2.1. Using the Command Line Interface
This section describes how to run Saffron term extraction and taxonomy construction steps through the command line interface, as well as how to customize the configuration in the advanced mode.
(Note, MongoDB was chosen to be used for Saffron, it has to be running before any attempt to use Saffron: sudo systemctl status mongod)
All steps of Saffron can be executed by running the saffron.sh script (located in the main "saffron-master" folder), without using the Web Interface. This script takes three arguments:
- The path to the corpus, which may be:
- A folder containing files in TXT, DOC or PDF
- A zip or tar.gz file containing files in TXT, DOC or PDF
- A Json metadata file describing the corpus (see below more details on the format of this file)
- The path to the output folder to which the results are written
- The path to the configuration file (see below more details on the format of this file)
For example, for a corpus in JSON file:
cd ~/YOUR_SAFFRON_PATH/saffron-master
./saffron.sh ~/YOUR_EXPERIMENT_FOLDER/corpus.json ~/YOUR_EXPERIMENT_FOLDER/output/ ~/YOUR_EXPERIMENT_FOLDER/config.json
or for a corpus in a ZIP folder:
cd ~/YOUR_SAFFRON_PATH/saffron-master
./saffron.sh ~/YOUR_EXPERIMENT_FOLDER/corpus.zip ~/YOUR_EXPERIMENT_FOLDER/output/ ~/YOUR_EXPERIMENT_FOLDER/config.json
Configuration (config.json)
{kind=link}
(Note that all formats of input and output files are also described in FORMATS.md)
To run Saffron using the command line, you need first to create a configuration file. For convenience we name it by default config.json, but there is no restriction on the name to give. This file is following a specific JSON format, described in this section.
Note: “Saffron score” refers to the score calculated which measures how likely a given expression is also a potential term to be considered for the domain.

This input file for the command line interface (generated automatically if using the user interface) describes all options from the different steps of Saffron. See the wiki for more details on what each property does, and the approaches followed by the algorithm. The config file contains each of the Saffron steps (see below for an example of config.json:
Configuration for the options of the term ./extraction phase. All properties are included under the object:
-
termExtraction: This configuration is about the extraction of the terms from the corpus. The element contains the following properties to set up:-
threshold: Sets a minimum Saffron score for an expression to be considered a term. Since the score depends on the type of function chosen to extract terms, unless you have a good knowledge of the function algorithm and the type of scoring it provides, we recommend to leave it to zero. -
maxTerms: Sets the maximum number of terms to extract. The default is 100, which allows to visualize the taxonomy without too many overlaps between terms. We recommend 500 for a more extensive view of the domain, and a deeper taxonomy which is not aimed at being visualized but rather being further processed as data (as 500 terms is not easy to display). -
ngramMin: Sets the shortest length of term to consider (in terms of the number of words). The default is 1, which allows the taxonomy to contain single word terms, which are usually related to more generic terms (eg. “bank”). We recommend to set this to 2 if the goal is to focus more on an intermediate level of specificity in the terms (eg. “mutual fund”) -
ngramMax: Sets the longest length of term to consider (in terms of number of words). The default is 4, which according to our experience is a good maximum length for most use cases. -
minTermFreq: Sets the number of times an expression must appear in the dataset to be accepted as a term. This allows to filter noise and terms that are not used much. The default is 2, which can be raised if the corpus is of an extensive size. -
maxDocs: The maximum number of documents to consider for the analysis. The default is 2147483647. This is the maximum number of documents allowed to be processed within Saffron 3 due to technical limitations. -
method: Choose between two ranking procedures: "voting" (An algorithm that integrates multiple scoring functions) and "single" (only one scoring function). -
features: List of scoring functions if the "voting" method above was selected, or will be ignored if the "single" method was chosen. The default set of features is ([ "comboBasic", "weirdness", "totalTfIdf", "cValue", "residualIdf" ]). The features include the choice between: comboBasic, weirdness, totalTfIdf, cValue, residualIdf, avgTermFreq, basic, novelTopicModel, postRankDC, relevance, futureBasic, futureComboBasic (see here for a description of the approach for each feature) -
corpus: #deprecated (reference corpus. By default set to ${saffron.home}/models/wiki-terms.json.gz) -
baseFeature: If method is set to "single", a unique scoring function shall be selected as a base. If method is set to "voting", choose the principal scoring function to be used. (Choose between the options given above in features). -
The following part of the configuration is about defining and customizing the linguistic structure of terms, potentially for a different language or different types of terms outside of the common Noun Phrase structure. We recommend using the default settings, which have proven to be the most effective ones to extract terms in a variety of use cases.
