Releases: huggingface/transformers
v4.43.0: Llama 3.1, Chameleon, ZoeDepth, Hiera
Llama
The Llama 3.1 models are released by Meta and come in three flavours: 8B, 70B, and 405B.
To get an overview of Llama 3.1, please visit the Hugging Face announcement blog post.
We release a repository of llama recipes to showcase usage for inference, total and partial fine-tuning of the different variants.

Chameleon
The Chameleon model was proposed in Chameleon: Mixed-Modal Early-Fusion Foundation Models by META AI Chameleon Team. Chameleon is a Vision-Language Model that use vector quantization to tokenize images which enables the model to generate multimodal output. The model takes images and texts as input, including an interleaved format, and generates textual response.
- Chameleon: add model by @zucchini-nlp in #31534
ZoeDepth
The ZoeDepth model was proposed in ZoeDepth: Zero-shot Transfer by Combining Relative and Metric Depth by Shariq Farooq Bhat, Reiner Birkl, Diana Wofk, Peter Wonka, Matthias Müller. ZoeDepth extends the DPT framework for metric (also called absolute) depth estimation. ZoeDepth is pre-trained on 12 datasets using relative depth and fine-tuned on two domains (NYU and KITTI) using metric depth. A lightweight head is used with a novel bin adjustment design called metric bins module for each domain. During inference, each input image is automatically routed to the appropriate head using a latent classifier.
- Add ZoeDepth by @NielsRogge in #30136
Hiera
Hiera was proposed in Hiera: A Hierarchical Vision Transformer without the Bells-and-Whistles by Chaitanya Ryali, Yuan-Ting Hu, Daniel Bolya, Chen Wei, Haoqi Fan, Po-Yao Huang, Vaibhav Aggarwal, Arkabandhu Chowdhury, Omid Poursaeed, Judy Hoffman, Jitendra Malik, Yanghao Li, Christoph Feichtenhofer
The paper introduces “Hiera,” a hierarchical Vision Transformer that simplifies the architecture of modern hierarchical vision transformers by removing unnecessary components without compromising on accuracy or efficiency. Unlike traditional transformers that add complex vision-specific components to improve supervised classification performance, Hiera demonstrates that such additions, often termed “bells-and-whistles,” are not essential for high accuracy. By leveraging a strong visual pretext task (MAE) for pretraining, Hiera retains simplicity and achieves superior accuracy and speed both in inference and training across various image and video recognition tasks. The approach suggests that spatial biases required for vision tasks can be effectively learned through proper pretraining, eliminating the need for added architectural complexity.
- Adding hiera by @Namangarg110 in #30356
Agents
Our ReactAgent has a specific way to return its final output: it calls the tool final_answer, added to the user-defined toolbox upon agent initialization, with the answer as the tool argument. We found that even for a one-shot agent like CodeAgent, using a specific final_answer tools helps the llm_engine find what to return: so we generalized the final_answer tool for all agents.
- Adds final answer tool for all agents by @aymeric-roucher in #31703
Now if your code-based agent (like ReactCodeAgent) defines a function at step 1, it will remember the function definition indefinitely. This means your agent can create its own tools for later re-use!
- Code agent: allow function persistence between steps by @aymeric-roucher in #31769
This is a transformative PR: it allows the agent to regularly run a specific step for planning its actions in advance. This gets activated if you set an int for planning_interval upon agent initialization. At step 0, a first plan will be done. At later steps (like steps 3, 6, 9 if you set planning_interval=3 ), this plan will be updated by the agent depending on the history of previous steps. More detail soon!
- Agents planning by @aymeric-roucher in #31702
Notable changes to the codebase
A significant RoPE refactor was done to make it model agnostic and more easily adaptable to any architecture.
It is only applied to Llama for now but will be applied to all models using RoPE over the coming days.
Breaking changes
TextGenerationPipeline and tokenizer kwargs
🚨🚨 This PR changes the code to rely on the tokenizer's defaults when these flags are unset. This means some models using TextGenerationPipeline previously did not add a <bos> by default, which (negatively) impacted their performance. In practice, this is a breaking change.
