution$UnsafeRowSerializerSuite$$unsafeRowConverter(UnsafeRowSerializerSuite.scala:54) at org.apache.spark.sql.execution.UnsafeRowSerializerSuite.org$apache$spark$sql$execution$UnsafeRowSerializerSuite$$toUnsafeRow(UnsafeRowSerializerSuite.scala:49) at org.apache.spark.sql.execution.UnsafeRowSerializerSuite$$anonfun$2.apply(UnsafeRowSerializerSuite.scala:63) at org.apache.spark.sql.execution.UnsafeRowSerializerSuite$$anonfun$2.apply(UnsafeRowSerializerSuite.scala:60) ... ``` ## How was this patch tested? N/A Author: Wenchen Fan <wenchen@databricks.com> Closes #21518 from cloud-fan/test. (cherry picked from commit 01452ea) Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…veExternalCatalogVersionsSuite ## What changes were proposed in this pull request? Removing version 2.2.0 from testing versions in HiveExternalCatalogVersionsSuite as it is not present anymore in the mirrors and this is blocking all the open PRs. ## How was this patch tested? running UTs Author: Marco Gaido <marcogaido91@gmail.com> Closes #21540 from mgaido91/SPARK-24531. (cherry picked from commit 2824f14) Signed-off-by: Xiao Li <gatorsmile@gmail.com>
## What changes were proposed in this pull request? Currently, `spark.ui.filters` are not applied to the handlers added after binding the server. This means that every page which is added after starting the UI will not have the filters configured on it. This can allow unauthorized access to the pages. The PR adds the filters also to the handlers added after the UI starts. ## How was this patch tested? manual tests (without the patch, starting the thriftserver with `--conf spark.ui.filters=org.apache.hadoop.security.authentication.server.AuthenticationFilter --conf spark.org.apache.hadoop.security.authentication.server.AuthenticationFilter.params="type=simple"` you can access `http://localhost:4040/sqlserver`; with the patch, 401 is the response as for the other pages). Author: Marco Gaido <marcogaido91@gmail.com> Closes #21523 from mgaido91/SPARK-24506. (cherry picked from commit f53818d) Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
… wrapping from driver to executor SPARK-23754 was fixed in #21383 by changing the UDF code to wrap the user function, but this required a hack to save its argspec. This PR reverts this change and fixes the `StopIteration` bug in the worker. The root of the problem is that when an user-supplied function raises a `StopIteration`, pyspark might stop processing data, if this function is used in a for-loop. The solution is to catch `StopIteration`s exceptions and re-raise them as `RuntimeError`s, so that the execution fails and the error is reported to the user. This is done using the `fail_on_stopiteration` wrapper, in different ways depending on where the function is used: - In RDDs, the user function is wrapped in the driver, because this function is also called in the driver itself. - In SQL UDFs, the function is wrapped in the worker, since all processing happens there. Moreover, the worker needs the signature of the user function, which is lost when wrapping it, but passing this signature to the worker requires a not so nice hack. HyukjinKwon Author: edorigatti <emilio.dorigatti@gmail.com> Author: e-dorigatti <emilio.dorigatti@gmail.com> Closes #21538 from e-dorigatti/branch-2.3.
## What changes were proposed in this pull request? We don't require specific ordering of the input data, the sort action is not necessary and misleading. ## How was this patch tested? Existing test suite. Author: Xingbo Jiang <xingbo.jiang@databricks.com> Closes #21536 from jiangxb1987/sorterSuite. (cherry picked from commit 534065e) Signed-off-by: hyukjinkwon <gurwls223@apache.org>
…ng equal keys `EnsureRequirement` in its `reorder` method currently assumes that the same key appears only once in the join condition. This of course might not be the case, and when it is not satisfied, it returns a wrong plan which produces a wrong result of the query. added UT Author: Marco Gaido <marcogaido91@gmail.com> Closes #21529 from mgaido91/SPARK-24495. (cherry picked from commit fdadc4b) Signed-off-by: Xiao Li <gatorsmile@gmail.com>
## What changes were proposed in this pull request? Fix typo in exception raised in Python serializer ## How was this patch tested? No code changes Please review http://spark.apache.org/contributing.html before opening a pull request. Author: Ruben Berenguel Montoro <ruben@mostlymaths.net> Closes #21566 from rberenguel/fix_typo_pyspark_serializers. (cherry picked from commit 6567fc4) Signed-off-by: hyukjinkwon <gurwls223@apache.org>
## What changes were proposed in this pull request?
There is a performance regression in Spark 2.3. When we read a big compressed text file which is un-splittable(e.g. gz), and then take the first record, Spark will scan all the data in the text file which is very slow. For example, `spark.read.text("/tmp/test.csv.gz").head(1)`, we can check out the SQL UI and see that the file is fully scanned.
