-
Notifications
You must be signed in to change notification settings - Fork 20
Hadoop
Dénes Harmath edited this page May 14, 2015
·
6 revisions
- http://www.michael-noll.com/tutorials/running-hadoop-on-ubuntu-linux-single-node-cluster/
- http://www.michael-noll.com/tutorials/running-hadoop-on-ubuntu-linux-multi-node-cluster/
A common exception is the following:
could only be replicated to 0 nodes, instead of ...
The documentation, http://wiki.apache.org/hadoop/CouldOnlyBeReplicatedTo says:
This is not a problem in Hadoop, it is a problem in your cluster that you are going to have to fix on your own. Sorry.
It's possible that the logs generated at the initialization contain this exception, but Hadoop/HDFS will work fine. The super hard reset of Hadoop looks like the following:
/usr/local/hadoop/bin/stop-all.sh
# delete the content of the HDFS directory on all nodes, the `4s-ssh-all` script comes with 4store
4s-ssh-all "rm -rf $hadoop_dir/tmp/*"
/usr/local/hadoop/bin/hadoop namenode -format -force
/usr/local/hadoop/bin/start-all.shwait,
/usr/local/hadoop/bin/hadoop dfs -copyFromLocal local-filename hdfs-filename
/usr/local/hadoop/bin/hadoop dfs -ls- http://blog.madhukaraphatak.com/running-scala-programs-on-yarn/
- http://blog.cloudera.com/blog/2012/02/mapreduce-2-0-in-hadoop-0-23/
- http://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/WritingYarnApplications.html
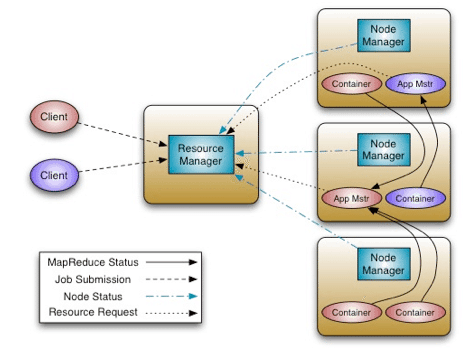
- http://hortonworks.com/wp-content/uploads/2012/08/YARNArch.png
- https://spring.io/guides/gs/yarn-basic/
{kind=link}