Example of a script changed as a result of this PR:
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
import torch
tokenizer = AutoTokenizer.from_pretrained("google/gemma-2-9b-it")
model = AutoModelForCausalLM.from_pretrained("google/gemma-2-9b-it", torch_dtype=torch.bfloat16, device_map="auto")
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
print(pipe("Foo bar"))Bugfixes and improvements
- Fix post gemma merge by @ArthurZucker in #31660
- Fix float out of range in owlvit and owlv2 when using FP16 or lower precision by @aliencaocao in #31657
- [docs] Llama3 by @stevhliu in #31662
- [HybridCache] Fix
get_seq_lengthmethod by @sanchit-gandhi in #31661 - don't zero out the attention_mask when using sliding window with flash attention by @winglian in #31670
- Fix Gemma2 4d attention mask by @hiyouga in #31674
- Fix return_dict in encodec by @jla524 in #31646
- add gather_use_object arguments by @SangbumChoi in #31514
- Gemma capping is a must for big models by @ArthurZucker in #31698
- Add French version of run scripts tutorial by @jadechoghari in #31483
- dependencies:
keras-nlp<0.14pin by @gante in #31684 - remove incorrect urls pointing to the llava repository by @BiliBraker in #31107
- Move some test files (
tets/test_xxx_utils.py) totests/utilsby @ydshieh in #31730 - Fix mistral ONNX export by @fxmarty in #31696
- [whisper] static kv cache by @sanchit-gandhi in #31166
- Make tool JSON schemas consistent by @Rocketknight1 in #31756
- Fix documentation for Gemma2. by @jbornschein in #31682
- fix assisted decoding by @jiqing-feng in #31401
- Requires for torch.tensor before casting by @echarlaix in #31755
- handle (processor_class, None) returned by ModelPatterns by @molbap in #31753
- Gemma 2: Update slow tests by @gante in #31759
- Add ignore_errors=True to trainer.py rmtree in _inner_training_loop by @njbrake in #31668
- [fix bug] logits's shape different from label's shape in preprocess_logits_for_metrics by @wiserxin in #31447
- Fix RT-DETR cache for generate_anchors by @qubvel in #31671
- Fix RT-DETR weights initialization by @qubvel in #31724
pytest_num_workers=4for some CircleCI jobs by @ydshieh in #31764- Fix Gemma2 types by @hiyouga in #31779
- Add torch_empty_cache_steps to TrainingArguments by @aliencaocao in #31546
- Fix ClapProcessor to merge feature_extractor output into the returned BatchEncoding by @mxkopy in #31767
- Fix serialization for offloaded model by @SunMarc in #31727
- Make tensor device correct when ACCELERATE_TORCH_DEVICE is defined by @kiszk in #31751
- Exclude torch.compile time from metrics computation by @zxd1997066 in #31443
- Update CometCallback to allow reusing of the running experiment by @Lothiraldan in #31366
- Fix gemma tests by @ydshieh in #31794
- Add training support for SigLIP by @aliencaocao in #31495
- Repeating an important warning in the chat template docs by @Rocketknight1 in #31796
- Allow FP16 or other precision inference for Pipelines by @aliencaocao in #31342
- Fix galore lr display with schedulers by @vasqu in #31710
- Fix Wav2Vec2 Fairseq conversion (weight norm state dict keys) by @gau-nernst in #31714
- Depth Anything: update conversion script for V2 by @pcuenca in #31522
- Fix Seq2SeqTrainer crash when BatchEncoding data is None by @iohub in #31418
- Bump certifi from 2023.7.22 to 2024.7.4 in /examples/research_projects/decision_transformer by @dependabot[bot] in #31813
- Add FA2 and
sdpasupport for SigLIP by @qubvel in #31499 - Bump transformers from 4.26.1 to 4.38.0 in /examples/tensorflow/language-modeling-tpu by @dependabot[bot] in #31837
- Bump certifi from 2023.7.22 to 2024.7.4 in /examples/research_projects/lxmert by @dependabot[bot] in #31838
- Fix typos by @omahs in #31819
- transformers.fx.symbolic_trace supports inputs_embeds by @fxmarty in #31574
- Avoid failure
TFBlipModelTest::test_pipeline_image_to_textby @ydshieh in #31827 - Fix incorrect accelerator device handling for MPS in
