Find_novel_viruses_B_palmdb
Update: palmID has been developed, which is a fully-automated web-app based approximately on this tutorial.
[2-4 hours] A high specificity based search for identifying RNA viruses in Serratus based on the RdRP palmprint sequences in PalmDB.
Conceptually this is analagous to performing a blastp/blastx search, with the reference database being a complete collection of RdRP sequences from GenBank (V241) and Serratus.
- Unix-based command-line
- Query RNA-dependent RNA Polymerase (RdRP) sequences
-
PalmDB: RdRP "palmprint" database -
DIAMOND(v2.0.9+) -
palmscan: palmprint detection tool -
muscle: multiple sequence alignment
Create a local copy of palmDB
git clone https://github.com/rcedgar/palmdb.git
gzip -dr palmdb/*
palmDB is a collection of RNA viral RdRP sequences, therefore your input sequences should contain an RdRP sequence inclusive of the palmprint barcoding sub-sequence, demarcated by Motif A, B and C.
You can use a single sequence to identify similar viruses, or a collection of related sequences (such as a complete family) to identify novel members of that family or similar.
For this example we will use the fragment of Waxsystermes Virus isolated from SRR9968562 in the previous tutorial
./waxsystermes.fa
>SRR9968562_waxsystermes_virus_microassembly_translated
PIWDRVLEPLMRASPGIGRYMLTDVSPVGLLRVFKEKVDTTPHMPPEGMEDFKKASKEVE
KTLPTTLRELSWDEVKEMIRNDAAVGDPRWKTALEAKESEEFWREVQAEDLNHRNGVCLR
GVFHTMAKREKKEKNKWGQKTSRMIAYYDLIERACEMRTLGALNADHWAGEENTPEGVSG
IPQHLYGEKALNRLKMNRMTGETTEGQVFQGDIAGWDTRVSEYELQNEQRICEERAESED
HRRKIRTIYECYRSPIIRVQDADGNLMWLHGRGQRMSGTIVTYAMNTITNAIIQQAVSKD
LGNTYGRENRLISGDDCLVLYDTQHPEETLVAAFAKYGKVLKFEPGEPTWSKNIENTWFC
SHTYSRVKVGNDIRIMLDRSEIEILGKARIVLGGYKTGEVEQAMAKGYANYLLLTFPQRR
NVRLAANMVRAIVPRGLLPMGRAKDPWWREQPWMSTNNMIQAFNQIWEGWPPISSMKDIK
YVGRAREQMLDST
You can confirm your input sequences contain the relevant RdRP subsequence by running palmscan, a tool for identifying RdRP motif A, B, and C (palmprints).
./palmscan -search_pp waxystermes.fa \
-rdrp -all \
-ppout waxystermes.ps.fa \
-report waxystermes.ps.txt
Which we can see contains a complete palmprint sequence:
waxsystermes.ps.txt
>SRR9968562_waxsystermes_virus_microassembly
A:209-220(11.8) B:277-290(19.3) C:312-319(14.3)
FQGDIAGWDTRV <56> SGTIVTYAMNTITN <21> ISGDDCLV [111]
| |.+.||++| || .||. ||||| .|||||||
lenDyskFDksq SGdanTslGNTltn vsGDDsvv
Score 55.4, high-confidence-RdRP: high-PSSM-score.reward-DDGGDD.good-segment-length.
waxsystermes.ps.fa
>SRR9968562_waxsystermes_virus_microassembly
FQGDIAGWDTRVSEYELQNEQRICEERAESEDHRRKIRTIYECYRSPIIRVQDADGNLMW
LHGRGQRMSGTIVTYAMNTITNAIIQQAVSKDLGNTYGRENRLISGDDCLV
Create a diamond database from the palmDB sequences. There are two choices here: all unique.fa sequences or the representative species-like operational taxonomic units (sOTU) in otu_centroids.fa. We will use the latter here.
# Copy sOTU sequences from palmdb
cp palmdb/2021-03-14/otu_centroids.fa ./
# Create diamond database
diamond makedb --in otu_centroids.fa -d palmdb_otu
We will use diamond with --ultra-sensitive, -k0 report all hits, and -f to explicetly specify output.