-
numThreads: #deprecated (The default was 0). -
posModel: The path to the part-of-speech tagger model. Only models from OpenNLP are currently supported. The default model is set to ("${saffron.home}/models/en-pos-maxent.bin") and it is provided during the installation of Saffron. -
tokenizerModel: The path to the tokenizer model. Only models from OpenNLP are currently supported. The default is set to "null" (the configuration will automatically use the one English tokenizer that is provided by OpenNLP). -
lemmatizerModel: The path to the lemmatizer model. Only models from OpenNLP are currently supported. The default is set to ("${saffron.home}/models/en-lemmatizer.dict.txt") and is provided during the installation of Saffron. -
stopWords: The path to a list of stop words (one per line) if different from the default stopwords file. -
preceedingTokens: The set of tags allowed in non-final position in a noun phrase. The default tagset is ["NN", "JJ", "NNP", "NNS"]. -
middleTokens: The set of tags allowed in non-final position, but not completing. The default tag is set to ["IN"]. -
headTokens: The set of final tags allows in a noun phrase. The default is set to ["NN", "CD", "NNS"]. -
headTokenFinal: The position of the head of a noun phrase. Default value is set to "true" which means "final". -
blacklist: A list of terms that should never be generated. The default is an empty list. -
blacklistFile: The path to a text file containing a list of terms that should never be generated (one term per line). Null is the default value. -
intervalDays: The length of time (in days) to use as intervals in temporal prediction or negative to disable temporal prediction. This is used only for features futureBasic and futureComboBasic (for term prediction) The default is 365. -
oneTermPerDoc: If set, always output at least one term for each input document (overrides maxTerms if necessary). The default value is false.
-
This part is responsible for the step that relates the author of documents in the corpus with the terms extracted from the corpus. The authors are considered experts. Explanation of the approach is provided in the “Approaches” section below.
-
authorTerm: An element which contains the following property to set up:-
topN: The maximum number of total author-term pairs to extract. The default is 1000. -
minDocs: Minimum number of documents for the author to have in the corpus for him to be considered for the author-term extraction calculations. To focus more on experts, we recommend setting this to 2 minimum.
-
The phase of connecting authors with similar areas of expertise together (Only if authors are present in the metadata, ignored otherwise).
-
authorSim: An element which contains the following properties to set up:-
Threshold: The minimum threshold for the similarity score between two authors. The default is set to 0.1. -
topN: The maximum number of similar authors (per author) to extract. The default number is set to 50. Note that this algorithm is resource intensive, therefore you may not want to set a topN too high, in particular if running a single machine with few resources.
-
The phase of connecting similar terms.
-
termSim: An element contains the following properties to set up:-
threshold: The minimum threshold for the similarity score between two terms. The default threshold is 0.1. -
topN: The maximum number of terms to accept. The default is set to 50 terms.
-
-
taxonomy: Taxonomy extraction using Pairwise Scoring model training. More information on the procedure behind this step here. It contains the following properties to set up:-
returnRDF: If True, returns the taxonomy as an RDF file. If False, the generated taxonomy will be as a JSON file (default set to False)
-
↣ Taxonomy extraction with Pairwise Scoring model training
The phase of supervised taxonomy extraction. To be used only if you want to train your own Pairwise Scoring model and not use the default one ("${saffron.home}/models/default.json”)
-
Pairwise scoring model features
-
negSampling: The number of negative samples to generate when training. The default number is set to 5.0 negative samples (only used for training the Pairwise Scoring model) -
features: The features to use, each of them can be set to "false" or "true", with default to "false". The default for the overall "features" property is set to null (only used for training the Pairwise Scoring model)-
gloveFile: The file containing the GloVe vectors or null if not used. -
hypernyms: The text file containing the hypernyms, one word per line. -
modelFile: The model to be trained. The default model is set to ${saffron.home}/models/default.json" and it is provided during the installation of Saffron (./install.sh). -
featureSelection: The feature selection (or null for all features). Each of them can be set to "false" or "true", with default to "false". The default for the overall "featureSelection" property is set to null. For more information on the implementation of these features, see Features.java. Choose between the following features (more details are given below in 4.1.1 Pairwise Scoring):-
inclusion: uses the inclusion feature: a string is said to include another string if it starts or ends with that string respecting word boundaries. -
overlap: uses the overlap feature, ie. the number of words that are in both strings divided by the length of the top string in the pair. -
lcs: uses the longest common subsequence feature, is. the longest common subsequence of words divided by the length of the top string in the pair. -
svdSimAve: uses the SVD Average Vector Similarity feature. Get the similarity of these vectors by using an inverse learned relation over average vectors. -
svdSimMinMax: uses the SVD Minimum-Maximum Vector Similarity feature. Get the similarity of these vectors by using an inverse learned relation over min-max vectors. -
topicDiff: uses the Topic Difference feature: document topic complement difference which is defined as -
relFreq: uses the relative frequency feature, ie. the relative frequency of the terms given as -
wnDirect: uses direct wordnet -
wnIndirect: uses indirect wordnet
-
-
Example: "features" : "gloveFile": "/home/.../ GloVe-1.2.zip", "hypernyms": "/.../.../XYZ.txt", "featureSelection": { "inclusion": true, "overlap": true}
-
↣ Taxonomy Search
The phase of search in the taxonomy algorithm that connects the terms together in order to build the taxonomy.