TrainingArgumentsby @andstor in #31812 - Mamba & RecurrentGemma: enable strict signature by @gante in #31549
- Deprecate
vocab_sizein other two VLMs by @zucchini-nlp in #31681 - FX symbolic_trace: do not test decoder_inputs_embeds by @fxmarty in #31840
- [Grounding DINO] Add processor to auto mapping by @NielsRogge in #31845
- chore: remove duplicate words by @hattizai in #31853
- save_pretrained: use tqdm when saving checkpoint shards from offloaded params by @kallewoof in #31856
- Test loading generation config with safetensor weights by @gante in #31550
- docs: typo in tf qa example by @chen-keinan in #31864
- Generate: Add new decoding strategy "DoLa" in
.generate()by @voidism in #29619 - Fix
_init_weightsforResNetPreTrainedModelby @ydshieh in #31851 - Update depth estimation task guide by @merveenoyan in #31860
- Bump zip...
Contributors
Assets 2
Patch release v4.42.4
Mostly gemma2 support FA2 softcapping!
but also fix the sliding window for long context and other typos.
- [Gemma2] Support FA2 softcapping (#31887) by @ArthurZucker
- [ConvertSlow] make sure the order is preserved for addedtokens (#31902) by @ArthurZucker
- Fixes to alternating SWA layers in Gemma2 (#31775) by @turboderp
- Requires for torch.tensor before casting (#31755) by @echarlaix
Was off last week could not get this out, thanks all for your patience 🥳
Contributors
Assets 2
Patch release v4.42.3
Make sure we have attention softcapping for "eager" GEMMA2 model
After experimenting, we noticed that for the 27b model mostly, softcapping is a must. So adding it back (it should have been there, but an error on my side made it disappear) sorry all! 😭
- Gemma capping is a must for big models (#31698)
Patch release v4.42.2
Contributors
Assets 2
v4.42.1: Patch release
Patch release for commit:
- [HybridCache] Fix get_seq_length method (#31661)
v4.42.0: Gemma 2, RTDETR, InstructBLIP, LLAVa Next, New Model Adder
New model additions
Gemma-2
The Gemma2 model was proposed in Gemma2: Open Models Based on Gemini Technology and Research by Gemma2 Team, Google.
Gemma2 models are trained on 6T tokens, and released with 2 versions, 2b and 7b.
The abstract from the paper is the following:
This work introduces Gemma2, a new family of open language models demonstrating strong performance across academic benchmarks for language understanding, reasoning, and safety. We release two sizes of models (2 billion and 7 billion parameters), and provide both pretrained and fine-tuned checkpoints. Gemma2 outperforms similarly sized open models on 11 out of 18 text-based tasks, and we present comprehensive evaluations of safety and responsibility aspects of the models, alongside a detailed description of our model development. We believe the responsible release of LLMs is critical for improving the safety of frontier models, and for enabling the next wave of LLM innovations

- Add gemma 2 by @ArthurZucker in #31659
RTDETR
The RT-DETR model was proposed in DETRs Beat YOLOs on Real-time Object Detection by Wenyu Lv, Yian Zhao, Shangliang Xu, Jinman Wei, Guanzhong Wang, Cheng Cui, Yuning Du, Qingqing Dang, Yi Liu.
RT-DETR is an object detection model that stands for “Real-Time DEtection Transformer.” This model is designed to perform object detection tasks with a focus on achieving real-time performance while maintaining high accuracy. Leveraging the transformer architecture, which has gained significant popularity in various fields of deep learning, RT-DETR processes images to identify and locate multiple objects within them.

- New model support RTDETR by @SangbumChoi in #29077
InstructBlip
The InstructBLIP model was proposed in InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning by Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale Fung, Steven Hoi. InstructBLIP leverages the BLIP-2 architecture for visual instruction tuning.
