kvserver: benchmark different cpu load based split thresholds #96869
Comments
|
I ran
Most values fall within the range seen on roachperf within the last two weeks. The current default (250ms).
Notes:
Follow up questions and actions:
|






|
I ran
Standard Deviation
Notes
Longer term, increasing the threshold or removing it entirely in favor of the allocator splitting when necessary seems like the best strategy. The current threshold of |








96107: build,ci,release: add Linux x86_64 FIPS build r=rickystewart a=rail * Added a script to build [golang-fips](https://github.com/golang-fips/go). The resulted Go version has a `fips` suffix, so we can easily select it in Bazel. * Added a new Bazel toolchain and build config used by the FIPS build only. * The FIPS docker image has FIPS-compliant `openssl` installed. * Added a script to run FIPS build in CI. * Tweaked one of the regexes to be less greedy. * Added the platform to the release process. Epic: DEVINF-478 Fixes: DEVINF-634 Fixes: DEVINF-633 Release note (build change): As a part of this change we start publishing a FIPS compliant tarball and docker image for the Linux x86_64 platform. The build uses OpenSSL libraries for crypto operations by `dlopen`ing the corresponding dynamic libraries. 97113: kvserver: increase cpu lb split threshold to 500ms r=nvanbenschoten a=kvoli This commit increases the default value of `kv.range_split.load_cpu_threshold` to `500ms` from the previous default value of `250ms`. Experiments detailed in #96869 showed moderate performance gains between `500ms` and `250ms`, without a significant downside on rebalancing. Resolves: #96869 Release note (ops change): The default value of `kv.range_split.load_cpu_threshold` is increased from `250ms` to `500ms`. This threshold declares the CPU per-second value above which a range will be split. The value was selected based on performance experiments. 97359: upgrades: fix race condition inside TestUpgradeSchemaChangerElements r=fqazi a=fqazi Previously, this test non-atomically update the job ID, which could lead to race conditions if jobs queries ran for any other reason than our expected one. This was inadequate because the race detector would detect issues with this value being modified. To address this, this patch only stores/loads the job ID atomically. Fixes: #97284 Release note: None 97398: storage: add guardrails to rocksdb.min_wal_sync_interval r=nvanbenschoten a=nvanbenschoten This commit prevents `rocksdb.min_wal_sync_interval` from being set to a negative value or from being set to a value above 1s. This prevents the cluster setting from being used to break node liveness and put a cluster into an unrecoverable state. Release note: None Epic: None 97405: ui: update cluster-ui to 23.1.0-prerelease.4 r=ericharmeling a=ericharmeling This commit updates the cluster-ui version to 23.1.0-prerelease.4. Release note: None Epic: None Co-authored-by: Rail Aliiev <rail@iqchoice.com> Co-authored-by: Austen McClernon <austen@cockroachlabs.com> Co-authored-by: Faizan Qazi <faizan@cockroachlabs.com> Co-authored-by: Nathan VanBenschoten <nvanbenschoten@gmail.com> Co-authored-by: Eric Harmeling <eric.harmeling@cockroachlabs.com>
97717: multitenant: add AdminUnsplitRequest capability r=knz a=ecwall Fixes #97716 1) Add a new `tenantcapabilitiespb.CanAdminUnsplit` capability. 2) Check capability in `Authorizer.HasCapabilityForBatch`. 3) Remove `ExecutorConfig.RequireSystemTenant` call from `execFactory.ConstructAlterTableUnsplit`, `execFactory.ConstructAlterTableUnsplitAll`. Release note: None 98250: kvserver: add minimum cpu lb split threshold r=andrewbaptist a=kvoli Previously, `kv.range_split.load_cpu_threshold` had no minimum setting value. It is undesirable to allow users to set this setting to low as excessive splitting may occur. `kv.range_split.load_cpu_threshold` now has a minimum setting value of `10ms`. See #96869 for additional context on the threshold. Resolves: #98107 Release note (ops change): `kv.range_split.load_cpu_threshold` now has a minimum setting value of `10ms`. 98270: dashboards: add replica cpu to repl dashboard r=xinhaoz a=kvoli In #96127 we added the option to load balance replica CPU instead of QPS across stores in a cluster. It is desirable to view the signal being controlled for rebalancing in the replication dashboard, similar to QPS. This pr adds the `rebalancing.cpunanospersecond` metric to the replication metrics dashboard. The avg QPS graph on the replication graph previously described the metric as "Exponentially weighted average", however this is not true. This pr updates the description to just be "moving average" which is accurate. Note that follow the workload does use an exponentially weighted value, however the metric in the dashboard is not the same. This pr also updates the graph header to include Replica in the title: "Average Replica Queries per Node". QPS is specific to replicas. This is already mentioned in the description. Resolves: #98109 98289: storage: mvccExportToWriter should always return buffered range keys r=adityamaru a=stevendanna In #96691, we changed the return type of mvccExportToWriter such that it now indicates when a CPU limit has been reached. As part of that change, when the CPU limit was reached, we would immedately `return` rather than `break`ing out of the loop. This introduced a bug, since the code after the loop that the `break` was taking us to is important. Namely, we may have previously buffered range keys that we need to write into our response still. By replacing the break with a return, these range keys were lost. The end-user impact of this is that a BACKUP that _ought_ to have included range keys (such as a backup of a table with a rolled back IMPORT) would not include those range keys and thus would end up resurecting deleted keys upon restore. This PR brings back the `break` and adds a test that covers exporting with range keys under CPU exhaustion. This bug only ever existed on master. Informs #97694 Epic: none Release note: None 98329: sql: fix iteration conditions in crdb_internal.scan r=ajwerner a=stevendanna Rather than using the Next() key of the last key in the response when iterating, we should use the resume span. The previous code could result in a failure in the rare case that the end key of our scan exactly matched the successor key of the very last key in the iteration. Epic: none Release note: None Co-authored-by: Evan Wall <wall@cockroachlabs.com> Co-authored-by: Austen McClernon <austen@cockroachlabs.com> Co-authored-by: Steven Danna <danna@cockroachlabs.com>
#96128 Adds support for splitting a range once its leaseholder replica uses more CPU than
kv.range_split.load_cpu_threshold. The default value ofkv.range_split.load_cpu_thresholdis250msof CPU use per second, or 1/4 of a CPU core.This issue is to benchmark performance with different
kv.range_split.load_cpu_thresholdvalues set. The results should then inform a default value.More specifically, benchmark ycsb, kv0, kv95 on three nodes and bisect a value that achieves the highest throughput.