-
Search features
-
search: An element which contains the following properties to set up:-
algorithm: The algorithm to use for building a taxonomy structure. Choose between greedy, beam. The default algorithm is set to greedy. -
beamSize: The size of the beam to use in the beam search (only if Beam search is chosen, ignored otherwise). The default beam size is 20. -
score: The scoring function to optimize. Choose between simple, transitive, bhattacharryaPoisson. The default scoring function is simple. -
baseScore: The base metric for Bhattacharrya-Poisson (BP) (only if BP search is chosen, ignored otherwise). The default is set to simple. -
aveChildren: The average number of children (only if BP search is chosen, ignored otherwise). The default average is set to 3.0 children. -
alpha: The weighting to give to the BP (against the base algorithm) - (only if BP search is chosen, ignored otherwise). The default value is 0.01.
-
-
The phase of extraction of the knowledge graph using the input corpus and the terms extracted.
-
kg:-
returnRDF: If True, returns the kg as an RDF file. If False, the generated kg will be as a JSON file (default set to False) -
kerasModelFile: One of the two models needed to run the relation classifier for the kg extraction. The default model is set to “"${saffron.home}/models/model_keras.h5" and it is provided during the installation of Saffron (./install.sh) -
bertModelFile: The other one of the two models needed to run the relation classifier for the kg extraction. The default model is set to "${saffron.home}/models/bert_model/" and it is provided during the installation of Saffron (./install.sh) -
synonymyThreshold: Minimum score a candidate relation should have in order to be included in the knowledge graph as a synonymy. The default is set to 0.5 -
meronomyThreshold: Minimum score a candidate relation should have in order to be included in the knowledge graph as a meronymy (PartOf relation). The default is set to 0.25 -
enableSynonymyNormalisation: When set to true, aggregates all synonyms under a single term rather than having all of them appearing separately. The default is set to true.
-
Input files corpus.json
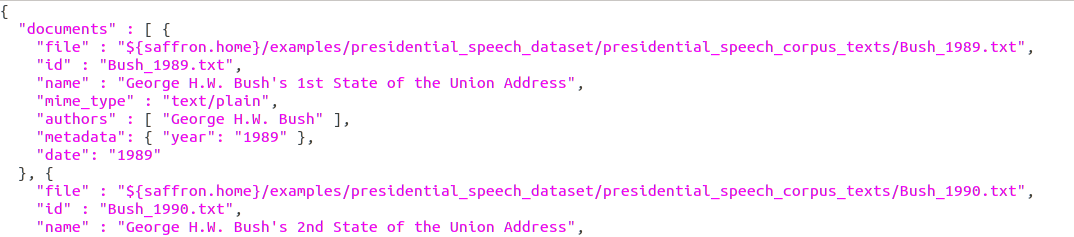
This file contains the description of the corpus, including all the metadata. It is a collection of documents, each entry being a different document with its own metadata and link to the file containing the text. A corpus has the following properties:
-
documents: A list of documents in the corpus. Each document of the list should have at least one of the following four:-
file: A string referring to the original version of this document on disk (absolute or relative path) (see input_corpus_inline.json. -
id: A unique string to identify the document -
url: The URL of the file -
contents: The text contents of the file (see input_corpus_files.json)
In addition the following attributes may be provided:
-
name: The human readable name of the document -
mime_type: The MIME type of the document -
authors: An array of authors of this documentFor each author of the document, provide:
- Either the name of the author as a string
- Or if more details on the author:
-
name: The author's name (required) -
id: A unique string to identify the author (optional) -
name_variants: An array of strings given other known variants of the name (optional)
-
-
metadata: An object containing any other properties. Each property is in the form:"property name":"property value", separated by commas -
date: The date of the document, formatted as iso8601, ie. YYYY-MM-DD or YYYY-MM or YYYY
-