INPUT='waxsystermes.fa'
OUTPUT='waxsystermes_palmdb_otu.out'
DB='palmdb_otu.dmnd'
diamond blastp \
-q $INPUT \
-d $DB \
--masking 0 \
--ultra-sensitive -k0 \
-f 6 qseqid qstart qend qlen \
sseqid sstart send slen \
pident evalue cigar \
full_sseq \
> $OUTPUT
Which generated the output file: waxsystermes_palmdb_otu.out
There are 229 unique palmprint sequences ranging from 100% to 29.7% identity. For example, line 3:
SRR9968562_waxsystermes_virus_microassembly 210 319 493 u5157 2 115 115 44.7 5.02e-22 57M1D34M3D19M IQDDTAGWDTRLHDDVLECEQSFLCDFAESEEHIKHILRIYKNYRNPMIKLTDDSGTRDLILIGKGQRCSGTVVTYSMNTITNTVVQMMRMQEVLELSNEECLHKMMVSGDDCLL
Can be read as:
query name: SRR9968562_waxsystermes_virus_microassembly
query_start_position: 210
query_end_position: 319
query_total_length: 493
target_name: u5157
target_start_position: 2
target_end_position: 115
target_total_length: 115
percent_identity: 44.7
expectance_value: 5.02e-22
CIGAR_string: 57M1D34M3D19M
target_sequence: IQDDTAGWDTRLHDDVLECEQSFLCDFAESEEHIKH
ILRIYKNYRNPMIKLTDDSGTRDLILIGKGQRCSGT
VVTYSMNTITNTVVQMMRMQEVLELSNEECLHKMMV
SGDDCLL
From the Waxystermes Virus sequence, the sub-sequence 210-319 (corresponding to the palmprint), matches palmprint u5157 at 44.7% identity.
We can blastp this sequence and see it is 100% match to Tamana Bat Virus. What about the other 227 sequences?
To make the tutorial tractable, we will limit the results to palmprints sharing at least 40% identity and 50% query coverage with the original target sequence, this leaves 22 sequences in waxystermes_palmdb_otu_40.out.
Now modify the diamond output file into fasta format.
cut -f5,9,12 waxsystermes_palmdb_otu_40.out \
| tr '\t' '_' \
| sed 's/^/>/g' \
| sed 's/\(.*\)_/\1\n/g' - \
> waxsystermes_palmdb_otu_40.fa
cat waxystermes_palmdb_otu_40.fa
>u128522_100
FQGDIAGWDTRVSEYELQNEQRICEERAESEDHRRKIRTIYECYRSPIIRVQDADGNLMWLHGRGQRMSGTIVTYAMNTITNAIIQQAVSKDLGNTYGRENRLISGDDCLV
>u18016_61.3
FQGDISGWDTRVSEYELEWEQRTLVERAQTEGHKRAIMTQYECYRNPIIKMPQQGGREVWLSGRGQRMSGTNVTYYCNTLTNAVLQEAVFTDLFGISEVARKRRMISGDDCCC
>u5157_44.7
IQDDTAGWDTRLHDDVLECEQSFLCDFAESEEHIKHILRIYKNYRNPMIKLTDDSGTRDLILIGKGQRCSGTVVTYSMNTITNTVVQMMRMQEVLELSNEECLHKMMVSGDDCLL
>u27451_41.1
FADDVAGWDTRISTEDLEDEESMTNYIKDEYHKRLIQSVYKLMYKTIVALFPRDHEGRTVMDVVVRGDQRGSGQVVTYALNTITNAKVQLCRTLETEGYYKLDQVKYIETWLRSNAGNXLSQMVVAGDDVVV
...
Generate the multiple sequence alignment with muscle:
muscle -in waxsystermes_palmdb_otu_40.fa -out waxsystermes_palmdb_otu_40.msa.fa
Visualize in with your favorite msa-viewer (Jalview) and make a simple neighbour-joining tree. You can see here the clean alignment of motif A, B and C within the palmprints, with perfect conservation of the catalytic residues making up the "supermotif" (D....D SG GDD). This is a good time to check for anomolies, or alignments/sequences which stand out.