InstructBLIP uses the same architecture as BLIP-2 with a tiny but important difference: it also feeds the text prompt (instruction) to the Q-Former.

- Add video modality for InstrucBLIP by @zucchini-nlp in #30182
LlaVa NeXT Video
The LLaVa-NeXT-Video model was proposed in LLaVA-NeXT: A Strong Zero-shot Video Understanding Model by Yuanhan Zhang, Bo Li, Haotian Liu, Yong Jae Lee, Liangke Gui, Di Fu, Jiashi Feng, Ziwei Liu, Chunyuan Li. LLaVa-NeXT-Video improves upon LLaVa-NeXT by fine-tuning on a mix if video and image dataset thus increasing the model’s performance on videos.
LLaVA-NeXT surprisingly has strong performance in understanding video content in zero-shot fashion with the AnyRes technique that it uses. The AnyRes technique naturally represents a high-resolution image into multiple images. This technique is naturally generalizable to represent videos because videos can be considered as a set of frames (similar to a set of images in LLaVa-NeXT). The current version of LLaVA-NeXT makes use of AnyRes and trains with supervised fine-tuning (SFT) on top of LLaVA-Next on video data to achieves better video understanding capabilities.The model is a current SOTA among open-source models on VideoMME bench.
- Add LLaVa NeXT Video by @zucchini-nlp in #31252
New model adder
A very significant change makes its way within the transformers codebase, introducing a new way to add models to transformers. We recommend reading the description of the PR below, but here is the gist of it:
The diff_converter tool is here to replace our old Copied from statements, while keeping our core transformers philosophy:
- single model single file
- explicit code
- standardization of modeling code
- readable and educative code
- simple code
- least amount of modularity
This additionally unlocks the ability to very quickly see the differences between new architectures that get developed. While many architectures are similar, the "single model, single file" policy can obfuscate the changes. With this diff converter, we want to make the changes between architectures very explicit.
- Diff converter v2 by @ArthurZucker in #30868
Tool-use and RAG model support
We've made major updates to our support for tool-use and RAG models. We can now automatically generate JSON schema descriptions for Python functions which are suitable for passing to tool models, and we've defined a standard API for tool models which should allow the same tool inputs to be used with many different models. Models will need updates to their chat templates to support the new API, and we're targeting the Nous-Hermes, Command-R and Mistral/Mixtral model families for support in the very near future. Please see the updated chat template docs for more information.
If you are the owner of a model that supports tool use, but you're not sure how to update its chat template to support the new API, feel free to reach out to us for assistance with the update, for example on the Hugging Face Discord server. Ping Matt and yell key phrases like "chat templates" and "Jinja" and your issue will probably get resolved.
- Chat Template support for function calling and RAG by @Rocketknight1 in #30621
GGUF support
We further the support of GGUF files to offer fine-tuning within the python/HF ecosystem, before converting them back to the GGUF/GGML/llama.cpp libraries.
- Add Qwen2 GGUF loading support by @Isotr0py in #31175
- GGUF: Fix llama 3 GGUF by @younesbelkada in #31358
- Fix llama gguf converter by @SunMarc in #31575
Trainer improvements
A new optimizer is added in the Trainer.
- FEAT / Trainer: LOMO optimizer support by @younesbelkada in #30178
Quantization improvements
Several improvements are done related to quantization: a new cache (the quantized KV cache) is added, offering the ability to convert the cache of generative models, further reducing the memory requirements.
Additionally, the documentation related to quantization is entirely redone with the aim of helping users choose which is the best quantization method.
- Quantized KV Cache by @zucchini-nlp in #30483
- Docs / Quantization: refactor quantization documentation by @younesbelkada in #30942
Examples
New instance segmentation examples are added by @qubvel
Notable improvements
As a notable improvement to the HF vision models that leverage backbones, we enable leveraging HF pretrained model weights as backbones, with the following API:
from transformers import MaskFormerConfig, MaskFormerForInstanceSegmentation
config = MaskFormerConfig(backbone="microsoft/resnet-50", use_pretrained_backbone=True)
model = MaskFormerForInstanceSegmentation(config)- Enable HF pretrained backbones by @amyeroberts in #31145
Additionally, we thank @Cyrilvallez for diving into our generate method and greatly reducing the memory requirements.
- Reduce by 2 the memory requirement in
generate()🔥🔥🔥 by @Cyrilvallez in #30536
Breaking changes
Remove ConversationalPipeline and Conversation object
Both the ConversationalPipeline and the Conversation object have been deprecated for a while, and are due for removal in 4.42, which is the upcoming version.
The TextGenerationPipeline is recommended for this use-case, and now accepts inputs in the form of the OpenAI API.
- 🚨 Remove ConversationalPipeline and Conversation object by @Rocketknight1 in #31165
Remove an accidental duplicate softmax application in FLAVA's attention
Removes duplicate softmax application in FLAVA attention. Likely to have a small change on the outputs but flagging with 🚨 as it will change a bit.
- 🚨 FLAVA: Remove double softmax by @amyeroberts in #31322
Idefics2's ignore_index attribute of the loss is updated to -100
- 🚨 [Idefics2] Update ignore index by @NielsRogge in #30898
out_indices from timm being updated
Recent updates to timm changed the type of the attribute model.feature_info.out_indices. Previously, out_indices would reflect the input type of out_indices on the create_model call i.e. either tuple or list. Now, this value is always a tuple.
As list are more useful and consistent for us -- we cannot save tuples in configs, they must be converted to lists first -- we instead choose to cast out_indices to always be a list.
This has the possibility of being a slight breaking change if users are creating models and relying on out_indices on being a tuple. As this property only happens when a new model is created, and not if it's saved and reloaded (because of the config), then I think this has a low chance of having much of an impact.
- 🚨 out_indices always a list by @amyeroberts in #30941
datasets referenced in the quantization config get updated to remove referen...
Contributors
Assets 2
Release v4.41.2
Release v4.41.2
Mostly fixing some stuff related to trust_remote_code=True and from_pretrained
The local_file_only was having a hard time when a .safetensors file did not exist. This is not expected and instead of trying to convert, we should just fallback to loading the .bin files.
- Do not trigger autoconversion if local_files_only #31004 from @Wauplin fixes this!
- Paligemma: Fix devices and dtype assignments (#31008) by @molbap
- Redirect transformers_agents doc to agents (#31054) @aymeric-roucher
- Fix from_pretrained in offline mode when model is preloaded in cache (#31010) by @oOraph
- Fix faulty rstrip in module loading (#31108) @Rocketknight1
Contributors
Assets 2
Release v4.41.1 Fix PaliGemma finetuning, and some small bugs
Release v4.41.1
Fix PaliGemma finetuning:
The causal mask and label creation was causing label leaks when training. Kudos to @probicheaux for finding and reporting!
- a755745 : PaliGemma - fix processor with no input text (#30916) @hiyouga
- a25f7d3 : Paligemma causal attention mask (#30967) @molbap and @probicheaux
Other fixes:
- bb48e92: tokenizer_class = "AutoTokenizer" Llava Family (#30912)
- 1d568df : legacy to init the slow tokenizer when converting from slow was wrong (#30972)
- b1065aa : Generation: get special tokens from model config (#30899) @zucchini-nlp
Reverted 4ab7a28
Contributors
Assets 2
v4.41.0: Phi3, JetMoE, PaliGemma, VideoLlava, Falcon2, FalconVLM & GGUF support
New models
Phi3
The Phi-3 model was proposed in Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone by Microsoft.
TLDR; Phi-3 introduces new ROPE scaling methods, which seems to scale fairly well! A 3b and a
Phi-3-mini is available in two context-length variants—4K and 128K tokens. It is the first model in its class to support a context window of up to 128K tokens, with little impact on quality.

JetMoE
JetMoe-8B is an 8B Mixture-of-Experts (MoE) language model developed by Yikang Shen and MyShell. JetMoe project aims to provide a LLaMA2-level performance and efficient language model with a limited budget. To achieve this goal, JetMoe uses a sparsely activated architecture inspired by the ModuleFormer. Each JetMoe block consists of two MoE layers: Mixture of Attention Heads and Mixture of MLP Experts. Given the input tokens, it activates a subset of its experts to process them. This sparse activation schema enables JetMoe to achieve much better training throughput than similar size dense models. The training throughput of JetMoe-8B is around 100B tokens per day on a cluster of 96 H100 GPUs with a straightforward 3-way pipeline parallelism strategy.

- Add JetMoE model by @yikangshen in #30005
PaliGemma
PaliGemma is a lightweight open vision-language model (VLM) inspired by PaLI-3, and based on open components like the SigLIP vision model and the Gemma language model. PaliGemma takes both images and text as inputs and can answer questions about images with detail and context, meaning that PaliGemma can perform deeper analysis of images and provide useful insights, such as captioning for images and short videos, object detection, and reading text embedded within images.
More than 120 checkpoints are released see the collection here !

VideoLlava
Video-LLaVA exhibits remarkable interactive capabilities between images and videos, despite the absence of image-video pairs in the dataset.
💡 Simple baseline, learning united visual representation by alignment before projection
With the binding of unified visual representations to the language feature space, we enable an LLM to perform visual reasoning capabilities on both images and videos simultaneously.
🔥 High performance, complementary learning with video and image
Extensive experiments demonstrate the complementarity of modalities, showcasing significant superiority when compared to models specifically designed for either images or videos.

- Add Video Llava by @zucchini-nlp in #29733
Falcon 2 and FalconVLM:
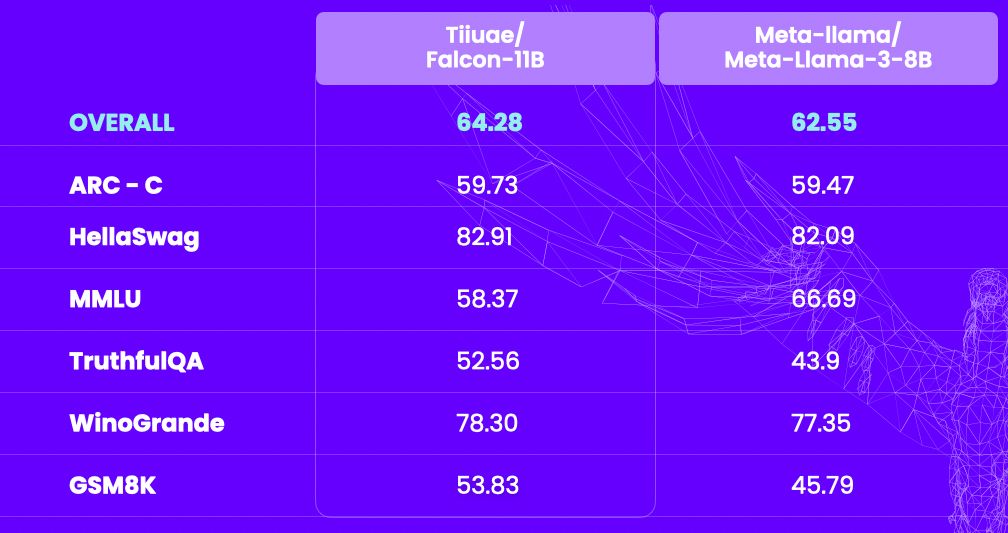
Two new models from TII-UAE! They published a blog-post with more details! Falcon2 introduces parallel mlp, and falcon VLM uses the Llava framework
- Support for Falcon2-11B by @Nilabhra in #30771
- Support arbitrary processor by @ArthurZucker in #30875
GGUF from_pretrained support

You can now load most of the GGUF quants directly with transformers' from_pretrained to convert it to a classic pytorch model. The API is simple:
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "TheBloke/TinyLlama-1.1B-Chat-v1.0-GGUF"
filename = "tinyllama-1.1b-chat-v1.0.Q6_K.gguf"
tokenizer = AutoTokenizer.from_pretrained(model_id, gguf_file=filename)
model = AutoModelForCausalLM.from_pretrained(model_id, gguf_file=filename)We plan more closer integrations with llama.cpp / GGML ecosystem in the future, see: #27712 for more details
- Loading GGUF files support by @LysandreJik in #30391
Transformers Agents 2.0
v4.41.0 introduces a significant refactor of the Agents framework.
With this release, we allow you to build state-of-the-art agent systems, including the React Code Agent that writes its actions as code in ReAct iterations, following the insights from Wang et al., 2024
Just install with pip install "transformers[agents]". Then you're good to go!
from transformers import ReactCodeAgent
agent = ReactCodeAgent(tools=[])
code = """
list=[0, 1, 2]
for i in range(4):
print(list(i))
"""
corrected_code = agent.run(
"I have some code that creates a bug: please debug it and return the final code",
code=code,
)Quantization
New quant methods
In this release we support new quantization methods: HQQ & EETQ contributed by the community. Read more about how to quantize any transformers model using HQQ & EETQ in the dedicated documentation section
- Add HQQ quantization support by @mobicham in #29637
- [FEAT]: EETQ quantizer support by @dtlzhuangz in #30262
dequantize API for bitsandbytes models
In case you want to dequantize models that have been loaded with bitsandbytes, this is now possible through the dequantize API (e.g. to merge adapter weights)
- FEAT / Bitsandbytes: Add
dequantizeAPI for bitsandbytes quantized models by @younesbelkada in #30806
API-wise, you can achieve that with the following:
from transformers import AutoModelForCausalLM, BitsAndBytesConfig, AutoTokenizer
model_id = "facebook/opt-125m"
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=BitsAndBytesConfig(load_in_4bit=True))
tokenizer = AutoTokenizer.from_pretrained(model_id)
model.dequantize()
text = tokenizer("Hello my name is", return_tensors="pt").to(0)
out = model.generate(**text)
print(tokenizer.decode(out[0]))Generation updates
- Add Watermarking LogitsProcessor and WatermarkDetector by @zucchini-nlp in #29676
- Cache: Static cache as a standalone object by @gante in #30476
- Generate: add
min_psampling by @gante in #30639 - Make
Gemmawork withtorch.compileby @ydshieh in #30775
SDPA support
- [
BERT] Add support for sdpa by @hackyon in #28802 - Add sdpa and fa2 the Wav2vec2 family. by @kamilakesbi in #30121
- add sdpa to ViT [follow up of #29325] by @hyenal in #30555
Improved Object Detection
Addition of fine-tuning script for object detection models
- Fix YOLOS image processor resizing by @qubvel in #30436
- Add examples for detection models finetuning by @qubvel in #30422
- Add installation of examples requirements in CI by @qubvel in #30708
- Update object detection guide by @qubvel in #30683
Interpolation of embeddings for vision models
Add interpolation of embeddings. This enables predictions from pretrained models on input images of sizes different than those the model was originally trained on. Simply pass interpolate_pos_embedding=True when calling the model.
Added for: BLIP, BLIP 2, InstructBLIP, SigLIP, ViViT
import requests
from PIL import Image
from transformers import Blip2Processor, Blip2ForConditionalGeneration
image = Image.open(requests.get("https://huggingface.co/hf-internal-testing/blip-test-image/resolve/main/demo.jpg", stream=True).raw)
processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2ForConditionalGeneration.from_pretrained(
"Salesforce/blip2-opt-2.7b",
torch_dtype=torch.float16
).to("cuda")
inputs = processor(images=image, size={"height": 500, "width": 500}, return_tensors="pt").to("cuda")
predictions = model(**inputs, interpolate_pos_encoding=True)
# Generated text: "a woman and dog on the beach"
generated_text = processor.batch_decode(predictions, skip_special_tokens=True)[0].strip()- Blip dynamic input resolution by @zafstojano in #30722
- Add dynamic resolution input/interpolate pos...
Contributors
Assets 2
v4.40.2
Fix torch fx for LLama model
Thanks @michaelbenayoun !