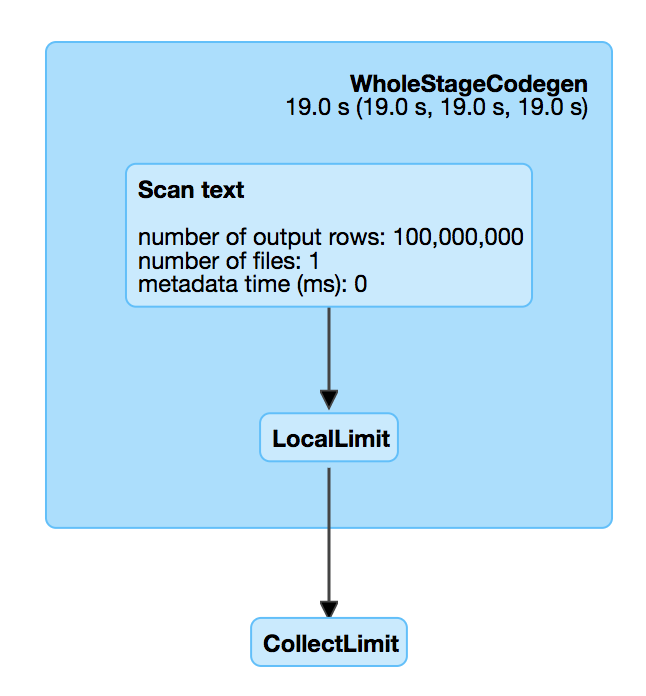
This is introduced by #18955 , which adds a LocalLimit to the query when executing `Dataset.head`. The foundamental problem is, `Limit` is not well whole-stage-codegened. It keeps consuming the input even if we have already hit the limitation.
However, if we just fix LIMIT whole-stage-codegen, the memory leak test will fail, as we don't fully consume the inputs to trigger the resource cleanup.
To fix it completely, we should do the following
1. fix LIMIT whole-stage-codegen, stop consuming inputs after hitting the limitation.
2. in whole-stage-codegen, provide a way to release resource of the parant operator, and apply it in LIMIT
3. automatically release resource when task ends.
Howere this is a non-trivial change, and is risky to backport to Spark 2.3.
This PR proposes to revert #18955 in Spark 2.3. The memory leak is not a big issue. When task ends, Spark will release all the pages allocated by this task, which is kind of releasing most of the resources.
I'll submit a exhaustive fix to master later.
## How was this patch tested?
N/A
Author: Wenchen Fan <wenchen@databricks.com>
Closes #21573 from cloud-fan/limit.
{kind=link}
This PR fixes possible overflow in int add or multiply. In particular, their overflows in multiply are detected by [Spotbugs](https://spotbugs.github.io/) The following assignments may cause overflow in right hand side. As a result, the result may be negative. ``` long = int * int long = int + int ``` To avoid this problem, this PR performs cast from int to long in right hand side. Existing UTs. Author: Kazuaki Ishizaki <ishizaki@jp.ibm.com> Closes #21481 from kiszk/SPARK-24452. (cherry picked from commit 90da7dc) Signed-off-by: Wenchen Fan <wenchen@databricks.com>
…that is not safe in scala When user create a aggregator object in scala and pass the aggregator to Spark Dataset's agg() method, Spark's will initialize TypedAggregateExpression with the nodeName field as aggregator.getClass.getSimpleName. However, getSimpleName is not safe in scala environment, depending on how user creates the aggregator object. For example, if the aggregator class full qualified name is "com.my.company.MyUtils$myAgg$2$", the getSimpleName will throw java.lang.InternalError "Malformed class name". This has been reported in scalatest scalatest/scalatest#1044 and discussed in many scala upstream jiras such as SI-8110, SI-5425. To fix this issue, we follow the solution in scalatest/scalatest#1044 to add safer version of getSimpleName as a util method, and TypedAggregateExpression will invoke this util method rather than getClass.getSimpleName. added unit test Author: Fangshi Li <fli@linkedin.com> Closes #21276 from fangshil/SPARK-24216. (cherry picked from commit cc88d7f) Signed-off-by: Wenchen Fan <wenchen@databricks.com>
Because of the missing assignment of the variable `BUILD_ARGS` the command `./bin/docker-image-tool.sh -r docker.io/myrepo -t v2.3.1 build` fails: ``` docker build" requires exactly 1 argument. See 'docker build --help'. Usage: docker build [OPTIONS] PATH | URL | - [flags] Build an image from a Dockerfile ``` This has been fixed on the `master` already but, apparently, it has not been ported back to the branch `2.3`, leading to the same error even on the latest `2.3.1` release (dated 8 June 2018). Author: Fabrizio Cucci <fabrizio.cucci@gmail.com> Closes #21551 from fabriziocucci/patch-1.
…lly crafted XML to access arbitrary files ## What changes were proposed in this pull request? UDF series UDFXPathXXXX allow users to pass carefully crafted XML to access arbitrary files. Spark does not have built-in access control. When users use the external access control library, users might bypass them and access the file contents. This PR basically patches the Hive fix to Apache Spark. https://issues.apache.org/jira/browse/HIVE-18879 ## How was this patch tested? A unit test case Author: Xiao Li <gatorsmile@gmail.com> Closes #21549 from gatorsmile/xpathSecurity. (cherry picked from commit 9a75c18) Signed-off-by: Wenchen Fan <wenchen@databricks.com>
## What changes were proposed in this pull request? Change insert input schema type: "insertRelationType" -> "insertRelationType.asNullable", in order to avoid nullable being overridden. ## How was this patch tested? Added one test in InsertSuite. Author: Maryann Xue <maryannxue@apache.org> Closes #21585 from maryannxue/spark-24583. (cherry picked from commit bc0498d) Signed-off-by: Xiao Li <gatorsmile@gmail.com>
## What changes were proposed in this pull request? This PR tries to fix the performance regression introduced by SPARK-21517. In our production job, we performed many parallel computations, with high possibility, some task could be scheduled to a host-2 where it needs to read the cache block data from host-1. Often, this big transfer makes the cluster suffer time out issue (it will retry 3 times, each with 120s timeout, and then do recompute to put the cache block into the local MemoryStore). The root cause is that we don't do `consolidateIfNeeded` anymore as we are using ``` Unpooled.wrappedBuffer(chunks.length, getChunks(): _*) ``` in ChunkedByteBuffer. If we have many small chunks, it could cause the `buf.notBuffer(...)` have very bad performance in the case that we have to call `copyByteBuf(...)` many times. ## How was this patch tested? Existing unit tests and also test in production Author: Wenbo Zhao <wzhao@twosigma.com> Closes #21593 from WenboZhao/spark-24578. (cherry picked from commit 3f4bda7) Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
…ator. When an output stage is retried, it's possible that tasks from the previous attempt are still running. In that case, there would be a new task for the same partition in the new attempt, and the coordinator would allow both tasks to commit their output since it did not keep track of stage attempts. The change adds more information to the stage state tracked by the coordinator, so that only one task is allowed to commit the output in the above case. The stage state in the coordinator is also maintained across stage retries, so that a stray speculative task from a previous stage attempt is not allowed to commit. This also removes some code added in SPARK-18113 that allowed for duplicate commit requests; with the RPC code used in Spark 2, that situation cannot happen, so there is no need to handle it. Author: Marcelo Vanzin <vanzin@cloudera.com> Closes #21577 from vanzin/SPARK-24552. (cherry picked from commit c8e909c) Signed-off-by: Thomas Graves <tgraves@apache.org>
…ning from children ## What changes were proposed in this pull request? In #19080 we simplified the distribution/partitioning framework, and make all the join-like operators require `HashClusteredDistribution` from children. Unfortunately streaming join operator was missed. This can cause wrong result. Think about ``` val input1 = MemoryStream[Int] val input2 = MemoryStream[Int] val df1 = input1.toDF.select('value as 'a, 'value * 2 as 'b) val df2 = input2.toDF.select('value as 'a, 'value * 2 as 'b).repartition('b) val joined = df1.join(df2, Seq("a", "b")).select('a) ``` The physical plan is ``` *(3) Project [a#5] +- StreamingSymmetricHashJoin [a#5, b#6], [a#10, b#11], Inner, condition = [ leftOnly = null, rightOnly = null, both = null, full = null ], state info [ checkpoint = <unknown>, runId = 54e31fce-f055-4686-b75d-fcd2b076f8d8, opId = 0, ver = 0, numPartitions = 5], 0, state cleanup [ left = null, right = null ] :- Exchange hashpartitioning(a#5, b#6, 5) : +- *(1) Project [value#1 AS a#5, (value#1 * 2) AS b#6] : +- StreamingRelation MemoryStream[value#1], [value#1] +- Exchange hashpartitioning(b#11, 5) +- *(2) Project [value#3 AS a#10, (value#3 * 2) AS b#11] +- StreamingRelation MemoryStream[value#3], [value#3] ``` The left table is hash partitioned by `a, b`, while the right table is hash partitioned by `b`. This means, we may have a matching record that is in different partitions, which should be in the output but not. ## How was this patch tested? N/A Author: Wenchen Fan <wenchen@databricks.com> Closes #21587 from cloud-fan/join. (cherry picked from commit dc8a6be) Signed-off-by: Xiao Li <gatorsmile@gmail.com>
|
Can one of the admins verify this patch? |
|
@larry88, looks mistakenly open. Mind closing this please? |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
What changes were proposed in this pull request?
(Please fill in changes proposed in this fix)
How was this patch tested?
(Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests)
(If this patch involves UI changes, please attach a screenshot; otherwise, remove this)
Please review http://spark.apache.org/contributing.html before opening a pull request.