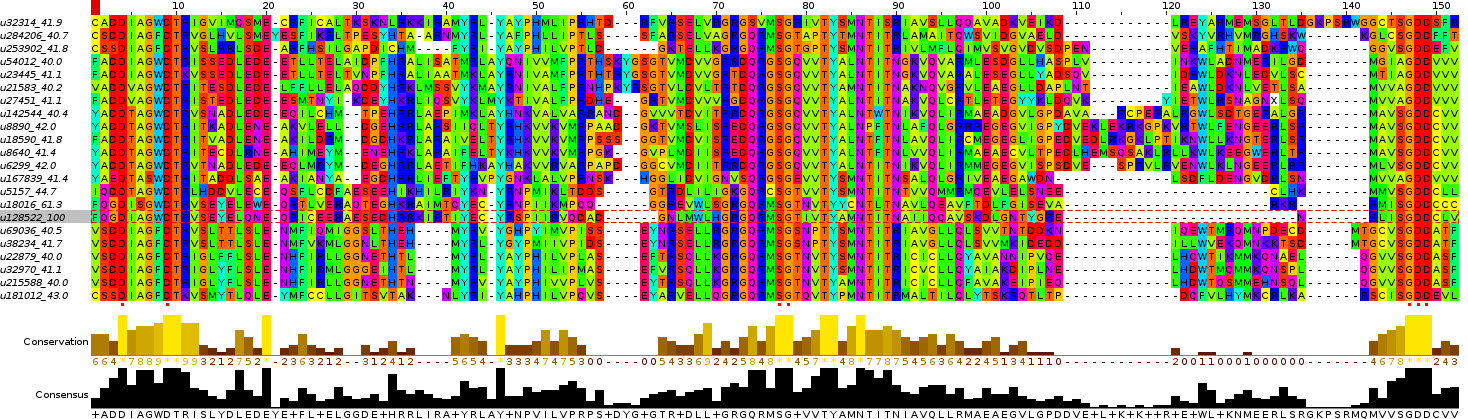

Here we see u32314 is the outgroup, which by blastp corresponds to Soybean Thrips Virus 1. This virus is currently "unclassified", so we will step to the next outgroup.
>u32314_41.9_unclassified
CADDIAGWDTRIGVIMQSMECRFICALTKSKNLRKKIRAMYRLYAYPHMLIPRHTDRFVR
SELVRGRGSVMSGRIVTYSMNTISRIAVSLLQQAVADKVEIKDLREYARMEMSGLTLDGK
PSRWGGCTSGDDSFR
The u284206 sequence does not contain a known match and shares 51.5% identity with Arachnidan jingmen-related virus (AJV), a flavivirus, thus at this point we're likely in the vicinity of Flaviviruses.
>u284206_40.7_flavi-like
CSDDIAGFDTRVGLHVLSMEYESFIKRLTPESYHTAARNMYRLYAFPHLLIPTLSSFARS
ELVAGRGQRMSGTAPTYTMNTITRLAMAITQWSVIDGVAELDVSKYVRHVMRGHSKWKGL
CSGDDFFT
We can approximate the known/novel viruses based on the origin of the sequence, roughly it was in GenBank (known) or it is from Serratus (novel).
# Copy source accessions from palmdb
cp palmdb/2021-03-14/acc_u.tsv ./
# Create a simple list of the unique identifers
# add "$" to end of line for grep
cut -f5 waxsystermes_palmdb_otu_40.out \
| sed 's/$/$/g' - \
> waxsystermes_palmdb_otu_40.list
# Find all unique sequences
grep -f waxsystermes_palmdb_otu_40.list acc_u.tsv \
| sort -u -k2,2 - \
| sed 's/|/\t/g' - \
| sort -k1,1 - \
> waxsystermes_palmdb_otu_40.sources
where waxsystermes_palmdb_otu_40.sources
gbnt AY632541 u8640
gbnt KX879625 u21583
gbnt MG599986 u18016
gbprot AAM14417 u5157
gbprot ABR19636 u8890
gbprot ALL52898 u22879
gbprot BCF79950 u23445
nr AAC58762.1 u6299
nr AIW60889.1 u27451
nr QPZ88370.1 u32970
nr QPZ88376.1 u32314
nr QPZ88422.1 u38234
nr YP_009351820.1 u18590
serratus v110633 u69036
serratus v24878 u181012
serratus v57722 u284206
serratus v69588 u54012
serratus NA u215588
serratus NA u128522
serratus NA u253902
serratus NA u167839
serratus NA u142544
Noting that 5 sequences are listed here with source NA, u215588, u128522, u253902, u167839, and u142544 were not in the source list, (they are serratus derived, this is a minor bug with some Serratus sequences missing).
That's it! You've used the Serratus and palmDB to start with an initial virus and expand the in the viscinity of those viruses.
Depending on your research question, some key next steps will be
- Search each sequence against
nrdatabase withDIAMONDorBLASTP(not shown) - Cross-reference each sequence with the available "microassembly" sequences to identify which libraries these viruses have been identified in. ( See: Tutorial C)
- Ribovirus classification by palmprints (preprint)
- PALMdb repository
- Tutorial: Running DIAMOND nr search
- Tutorial A: Serratus.io Lookup
- Tutorial C: RdRP microassembly sequence-search