The current value was selected by observing the performance of the cluster from a rebalancing perspective. The specific criteria was to constrain the occurrences of a store being overfull relative to the mean but not having any actions available to resolve being overfull. When running TPCE (50k), CPU splitting with a 250ms threshold performed 1 load based split whilst QPS splitting (2500) performed 12.5.
When running the allocbench/*/kv roachtest suite, CPU splitting (250ms) tended to make between 33-100% more load based splits than QPS splitting (2500) on workloads involving reads (usually large scans), whilst on the write heavy workloads the number of load based splits was identically low.
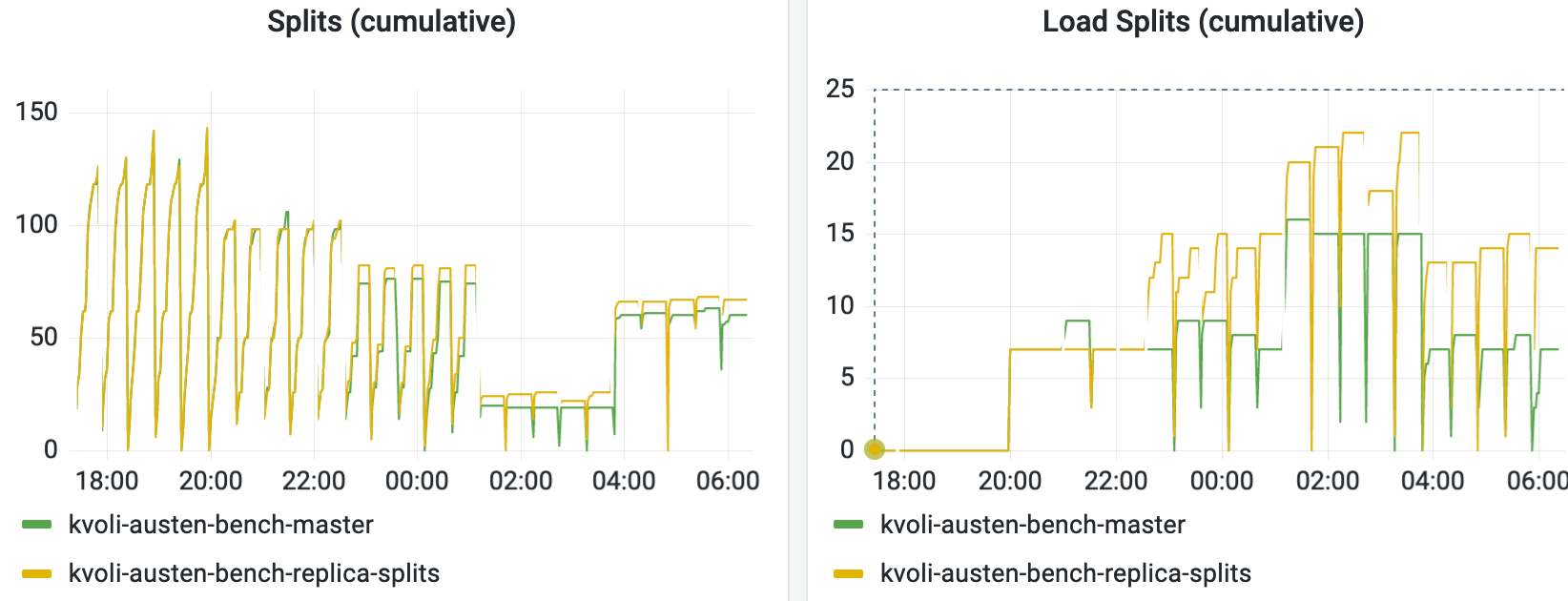
Here's a comparison of splits running TPCE between master(qps splits)/this branch with 250ms:
The same for allocbench (5 runs of each type, order is r=0/access=skew, r=0/ops=skew, r=50/ops=skew, r=95/access=skew, r=95/ops=skew.
Jira issue: CRDB-24382
The text was updated successfully, but these errors were encountered: