AE_1 #3
AE_1 #3
Commits on Dec 4, 2018
-
[MINOR][SQL] Combine the same codes in test cases
## What changes were proposed in this pull request? In the DDLSuit, there are four test cases have the same codes , writing a function can combine the same code. ## How was this patch tested? existing tests. Closes apache#23194 from CarolinePeng/Update_temp. Authored-by: 彭灿00244106 <00244106@zte.intra> Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
-
[SPARK-24423][FOLLOW-UP][SQL] Fix error example
## What changes were proposed in this pull request?  It will throw: ``` requirement failed: When reading JDBC data sources, users need to specify all or none for the following options: 'partitionColumn', 'lowerBound', 'upperBound', and 'numPartitions' ``` and ``` User-defined partition column subq.c1 not found in the JDBC relation ... ``` This PR fix this error example. ## How was this patch tested? manual tests Closes apache#23170 from wangyum/SPARK-24499. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[SPARK-26178][SQL] Use java.time API for parsing timestamps and dates…
… from CSV ## What changes were proposed in this pull request? In the PR, I propose to use **java.time API** for parsing timestamps and dates from CSV content with microseconds precision. The SQL config `spark.sql.legacy.timeParser.enabled` allow to switch back to previous behaviour with using `java.text.SimpleDateFormat`/`FastDateFormat` for parsing/generating timestamps/dates. ## How was this patch tested? It was tested by `UnivocityParserSuite`, `CsvExpressionsSuite`, `CsvFunctionsSuite` and `CsvSuite`. Closes apache#23150 from MaxGekk/time-parser. Lead-authored-by: Maxim Gekk <max.gekk@gmail.com> Co-authored-by: Maxim Gekk <maxim.gekk@databricks.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[SPARK-26233][SQL] CheckOverflow when encoding a decimal value
## What changes were proposed in this pull request? When we encode a Decimal from external source we don't check for overflow. That method is useful not only in order to enforce that we can represent the correct value in the specified range, but it also changes the underlying data to the right precision/scale. Since in our code generation we assume that a decimal has exactly the same precision and scale of its data type, missing to enforce it can lead to corrupted output/results when there are subsequent transformations. ## How was this patch tested? added UT Closes apache#23210 from mgaido91/SPARK-26233. Authored-by: Marco Gaido <marcogaido91@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
-
[SPARK-26119][CORE][WEBUI] Task summary table should contain only suc…
…cessful tasks' metrics ## What changes were proposed in this pull request? Task summary table in the stage page currently displays the summary of all the tasks. However, we should display the task summary of only successful tasks, to follow the behavior of previous versions of spark. ## How was this patch tested? Added UT. attached screenshot Before patch:   Closes apache#23088 from shahidki31/summaryMetrics. Authored-by: Shahid <shahidki31@gmail.com> Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
-
[SPARK-26094][CORE][STREAMING] createNonEcFile creates parent dirs.
## What changes were proposed in this pull request? We explicitly avoid files with hdfs erasure coding for the streaming WAL and for event logs, as hdfs EC does not support all relevant apis. However, the new builder api used has different semantics -- it does not create parent dirs, and it does not resolve relative paths. This updates createNonEcFile to have similar semantics to the old api. ## How was this patch tested? Ran tests with the WAL pointed at a non-existent dir, which failed before this change. Manually tested the new function with a relative path as well. Unit tests via jenkins. Closes apache#23092 from squito/SPARK-26094. Authored-by: Imran Rashid <irashid@cloudera.com> Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
{kind=link}
{kind=link}
{kind=link}
Commits on Dec 5, 2018
-
[SPARK-25829][SQL][FOLLOWUP] Refactor MapConcat in order to check pro…
…perly the limit size ## What changes were proposed in this pull request? The PR starts from the [comment](apache#23124 (comment)) in the main one and it aims at: - simplifying the code for `MapConcat`; - be more precise in checking the limit size. ## How was this patch tested? existing tests Closes apache#23217 from mgaido91/SPARK-25829_followup. Authored-by: Marco Gaido <marcogaido91@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
-
[SPARK-26252][PYTHON] Add support to run specific unittests and/or do…
…ctests in python/run-tests script ## What changes were proposed in this pull request? This PR proposes add a developer option, `--testnames`, to our testing script to allow run specific set of unittests and doctests. **1. Run unittests in the class** ```bash ./run-tests --testnames 'pyspark.sql.tests.test_arrow ArrowTests' ``` ``` Running PySpark tests. Output is in /.../spark/python/unit-tests.log Will test against the following Python executables: ['python2.7', 'pypy'] Will test the following Python tests: ['pyspark.sql.tests.test_arrow ArrowTests'] Starting test(python2.7): pyspark.sql.tests.test_arrow ArrowTests Starting test(pypy): pyspark.sql.tests.test_arrow ArrowTests Finished test(python2.7): pyspark.sql.tests.test_arrow ArrowTests (14s) Finished test(pypy): pyspark.sql.tests.test_arrow ArrowTests (14s) ... 22 tests were skipped Tests passed in 14 seconds Skipped tests in pyspark.sql.tests.test_arrow ArrowTests with pypy: test_createDataFrame_column_name_encoding (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.19.2 must be installed; however, it was not found.' test_createDataFrame_does_not_modify_input (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.19.2 must be installed; however, it was not found.' test_createDataFrame_fallback_disabled (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.19.2 must be installed; however, it was not found.' test_createDataFrame_fallback_enabled (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped ... ``` **2. Run single unittest in the class.** ```bash ./run-tests --testnames 'pyspark.sql.tests.test_arrow ArrowTests.test_null_conversion' ``` ``` Running PySpark tests. Output is in /.../spark/python/unit-tests.log Will test against the following Python executables: ['python2.7', 'pypy'] Will test the following Python tests: ['pyspark.sql.tests.test_arrow ArrowTests.test_null_conversion'] Starting test(pypy): pyspark.sql.tests.test_arrow ArrowTests.test_null_conversion Starting test(python2.7): pyspark.sql.tests.test_arrow ArrowTests.test_null_conversion Finished test(pypy): pyspark.sql.tests.test_arrow ArrowTests.test_null_conversion (0s) ... 1 tests were skipped Finished test(python2.7): pyspark.sql.tests.test_arrow ArrowTests.test_null_conversion (8s) Tests passed in 8 seconds Skipped tests in pyspark.sql.tests.test_arrow ArrowTests.test_null_conversion with pypy: test_null_conversion (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.19.2 must be installed; however, it was not found.' ``` **3. Run doctests in single PySpark module.** ```bash ./run-tests --testnames pyspark.sql.dataframe ``` ``` Running PySpark tests. Output is in /.../spark/python/unit-tests.log Will test against the following Python executables: ['python2.7', 'pypy'] Will test the following Python tests: ['pyspark.sql.dataframe'] Starting test(pypy): pyspark.sql.dataframe Starting test(python2.7): pyspark.sql.dataframe Finished test(python2.7): pyspark.sql.dataframe (47s) Finished test(pypy): pyspark.sql.dataframe (48s) Tests passed in 48 seconds ``` Of course, you can mix them: ```bash ./run-tests --testnames 'pyspark.sql.tests.test_arrow ArrowTests,pyspark.sql.dataframe' ``` ``` Running PySpark tests. Output is in /.../spark/python/unit-tests.log Will test against the following Python executables: ['python2.7', 'pypy'] Will test the following Python tests: ['pyspark.sql.tests.test_arrow ArrowTests', 'pyspark.sql.dataframe'] Starting test(pypy): pyspark.sql.dataframe Starting test(pypy): pyspark.sql.tests.test_arrow ArrowTests Starting test(python2.7): pyspark.sql.dataframe Starting test(python2.7): pyspark.sql.tests.test_arrow ArrowTests Finished test(pypy): pyspark.sql.tests.test_arrow ArrowTests (0s) ... 22 tests were skipped Finished test(python2.7): pyspark.sql.tests.test_arrow ArrowTests (18s) Finished test(python2.7): pyspark.sql.dataframe (50s) Finished test(pypy): pyspark.sql.dataframe (52s) Tests passed in 52 seconds Skipped tests in pyspark.sql.tests.test_arrow ArrowTests with pypy: test_createDataFrame_column_name_encoding (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.19.2 must be installed; however, it was not found.' test_createDataFrame_does_not_modify_input (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.19.2 must be installed; however, it was not found.' test_createDataFrame_fallback_disabled (pyspark.sql.tests.test_arrow.ArrowTests) ... skipped 'Pandas >= 0.19.2 must be installed; however, it was not found.' ``` and also you can use all other options (except `--modules`, which will be ignored) ```bash ./run-tests --testnames 'pyspark.sql.tests.test_arrow ArrowTests.test_null_conversion' --python-executables=python ``` ``` Running PySpark tests. Output is in /.../spark/python/unit-tests.log Will test against the following Python executables: ['python'] Will test the following Python tests: ['pyspark.sql.tests.test_arrow ArrowTests.test_null_conversion'] Starting test(python): pyspark.sql.tests.test_arrow ArrowTests.test_null_conversion Finished test(python): pyspark.sql.tests.test_arrow ArrowTests.test_null_conversion (12s) Tests passed in 12 seconds ``` See help below: ```bash ./run-tests --help ``` ``` Usage: run-tests [options] Options: ... Developer Options: --testnames=TESTNAMES A comma-separated list of specific modules, classes and functions of doctest or unittest to test. For example, 'pyspark.sql.foo' to run the module as unittests or doctests, 'pyspark.sql.tests FooTests' to run the specific class of unittests, 'pyspark.sql.tests FooTests.test_foo' to run the specific unittest in the class. '--modules' option is ignored if they are given. ``` I intentionally grouped it as a developer option to be more conservative. ## How was this patch tested? Manually tested. Negative tests were also done. ```bash ./run-tests --testnames 'pyspark.sql.tests.test_arrow ArrowTests.test_null_conversion1' --python-executables=python ``` ``` ... AttributeError: type object 'ArrowTests' has no attribute 'test_null_conversion1' ... ``` ```bash ./run-tests --testnames 'pyspark.sql.tests.test_arrow ArrowT' --python-executables=python ``` ``` ... AttributeError: 'module' object has no attribute 'ArrowT' ... ``` ```bash ./run-tests --testnames 'pyspark.sql.tests.test_ar' --python-executables=python ``` ``` ... /.../python2.7: No module named pyspark.sql.tests.test_ar ``` Closes apache#23203 from HyukjinKwon/SPARK-26252. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> -
[SPARK-26133][ML][FOLLOWUP] Fix doc for OneHotEncoder
## What changes were proposed in this pull request? This fixes doc of renamed OneHotEncoder in PySpark. ## How was this patch tested? N/A Closes apache#23230 from viirya/remove_one_hot_encoder_followup. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[SPARK-26271][FOLLOW-UP][SQL] remove unuse object SparkPlan
## What changes were proposed in this pull request? this code come from PR: apache#11190, but this code has never been used, only since PR: apache#14548, Let's continue fix it. thanks. ## How was this patch tested? N / A Closes apache#23227 from heary-cao/unuseSparkPlan. Authored-by: caoxuewen <cao.xuewen@zte.com.cn> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
-
[SPARK-26151][SQL][FOLLOWUP] Return partial results for bad CSV records
## What changes were proposed in this pull request? Updated SQL migration guide according to changes in apache#23120 Closes apache#23235 from MaxGekk/failuresafe-partial-result-followup. Lead-authored-by: Maxim Gekk <maxim.gekk@databricks.com> Co-authored-by: Maxim Gekk <max.gekk@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
Commits on Dec 6, 2018
-
[SPARK-26275][PYTHON][ML] Increases timeout for StreamingLogisticRegr…
…essionWithSGDTests.test_training_and_prediction test ## What changes were proposed in this pull request? Looks this test is flaky https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/99704/console https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/99569/console https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/99644/console https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/99548/console https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/99454/console https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/99609/console ``` ====================================================================== FAIL: test_training_and_prediction (pyspark.mllib.tests.test_streaming_algorithms.StreamingLogisticRegressionWithSGDTests) Test that the model improves on toy data with no. of batches ---------------------------------------------------------------------- Traceback (most recent call last): File "/home/jenkins/workspace/SparkPullRequestBuilder/python/pyspark/mllib/tests/test_streaming_algorithms.py", line 367, in test_training_and_prediction self._eventually(condition) File "/home/jenkins/workspace/SparkPullRequestBuilder/python/pyspark/mllib/tests/test_streaming_algorithms.py", line 78, in _eventually % (timeout, lastValue)) AssertionError: Test failed due to timeout after 30 sec, with last condition returning: Latest errors: 0.67, 0.71, 0.78, 0.7, 0.75, 0.74, 0.73, 0.69, 0.62, 0.71, 0.69, 0.75, 0.72, 0.77, 0.71, 0.74 ---------------------------------------------------------------------- Ran 13 tests in 185.051s FAILED (failures=1, skipped=1) ``` This looks happening after increasing the parallelism in Jenkins to speed up at apache#23111. I am able to reproduce this manually when the resource usage is heavy (with manual decrease of timeout). ## How was this patch tested? Manually tested by ``` cd python ./run-tests --testnames 'pyspark.mllib.tests.test_streaming_algorithms StreamingLogisticRegressionWithSGDTests.test_training_and_prediction' --python-executables=python ``` Closes apache#23236 from HyukjinKwon/SPARK-26275. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[SPARK-25274][PYTHON][SQL] In toPandas with Arrow send un-ordered rec…
…ord batches to improve performance ## What changes were proposed in this pull request? When executing `toPandas` with Arrow enabled, partitions that arrive in the JVM out-of-order must be buffered before they can be send to Python. This causes an excess of memory to be used in the driver JVM and increases the time it takes to complete because data must sit in the JVM waiting for preceding partitions to come in. This change sends un-ordered partitions to Python as soon as they arrive in the JVM, followed by a list of partition indices so that Python can assemble the data in the correct order. This way, data is not buffered at the JVM and there is no waiting on particular partitions so performance will be increased. Followup to apache#21546 ## How was this patch tested? Added new test with a large number of batches per partition, and test that forces a small delay in the first partition. These test that partitions are collected out-of-order and then are are put in the correct order in Python. ## Performance Tests - toPandas Tests run on a 4 node standalone cluster with 32 cores total, 14.04.1-Ubuntu and OpenJDK 8 measured wall clock time to execute `toPandas()` and took the average best time of 5 runs/5 loops each. Test code ```python df = spark.range(1 << 25, numPartitions=32).toDF("id").withColumn("x1", rand()).withColumn("x2", rand()).withColumn("x3", rand()).withColumn("x4", rand()) for i in range(5): start = time.time() _ = df.toPandas() elapsed = time.time() - start ``` Spark config ``` spark.driver.memory 5g spark.executor.memory 5g spark.driver.maxResultSize 2g spark.sql.execution.arrow.enabled true ``` Current Master w/ Arrow stream | This PR ---------------------|------------ 5.16207 | 4.342533 5.133671 | 4.399408 5.147513 | 4.468471 5.105243 | 4.36524 5.018685 | 4.373791 Avg Master | Avg This PR ------------------|-------------- 5.1134364 | 4.3898886 Speedup of **1.164821449** Closes apache#22275 from BryanCutler/arrow-toPandas-oo-batches-SPARK-25274. Authored-by: Bryan Cutler <cutlerb@gmail.com> Signed-off-by: Bryan Cutler <cutlerb@gmail.com>
-
[SPARK-26236][SS] Add kafka delegation token support documentation.
## What changes were proposed in this pull request? Kafka delegation token support implemented in [PR#22598](apache#22598) but that didn't contain documentation because of rapid changes. Because it has been merged in this PR I've documented it. ## How was this patch tested? jekyll build + manual html check Closes apache#23195 from gaborgsomogyi/SPARK-26236. Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com> Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
-
[SPARK-26194][K8S] Auto generate auth secret for k8s apps.
This change modifies the logic in the SecurityManager to do two things: - generate unique app secrets also when k8s is being used - only store the secret in the user's UGI on YARN The latter is needed so that k8s won't unnecessarily create k8s secrets for the UGI credentials when only the auth token is stored there. On the k8s side, the secret is propagated to executors using an environment variable instead. This ensures it works in both client and cluster mode. Security doc was updated to mention the feature and clarify that proper access control in k8s should be enabled for it to be secure. Author: Marcelo Vanzin <vanzin@cloudera.com> Closes apache#23174 from vanzin/SPARK-26194.
Commits on Dec 7, 2018
-
[SPARK-26289][CORE] cleanup enablePerfMetrics parameter from BytesToB…
…ytesMap ## What changes were proposed in this pull request? `enablePerfMetrics `was originally designed in `BytesToBytesMap `to control `getNumHashCollisions getTimeSpentResizingNs getAverageProbesPerLookup`. However, as the Spark version gradual progress. this parameter is only used for `getAverageProbesPerLookup ` and always given to true when using `BytesToBytesMap`. it is also dangerous to determine whether `getAverageProbesPerLookup `opens and throws an `IllegalStateException `exception. So this pr will be remove `enablePerfMetrics `parameter from `BytesToBytesMap`. thanks. ## How was this patch tested? the existed test cases. Closes apache#23244 from heary-cao/enablePerfMetrics. Authored-by: caoxuewen <cao.xuewen@zte.com.cn> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
-
[SPARK-26263][SQL] Validate partition values with user provided schema
## What changes were proposed in this pull request? Currently if user provides data schema, partition column values are converted as per it. But if the conversion failed, e.g. converting string to int, the column value is null. This PR proposes to throw exception in such case, instead of converting into null value silently: 1. These null partition column values doesn't make sense to users in most cases. It is better to show the conversion failure, and then users can adjust the schema or ETL jobs to fix it. 2. There are always exceptions on such conversion failure for non-partition data columns. Partition columns should have the same behavior. We can reproduce the case above as following: ``` /tmp/testDir ├── p=bar └── p=foo ``` If we run: ``` val schema = StructType(Seq(StructField("p", IntegerType, false))) spark.read.schema(schema).csv("/tmp/testDir/").show() ``` We will get: ``` +----+ | p| +----+ |null| |null| +----+ ``` ## How was this patch tested? Unit test Closes apache#23215 from gengliangwang/SPARK-26263. Authored-by: Gengliang Wang <gengliang.wang@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> -
[SPARK-26298][BUILD] Upgrade Janino to 3.0.11
## What changes were proposed in this pull request? This PR aims to upgrade Janino compiler to the latest version 3.0.11. The followings are the changes from the [release note](http://janino-compiler.github.io/janino/changelog.html). - Script with many "helper" variables. - Java 9+ compatibility - Compilation Error Messages Generated by JDK. - Added experimental support for the "StackMapFrame" attribute; not active yet. - Make Unparser more flexible. - Fixed NPEs in various "toString()" methods. - Optimize static method invocation with rvalue target expression. - Added all missing "ClassFile.getConstant*Info()" methods, removing the necessity for many type casts. ## How was this patch tested? Pass the Jenkins with the existing tests. Closes apache#23250 from dongjoon-hyun/SPARK-26298. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
-
[SPARK-26060][SQL][FOLLOW-UP] Rename the config name.
## What changes were proposed in this pull request? This is a follow-up of apache#23031 to rename the config name to `spark.sql.legacy.setCommandRejectsSparkCoreConfs`. ## How was this patch tested? Existing tests. Closes apache#23245 from ueshin/issues/SPARK-26060/rename_config. Authored-by: Takuya UESHIN <ueshin@databricks.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
-
[SPARK-26294][CORE] Delete Unnecessary If statement
## What changes were proposed in this pull request? Delete unnecessary If statement, because it Impossible execution when records less than or equal to zero.it is only execution when records begin zero. ................... if (inMemSorter == null || inMemSorter.numRecords() <= 0) { return 0L; } .................... if (inMemSorter.numRecords() > 0) { ..................... } ## How was this patch tested? Existing tests (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. Closes apache#23247 from wangjiaochun/inMemSorter. Authored-by: 10087686 <wang.jiaochun@zte.com.cn> Signed-off-by: Sean Owen <sean.owen@databricks.com> -
[MINOR][SQL][DOC] Correct parquet nullability documentation
## What changes were proposed in this pull request? Parquet files appear to have nullability info when being written, not being read. ## How was this patch tested? Some test code: (running spark 2.3, but the relevant code in DataSource looks identical on master) case class NullTest(bo: Boolean, opbol: Option[Boolean]) val testDf = spark.createDataFrame(Seq(NullTest(true, Some(false)))) defined class NullTest testDf: org.apache.spark.sql.DataFrame = [bo: boolean, opbol: boolean] testDf.write.parquet("s3://asana-stats/tmp_dima/parquet_check_schema") spark.read.parquet("s3://asana-stats/tmp_dima/parquet_check_schema/part-00000-b1bf4a19-d9fe-4ece-a2b4-9bbceb490857-c000.snappy.parquet4").printSchema() root |-- bo: boolean (nullable = true) |-- opbol: boolean (nullable = true) Meanwhile, the parquet file formed does have nullable info: []batchprod-report000:/tmp/dimakamalov-batch$ aws s3 ls s3://asana-stats/tmp_dima/parquet_check_schema/ 2018-10-17 21:03:52 0 _SUCCESS 2018-10-17 21:03:50 504 part-00000-b1bf4a19-d9fe-4ece-a2b4-9bbceb490857-c000.snappy.parquet []batchprod-report000:/tmp/dimakamalov-batch$ aws s3 cp s3://asana-stats/tmp_dima/parquet_check_schema/part-00000-b1bf4a19-d9fe-4ece-a2b4-9bbceb490857-c000.snappy.parquet . download: s3://asana-stats/tmp_dima/parquet_check_schema/part-00000-b1bf4a19-d9fe-4ece-a2b4-9bbceb490857-c000.snappy.parquet to ./part-00000-b1bf4a19-d9fe-4ece-a2b4-9bbceb490857-c000.snappy.parquet []batchprod-report000:/tmp/dimakamalov-batch$ java -jar parquet-tools-1.8.2.jar schema part-00000-b1bf4a19-d9fe-4ece-a2b4-9bbceb490857-c000.snappy.parquet message spark_schema { required boolean bo; optional boolean opbol; } Closes apache#22759 from dima-asana/dima-asana-nullable-parquet-doc. Authored-by: dima-asana <42555784+dima-asana@users.noreply.github.com> Signed-off-by: Sean Owen <sean.owen@databricks.com> -
[SPARK-26196][SPARK-26281][WEBUI] Total tasks title in the stage page…
… is incorrect when there are failed or killed tasks and update duration metrics ## What changes were proposed in this pull request? This PR fixes 3 issues 1) Total tasks message in the tasks table is incorrect, when there are failed or killed tasks 2) Sorting of the "Duration" column is not correct 3) Duration in the aggregated tasks summary table and the tasks table and not matching. Total tasks = numCompleteTasks + numActiveTasks + numKilledTasks + numFailedTasks; Corrected the duration metrics in the tasks table as executorRunTime based on the PR apache#23081 ## How was this patch tested? test step: 1) ``` bin/spark-shell scala > sc.parallelize(1 to 100, 10).map{ x => throw new RuntimeException("Bad executor")}.collect() ```  After patch:  2) Duration metrics: Before patch:  After patch:  Closes apache#23160 from shahidki31/totalTasks. Authored-by: Shahid <shahidki31@gmail.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[SPARK-24333][ML][PYTHON] Add fit with validation set to spark.ml GBT…
…: Python API ## What changes were proposed in this pull request? Add validationIndicatorCol and validationTol to GBT Python. ## How was this patch tested? Add test in doctest to test the new API. Closes apache#21465 from huaxingao/spark-24333. Authored-by: Huaxin Gao <huaxing@us.ibm.com> Signed-off-by: Bryan Cutler <cutlerb@gmail.com>
-
[SPARK-26304][SS] Add default value to spark.kafka.sasl.kerberos.serv…
…ice.name parameter ## What changes were proposed in this pull request? spark.kafka.sasl.kerberos.service.name is an optional parameter but most of the time value `kafka` has to be set. As I've written in the jira the following reasoning is behind: * Kafka's configuration guide suggest the same value: https://kafka.apache.org/documentation/#security_sasl_kerberos_brokerconfig * It would be easier for spark users by providing less configuration * Other streaming engines are doing the same In this PR I've changed the parameter from optional to `WithDefault` and set `kafka` as default value. ## How was this patch tested? Available unit tests + on cluster. Closes apache#23254 from gaborgsomogyi/SPARK-26304. Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com> Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Commits on Dec 8, 2018
-
[SPARK-26266][BUILD] Update to Scala 2.12.8
## What changes were proposed in this pull request? Update to Scala 2.12.8 ## How was this patch tested? Existing tests. Closes apache#23218 from srowen/SPARK-26266. Authored-by: Sean Owen <sean.owen@databricks.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[SPARK-24207][R] follow-up PR for SPARK-24207 to fix code style problems
## What changes were proposed in this pull request? follow-up PR for SPARK-24207 to fix code style problems Closes apache#23256 from huaxingao/spark-24207-cnt. Authored-by: Huaxin Gao <huaxing@us.ibm.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[SPARK-26021][SQL][FOLLOWUP] only deal with NaN and -0.0 in UnsafeWriter
## What changes were proposed in this pull request? A followup of apache#23043 There are 4 places we need to deal with NaN and -0.0: 1. comparison expressions. `-0.0` and `0.0` should be treated as same. Different NaNs should be treated as same. 2. Join keys. `-0.0` and `0.0` should be treated as same. Different NaNs should be treated as same. 3. grouping keys. `-0.0` and `0.0` should be assigned to the same group. Different NaNs should be assigned to the same group. 4. window partition keys. `-0.0` and `0.0` should be treated as same. Different NaNs should be treated as same. The case 1 is OK. Our comparison already handles NaN and -0.0, and for struct/array/map, we will recursively compare the fields/elements. Case 2, 3 and 4 are problematic, as they compare `UnsafeRow` binary directly, and different NaNs have different binary representation, and the same thing happens for -0.0 and 0.0. To fix it, a simple solution is: normalize float/double when building unsafe data (`UnsafeRow`, `UnsafeArrayData`, `UnsafeMapData`). Then we don't need to worry about it anymore. Following this direction, this PR moves the handling of NaN and -0.0 from `Platform` to `UnsafeWriter`, so that places like `UnsafeRow.setFloat` will not handle them, which reduces the perf overhead. It's also easier to add comments explaining why we do it in `UnsafeWriter`. ## How was this patch tested? existing tests Closes apache#23239 from cloud-fan/minor. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
Commits on Dec 9, 2018
-
[SPARK-25132][SQL][FOLLOWUP][DOC] Add migration doc for case-insensit…
…ive field resolution when reading from Parquet ## What changes were proposed in this pull request? apache#22148 introduces a behavior change. According to discussion at apache#22184, this PR updates migration guide when upgrade from Spark 2.3 to 2.4. ## How was this patch tested? N/A Closes apache#23238 from seancxmao/SPARK-25132-doc-2.4. Authored-by: seancxmao <seancxmao@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
-
[SPARK-26193][SQL] Implement shuffle write metrics in SQL
## What changes were proposed in this pull request? 1. Implement `SQLShuffleWriteMetricsReporter` on the SQL side as the customized `ShuffleWriteMetricsReporter`. 2. Add shuffle write metrics to `ShuffleExchangeExec`, and use these metrics to create corresponding `SQLShuffleWriteMetricsReporter` in shuffle dependency. 3. Rework on `ShuffleMapTask` to add new class named `ShuffleWriteProcessor` which control shuffle write process, we use sql shuffle write metrics by customizing a ShuffleWriteProcessor on SQL side. ## How was this patch tested? Add UT in SQLMetricsSuite. Manually test locally, update screen shot to document attached in JIRA. Closes apache#23207 from xuanyuanking/SPARK-26193. Authored-by: Yuanjian Li <xyliyuanjian@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
-
[SPARK-26283][CORE] Enable reading from open frames of zstd, when rea…
…ding zstd compressed eventLog ## What changes were proposed in this pull request? Root cause: Prior to Spark2.4, When we enable zst for eventLog compression, for inprogress application, It always throws exception in the Application UI, when we open from the history server. But after 2.4 it will display the UI information based on the completed frames in the zstd compressed eventLog. But doesn't read incomplete frames for inprogress application. In this PR, we have added 'setContinous(true)' for reading input stream from eventLog, so that it can read from open frames also. (By default 'isContinous=false' for zstd inputStream and when we try to read an open frame, it throws truncated error) ## How was this patch tested? Test steps: 1) Add the configurations in the spark-defaults.conf (i) spark.eventLog.compress true (ii) spark.io.compression.codec zstd 2) Restart history server 3) bin/spark-shell 4) sc.parallelize(1 to 1000, 1000).count 5) Open app UI from the history server UI **Before fix**  **After fix:**  Closes apache#23241 from shahidki31/zstdEventLog. Authored-by: Shahid <shahidki31@gmail.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
{kind=link}
{kind=link}
Commits on Dec 10, 2018
-
[SPARK-26287][CORE] Don't need to create an empty spill file when mem…
…ory has no records ## What changes were proposed in this pull request? If there are no records in memory, then we don't need to create an empty temp spill file. ## How was this patch tested? Existing tests (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. Closes apache#23225 from wangjiaochun/ShufflSorter. Authored-by: 10087686 <wang.jiaochun@zte.com.cn> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
-
[SPARK-26307][SQL] Fix CTAS when INSERT a partitioned table using Hiv…
…e serde ## What changes were proposed in this pull request? This is a Spark 2.3 regression introduced in apache#20521. We should add the partition info for InsertIntoHiveTable in CreateHiveTableAsSelectCommand. Otherwise, we will hit the following error by running the newly added test case: ``` [info] - CTAS: INSERT a partitioned table using Hive serde *** FAILED *** (829 milliseconds) [info] org.apache.spark.SparkException: Requested partitioning does not match the tab1 table: [info] Requested partitions: [info] Table partitions: part [info] at org.apache.spark.sql.hive.execution.InsertIntoHiveTable.processInsert(InsertIntoHiveTable.scala:179) [info] at org.apache.spark.sql.hive.execution.InsertIntoHiveTable.run(InsertIntoHiveTable.scala:107) ``` ## How was this patch tested? Added a test case. Closes apache#23255 from gatorsmile/fixCTAS. Authored-by: gatorsmile <gatorsmile@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
-
[SPARK-26319][SQL][TEST] Add appendReadColumns Unit Test for HiveShim…
…Suite ## What changes were proposed in this pull request? Add appendReadColumns Unit Test for HiveShimSuite. ## How was this patch tested? ``` $ build/sbt > project hive > testOnly *HiveShimSuite ``` Closes apache#23268 from sadhen/refactor/hiveshim. Authored-by: Darcy Shen <sadhen@zoho.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[SPARK-26286][TEST] Add MAXIMUM_PAGE_SIZE_BYTES exception bound unit …
…test ## What changes were proposed in this pull request? Add MAXIMUM_PAGE_SIZE_BYTES Exception test ## How was this patch tested? Existing tests (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. Closes apache#23226 from wangjiaochun/BytesToBytesMapSuite. Authored-by: 10087686 <wang.jiaochun@zte.com.cn> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[MINOR][DOC] Update the condition description of serialized shuffle
## What changes were proposed in this pull request? `1. The shuffle dependency specifies no aggregation or output ordering.` If the shuffle dependency specifies aggregation, but it only aggregates at the reduce-side, serialized shuffle can still be used. `3. The shuffle produces fewer than 16777216 output partitions.` If the number of output partitions is 16777216 , we can use serialized shuffle. We can see this mothod: `canUseSerializedShuffle` ## How was this patch tested? N/A Closes apache#23228 from 10110346/SerializedShuffle_doc. Authored-by: liuxian <liu.xian3@zte.com.cn> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
-
-
-
[SPARK-24958][CORE] Add memory from procfs to executor metrics.
This adds the entire memory used by spark’s executor (as measured by procfs) to the executor metrics. The memory usage is collected from the entire process tree under the executor. The metrics are subdivided into memory used by java, by python, and by other processes, to aid users in diagnosing the source of high memory usage. The additional metrics are sent to the driver in heartbeats, using the mechanism introduced by SPARK-23429. This also slightly extends that approach to allow one ExecutorMetricType to collect multiple metrics. Added unit tests and also tested on a live cluster. Closes apache#22612 from rezasafi/ptreememory2. Authored-by: Reza Safi <rezasafi@cloudera.com> Signed-off-by: Imran Rashid <irashid@cloudera.com>
-
[SPARK-26317][BUILD] Upgrade SBT to 0.13.18
## What changes were proposed in this pull request? SBT 0.13.14 ~ 1.1.1 has a bug on accessing `java.util.Base64.getDecoder` with JDK9+. It's fixed at 1.1.2 and backported to [0.13.18 (released on Nov 28th)](https://github.com/sbt/sbt/releases/tag/v0.13.18). This PR aims to update SBT. ## How was this patch tested? Pass the Jenkins with the building and existing tests. Closes apache#23270 from dongjoon-hyun/SPARK-26317. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
Commits on Dec 11, 2018
-
[SPARK-25696] The storage memory displayed on spark Application UI is…
… incorrect. ## What changes were proposed in this pull request? In the reported heartbeat information, the unit of the memory data is bytes, which is converted by the formatBytes() function in the utils.js file before being displayed in the interface. The cardinality of the unit conversion in the formatBytes function is 1000, which should be 1024. Change the cardinality of the unit conversion in the formatBytes function to 1024. ## How was this patch tested? manual tests Please review http://spark.apache.org/contributing.html before opening a pull request. Closes apache#22683 from httfighter/SPARK-25696. Lead-authored-by: 韩田田00222924 <han.tiantian@zte.com.cn> Co-authored-by: han.tiantian@zte.com.cn <han.tiantian@zte.com.cn> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[SPARK-19827][R] spark.ml R API for PIC
## What changes were proposed in this pull request? Add PowerIterationCluster (PIC) in R ## How was this patch tested? Add test case Closes apache#23072 from huaxingao/spark-19827. Authored-by: Huaxin Gao <huaxing@us.ibm.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[SPARK-26312][SQL] Replace RDDConversions.rowToRowRdd with RowEncoder…
… to improve its conversion performance ## What changes were proposed in this pull request? `RDDConversions` would get disproportionately slower as the number of columns in the query increased, for the type of `converters` before is `scala.collection.immutable.::` which is a subtype of list. This PR removing `RDDConversions` and using `RowEncoder` to convert the Row to InternalRow. The test of `PrunedScanSuite` for 2000 columns and 20k rows takes 409 seconds before this PR, and 361 seconds after. ## How was this patch tested? Test case of `PrunedScanSuite` Closes apache#23262 from eatoncys/toarray. Authored-by: 10129659 <chen.yanshan@zte.com.cn> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[SPARK-26293][SQL] Cast exception when having python udf in subquery
## What changes were proposed in this pull request? This is a regression introduced by apache#22104 at Spark 2.4.0. When we have Python UDF in subquery, we will hit an exception ``` Caused by: java.lang.ClassCastException: org.apache.spark.sql.catalyst.expressions.AttributeReference cannot be cast to org.apache.spark.sql.catalyst.expressions.PythonUDF at scala.collection.immutable.Stream.map(Stream.scala:414) at org.apache.spark.sql.execution.python.EvalPythonExec.$anonfun$doExecute$2(EvalPythonExec.scala:98) at org.apache.spark.rdd.RDD.$anonfun$mapPartitions$2(RDD.scala:815) ... ``` apache#22104 turned `ExtractPythonUDFs` from a physical rule to optimizer rule. However, there is a difference between a physical rule and optimizer rule. A physical rule always runs once, an optimizer rule may be applied twice on a query tree even the rule is located in a batch that only runs once. For a subquery, the `OptimizeSubqueries` rule will execute the entire optimizer on the query plan inside subquery. Later on subquery will be turned to joins, and the optimizer rules will be applied to it again. Unfortunately, the `ExtractPythonUDFs` rule is not idempotent. When it's applied twice on a query plan inside subquery, it will produce a malformed plan. It extracts Python UDF from Python exec plans. This PR proposes 2 changes to be double safe: 1. `ExtractPythonUDFs` should skip python exec plans, to make the rule idempotent 2. `ExtractPythonUDFs` should skip subquery ## How was this patch tested? a new test. Closes apache#23248 from cloud-fan/python. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
-
[SPARK-26303][SQL] Return partial results for bad JSON records
## What changes were proposed in this pull request? In the PR, I propose to return partial results from JSON datasource and JSON functions in the PERMISSIVE mode if some of JSON fields are parsed and converted to desired types successfully. The changes are made only for `StructType`. Whole bad JSON records are placed into the corrupt column specified by the `columnNameOfCorruptRecord` option or SQL config. Partial results are not returned for malformed JSON input. ## How was this patch tested? Added new UT which checks converting JSON strings with one invalid and one valid field at the end of the string. Closes apache#23253 from MaxGekk/json-bad-record. Lead-authored-by: Maxim Gekk <max.gekk@gmail.com> Co-authored-by: Maxim Gekk <maxim.gekk@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[SPARK-26327][SQL] Bug fix for
FileSourceScanExecmetrics update an……d name changing ## What changes were proposed in this pull request? As the description in [SPARK-26327](https://issues.apache.org/jira/browse/SPARK-26327), `postDriverMetricUpdates` was called on wrong place cause this bug, fix this by split the initializing of `selectedPartitions` and metrics updating logic. Add the updating logic in `inputRDD` initializing which can take effect in both code generation node and normal node. Also rename `metadataTime` to `fileListingTime` for clearer meaning. ## How was this patch tested? New test case in `SQLMetricsSuite`. Manual test: | | Before | After | |---------|:--------:|:-------:| | CodeGen ||| | Normal ||| Closes apache#23277 from xuanyuanking/SPARK-26327. Authored-by: Yuanjian Li <xyliyuanjian@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
-
[SPARK-26265][CORE] Fix deadlock in BytesToBytesMap.MapIterator when …
…locking both BytesToBytesMap.MapIterator and TaskMemoryManager ## What changes were proposed in this pull request? In `BytesToBytesMap.MapIterator.advanceToNextPage`, We will first lock this `MapIterator` and then `TaskMemoryManager` when going to free a memory page by calling `freePage`. At the same time, it is possibly that another memory consumer first locks `TaskMemoryManager` and then this `MapIterator` when it acquires memory and causes spilling on this `MapIterator`. So it ends with the `MapIterator` object holds lock to the `MapIterator` object and waits for lock on `TaskMemoryManager`, and the other consumer holds lock to `TaskMemoryManager` and waits for lock on the `MapIterator` object. To avoid deadlock here, this patch proposes to keep reference to the page to free and free it after releasing the lock of `MapIterator`. ## How was this patch tested? Added test and manually test by running the test 100 times to make sure there is no deadlock. Closes apache#23272 from viirya/SPARK-26265. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
-
[SPARK-26316][SPARK-21052] Revert hash join metrics in that causes pe…
…rformance degradation ## What changes were proposed in this pull request? The wrong implementation in the hash join metrics in [spark 21052](https://issues.apache.org/jira/browse/SPARK-21052) caused significant performance degradation in TPC-DS. And the result is [here](https://docs.google.com/spreadsheets/d/18a5BdOlmm8euTaRodyeWum9yu92mbWWu6JbhGXtr7yE/edit#gid=0) in TPC-DS 1TB scale. So we currently partial revert 21052. **Cluster info:** | Master Node | Worker Nodes -- | -- | -- Node | 1x | 4x Processor | Intel(R) Xeon(R) Platinum 8170 CPU 2.10GHz | Intel(R) Xeon(R) Platinum 8180 CPU 2.50GHz Memory | 192 GB | 384 GB Storage Main | 8 x 960G SSD | 8 x 960G SSD Network | 10Gbe | Role | CM Management NameNodeSecondary NameNodeResource ManagerHive Metastore Server | DataNodeNodeManager OS Version | CentOS 7.2 | CentOS 7.2 Hadoop | Apache Hadoop 2.7.5 | Apache Hadoop 2.7.5 Hive | Apache Hive 2.2.0 | Spark | Apache Spark 2.1.0 & Apache Spark2.3.0 | JDK version | 1.8.0_112 | 1.8.0_112 **Related parameters setting:** Component | Parameter | Value -- | -- | -- Yarn Resource Manager | yarn.scheduler.maximum-allocation-mb | 120GB | yarn.scheduler.minimum-allocation-mb | 1GB | yarn.scheduler.maximum-allocation-vcores | 121 | Yarn.resourcemanager.scheduler.class | Fair Scheduler Yarn Node Manager | yarn.nodemanager.resource.memory-mb | 120GB | yarn.nodemanager.resource.cpu-vcores | 121 Spark | spark.executor.memory | 110GB | spark.executor.cores | 50 ## How was this patch tested? N/A Closes apache#23269 from JkSelf/partial-revert-21052. Authored-by: jiake <ke.a.jia@intel.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
-
[SPARK-26300][SS] Remove a redundant
checkForStreamingcall## What changes were proposed in this pull request? If `checkForContinuous` is called ( `checkForStreaming` is called in `checkForContinuous` ), the `checkForStreaming` mothod will be called twice in `createQuery` , this is not necessary, and the `checkForStreaming` method has a lot of statements, so it's better to remove one of them. ## How was this patch tested? Existing unit tests in `StreamingQueryManagerSuite` and `ContinuousAggregationSuite` Closes apache#23251 from 10110346/isUnsupportedOperationCheckEnabled. Authored-by: liuxian <liu.xian3@zte.com.cn> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
-
[SPARK-26239] File-based secret key loading for SASL.
This proposes an alternative way to load secret keys into a Spark application that is running on Kubernetes. Instead of automatically generating the secret, the secret key can reside in a file that is shared between both the driver and executor containers. Unit tests. Closes apache#23252 from mccheah/auth-secret-with-file. Authored-by: mcheah <mcheah@palantir.com> Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
|](https://user-images.githubusercontent.com/4833765/49741753-13c7e800-fcd2-11e8-97a8-8057b657aa3c.png)||){kind=link}
|](https://user-images.githubusercontent.com/4833765/49741836-378b2e00-fcd2-11e8-80c3-ab462a6a3184.png)||){kind=link}
Commits on Dec 12, 2018
-
[SPARK-26193][SQL][FOLLOW UP] Read metrics rename and display text ch…
…anges ## What changes were proposed in this pull request? Follow up pr for apache#23207, include following changes: - Rename `SQLShuffleMetricsReporter` to `SQLShuffleReadMetricsReporter` to make it match with write side naming. - Display text changes for read side for naming consistent. - Rename function in `ShuffleWriteProcessor`. - Delete `private[spark]` in execution package. ## How was this patch tested? Existing tests. Closes apache#23286 from xuanyuanking/SPARK-26193-follow. Authored-by: Yuanjian Li <xyliyuanjian@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
-
[SPARK-19827][R][FOLLOWUP] spark.ml R API for PIC
## What changes were proposed in this pull request? Follow up style fixes to PIC in R; see apache#23072 ## How was this patch tested? Existing tests. Closes apache#23292 from srowen/SPARK-19827.2. Authored-by: Sean Owen <sean.owen@databricks.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[SPARK-24102][ML][MLLIB] ML Evaluators should use weight column - add…
…ed weight column for regression evaluator ## What changes were proposed in this pull request? The evaluators BinaryClassificationEvaluator, RegressionEvaluator, and MulticlassClassificationEvaluator and the corresponding metrics classes BinaryClassificationMetrics, RegressionMetrics and MulticlassMetrics should use sample weight data. I've closed the PR: apache#16557 as recommended in favor of creating three pull requests, one for each of the evaluators (binary/regression/multiclass) to make it easier to review/update. The updates to the regression metrics were based on (and updated with new changes based on comments): https://issues.apache.org/jira/browse/SPARK-11520 ("RegressionMetrics should support instance weights") but the pull request was closed as the changes were never checked in. ## How was this patch tested? I added tests to the metrics class. Closes apache#17085 from imatiach-msft/ilmat/regression-evaluate. Authored-by: Ilya Matiach <ilmat@microsoft.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[SPARK-25877][K8S] Move all feature logic to feature classes.
This change makes the driver and executor builders a lot simpler by encapsulating almost all feature logic into the respective feature classes. The only logic that remains is the creation of the initial pod, which needs to happen before anything else so is better to be left in the builder class. Most feature classes already behave fine when the config has nothing they should handle, but a few minor tweaks had to be added. Unit tests were also updated or added to account for these. The builder suites were simplified a lot and just test the remaining pod-related code in the builders themselves. Author: Marcelo Vanzin <vanzin@cloudera.com> Closes apache#23220 from vanzin/SPARK-25877.
Commits on Dec 13, 2018
-
[SPARK-25277][YARN] YARN applicationMaster metrics should not registe…
…r static metrics ## What changes were proposed in this pull request? YARN applicationMaster metrics registration introduced in SPARK-24594 causes further registration of static metrics (Codegenerator and HiveExternalCatalog) and of JVM metrics, which I believe do not belong in this context. This looks like an unintended side effect of using the start method of [[MetricsSystem]]. A possible solution proposed here, is to introduce startNoRegisterSources to avoid these additional registrations of static sources and of JVM sources in the case of YARN applicationMaster metrics (this could be useful for other metrics that may be added in the future). ## How was this patch tested? Manually tested on a YARN cluster, Closes apache#22279 from LucaCanali/YarnMetricsRemoveExtraSourceRegistration. Lead-authored-by: Luca Canali <luca.canali@cern.ch> Co-authored-by: LucaCanali <luca.canali@cern.ch> Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
-
[SPARK-26322][SS] Add spark.kafka.sasl.token.mechanism to ease delega…
…tion token configuration. ## What changes were proposed in this pull request? When Kafka delegation token obtained, SCRAM `sasl.mechanism` has to be configured for authentication. This can be configured on the related source/sink which is inconvenient from user perspective. Such granularity is not required and this configuration can be implemented with one central parameter. In this PR `spark.kafka.sasl.token.mechanism` added to configure this centrally (default: `SCRAM-SHA-512`). ## How was this patch tested? Existing unit tests + on cluster. Closes apache#23274 from gaborgsomogyi/SPARK-26322. Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com> Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
-
[SPARK-26297][SQL] improve the doc of Distribution/Partitioning
## What changes were proposed in this pull request? Some documents of `Distribution/Partitioning` are stale and misleading, this PR fixes them: 1. `Distribution` never have intra-partition requirement 2. `OrderedDistribution` does not require tuples that share the same value being colocated in the same partition. 3. `RangePartitioning` can provide a weaker guarantee for a prefix of its `ordering` expressions. ## How was this patch tested? comment-only PR. Closes apache#23249 from cloud-fan/doc. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
-
[SPARK-26348][SQL][TEST] make sure expression is resolved during test
## What changes were proposed in this pull request? cleanup some tests to make sure expression is resolved during test. ## How was this patch tested? test-only PR Closes apache#23297 from cloud-fan/test. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
-
[SPARK-26355][PYSPARK] Add a workaround for PyArrow 0.11.
## What changes were proposed in this pull request? In PyArrow 0.11, there is a API breaking change. - [ARROW-1949](https://issues.apache.org/jira/browse/ARROW-1949) - [Python/C++] Add option to Array.from_pandas and pyarrow.array to perform unsafe casts. This causes test failures in `ScalarPandasUDFTests.test_vectorized_udf_null_(byte|short|int|long)`: ``` File "/Users/ueshin/workspace/apache-spark/spark/python/pyspark/worker.py", line 377, in main process() File "/Users/ueshin/workspace/apache-spark/spark/python/pyspark/worker.py", line 372, in process serializer.dump_stream(func(split_index, iterator), outfile) File "/Users/ueshin/workspace/apache-spark/spark/python/pyspark/serializers.py", line 317, in dump_stream batch = _create_batch(series, self._timezone) File "/Users/ueshin/workspace/apache-spark/spark/python/pyspark/serializers.py", line 286, in _create_batch arrs = [create_array(s, t) for s, t in series] File "/Users/ueshin/workspace/apache-spark/spark/python/pyspark/serializers.py", line 284, in create_array return pa.Array.from_pandas(s, mask=mask, type=t) File "pyarrow/array.pxi", line 474, in pyarrow.lib.Array.from_pandas return array(obj, mask=mask, type=type, safe=safe, from_pandas=True, File "pyarrow/array.pxi", line 169, in pyarrow.lib.array return _ndarray_to_array(values, mask, type, from_pandas, safe, File "pyarrow/array.pxi", line 69, in pyarrow.lib._ndarray_to_array check_status(NdarrayToArrow(pool, values, mask, from_pandas, File "pyarrow/error.pxi", line 81, in pyarrow.lib.check_status raise ArrowInvalid(message) ArrowInvalid: Floating point value truncated ``` We should add a workaround to support PyArrow 0.11. ## How was this patch tested? In my local environment. Closes apache#23305 from ueshin/issues/SPARK-26355/pyarrow_0.11. Authored-by: Takuya UESHIN <ueshin@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[MINOR][R] Fix indents of sparkR welcome message to be consistent wit…
…h pyspark and spark-shell ## What changes were proposed in this pull request? 1. Removed empty space at the beginning of welcome message lines of sparkR to be consistent with welcome message of `pyspark` and `spark-shell` 2. Setting indent of logo message lines to 3 to be consistent with welcome message of `pyspark` and `spark-shell` Output of `pyspark`: ``` Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /__ / .__/\_,_/_/ /_/\_\ version 2.4.0 /_/ Using Python version 3.6.6 (default, Jun 28 2018 11:07:29) SparkSession available as 'spark'. ``` Output of `spark-shell`: ``` Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2.4.0 /_/ Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_161) Type in expressions to have them evaluated. Type :help for more information. ``` ## How was this patch tested? Before: Output of `sparkR`: ``` Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2.4.0 /_/ SparkSession available as 'spark'. ``` After: ``` Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 2.4.0 /_/ SparkSession available as 'spark'. ``` Closes apache#23293 from AzureQ/master. Authored-by: Qi Shao <qi.shao.nyu@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> -
[MINOR][DOC] Fix comments of ConvertToLocalRelation rule
## What changes were proposed in this pull request? There are some comments issues left when `ConvertToLocalRelation` rule was added (see apache#22205/[SPARK-25212](https://issues.apache.org/jira/browse/SPARK-25212)). This PR fixes those comments issues. ## How was this patch tested? N/A Closes apache#23273 from seancxmao/ConvertToLocalRelation-doc. Authored-by: seancxmao <seancxmao@gmail.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[MINOR][DOC] update the condition description of BypassMergeSortShuffle
## What changes were proposed in this pull request? These three condition descriptions should be updated, follow apache#23228 : <li>no Ordering is specified,</li> <li>no Aggregator is specified, and</li> <li>the number of partitions is less than <code>spark.shuffle.sort.bypassMergeThreshold</code>. </li> 1、If the shuffle dependency specifies aggregation, but it only aggregates at the reduce-side, BypassMergeSortShuffle can still be used. 2、If the number of output partitions is spark.shuffle.sort.bypassMergeThreshold(eg.200), we can use BypassMergeSortShuffle. ## How was this patch tested? N/A Closes apache#23281 from lcqzte10192193/wid-lcq-1211. Authored-by: lichaoqun <li.chaoqun@zte.com.cn> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[SPARK-26340][CORE] Ensure cores per executor is greater than cpu per…
… task Currently this check is only performed for dynamic allocation use case in ExecutorAllocationManager. ## What changes were proposed in this pull request? Checks that cpu per task is lower than number of cores per executor otherwise throw an exception ## How was this patch tested? manual tests Please review http://spark.apache.org/contributing.html before opening a pull request. Closes apache#23290 from ashangit/master. Authored-by: n.fraison <n.fraison@criteo.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[SPARK-26313][SQL] move
newScanBuilderfrom Table to read related m……ix-in traits ## What changes were proposed in this pull request? As discussed in https://github.com/apache/spark/pull/23208/files#r239684490 , we should put `newScanBuilder` in read related mix-in traits like `SupportsBatchRead`, to support write-only table. In the `Append` operator, we should skip schema validation if not necessary. In the future we would introduce a capability API, so that data source can tell Spark that it doesn't want to do validation. ## How was this patch tested? existing tests. Closes apache#23266 from cloud-fan/ds-read. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[SPARK-26098][WEBUI] Show associated SQL query in Job page
## What changes were proposed in this pull request? For jobs associated to SQL queries, it would be easier to understand the context to showing the SQL query in Job detail page. Before code change, it is hard to tell what the job is about from the job page:  After code change:  After navigating to the associated SQL detail page, We can see the whole context :  **For Jobs don't have associated SQL query, the text won't be shown.** ## How was this patch tested? Manual test Closes apache#23068 from gengliangwang/addSQLID. Authored-by: Gengliang Wang <gengliang.wang@databricks.com> Signed-off-by: gatorsmile <gatorsmile@gmail.com>
{kind=link}
{kind=link}
{kind=link}
Commits on Dec 14, 2018
-
[SPARK-23886][SS] Update query status for ContinuousExecution
## What changes were proposed in this pull request? Added query status updates to ContinuousExecution. ## How was this patch tested? Existing unit tests + added ContinuousQueryStatusAndProgressSuite. Closes apache#23095 from gaborgsomogyi/SPARK-23886. Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com> Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
-
[SPARK-26364][PYTHON][TESTING] Clean up imports in test_pandas_udf*
## What changes were proposed in this pull request? Clean up unconditional import statements and move them to the top. Conditional imports (pandas, numpy, pyarrow) are left as-is. ## How was this patch tested? Exising tests. Closes apache#23314 from icexelloss/clean-up-test-imports. Authored-by: Li Jin <ice.xelloss@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[SPARK-26360] remove redundant validateQuery call
## What changes were proposed in this pull request? remove a redundant `KafkaWriter.validateQuery` call in `KafkaSourceProvider ` ## How was this patch tested? Just removing duplicate codes, so I just build and run unit tests. Closes apache#23309 from JasonWayne/SPARK-26360. Authored-by: jasonwayne <wuwenjie0102@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[SPARK-26337][SQL][TEST] Add benchmark for LongToUnsafeRowMap
## What changes were proposed in this pull request? Regarding the performance issue of SPARK-26155, it reports the issue on TPC-DS. I think it is better to add a benchmark for `LongToUnsafeRowMap` which is the root cause of performance regression. It can be easier to show performance difference between different metric implementations in `LongToUnsafeRowMap`. ## How was this patch tested? Manually run added benchmark. Closes apache#23284 from viirya/SPARK-26337. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
-
[SPARK-26368][SQL] Make it clear that getOrInferFileFormatSchema does…
…n't create InMemoryFileIndex ## What changes were proposed in this pull request? I was looking at the code and it was a bit difficult to see the life cycle of InMemoryFileIndex passed into getOrInferFileFormatSchema, because once it is passed in, and another time it was created in getOrInferFileFormatSchema. It'd be easier to understand the life cycle if we move the creation of it out. ## How was this patch tested? This is a simple code move and should be covered by existing tests. Closes apache#23317 from rxin/SPARK-26368. Authored-by: Reynold Xin <rxin@databricks.com> Signed-off-by: gatorsmile <gatorsmile@gmail.com>
-
[SPARK-26370][SQL] Fix resolution of higher-order function for the sa…
…me identifier. ## What changes were proposed in this pull request? When using a higher-order function with the same variable name as the existing columns in `Filter` or something which uses `Analyzer.resolveExpressionBottomUp` during the resolution, e.g.,: ```scala val df = Seq( (Seq(1, 9, 8, 7), 1, 2), (Seq(5, 9, 7), 2, 2), (Seq.empty, 3, 2), (null, 4, 2) ).toDF("i", "x", "d") checkAnswer(df.filter("exists(i, x -> x % d == 0)"), Seq(Row(Seq(1, 9, 8, 7), 1, 2))) checkAnswer(df.select("x").filter("exists(i, x -> x % d == 0)"), Seq(Row(1))) ``` the following exception happens: ``` java.lang.ClassCastException: org.apache.spark.sql.catalyst.expressions.BoundReference cannot be cast to org.apache.spark.sql.catalyst.expressions.NamedExpression at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:237) at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62) at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55) at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49) at scala.collection.TraversableLike.map(TraversableLike.scala:237) at scala.collection.TraversableLike.map$(TraversableLike.scala:230) at scala.collection.AbstractTraversable.map(Traversable.scala:108) at org.apache.spark.sql.catalyst.expressions.HigherOrderFunction.$anonfun$functionsForEval$1(higherOrderFunctions.scala:147) at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:237) at scala.collection.immutable.List.foreach(List.scala:392) at scala.collection.TraversableLike.map(TraversableLike.scala:237) at scala.collection.TraversableLike.map$(TraversableLike.scala:230) at scala.collection.immutable.List.map(List.scala:298) at org.apache.spark.sql.catalyst.expressions.HigherOrderFunction.functionsForEval(higherOrderFunctions.scala:145) at org.apache.spark.sql.catalyst.expressions.HigherOrderFunction.functionsForEval$(higherOrderFunctions.scala:145) at org.apache.spark.sql.catalyst.expressions.ArrayExists.functionsForEval$lzycompute(higherOrderFunctions.scala:369) at org.apache.spark.sql.catalyst.expressions.ArrayExists.functionsForEval(higherOrderFunctions.scala:369) at org.apache.spark.sql.catalyst.expressions.SimpleHigherOrderFunction.functionForEval(higherOrderFunctions.scala:176) at org.apache.spark.sql.catalyst.expressions.SimpleHigherOrderFunction.functionForEval$(higherOrderFunctions.scala:176) at org.apache.spark.sql.catalyst.expressions.ArrayExists.functionForEval(higherOrderFunctions.scala:369) at org.apache.spark.sql.catalyst.expressions.ArrayExists.nullSafeEval(higherOrderFunctions.scala:387) at org.apache.spark.sql.catalyst.expressions.SimpleHigherOrderFunction.eval(higherOrderFunctions.scala:190) at org.apache.spark.sql.catalyst.expressions.SimpleHigherOrderFunction.eval$(higherOrderFunctions.scala:185) at org.apache.spark.sql.catalyst.expressions.ArrayExists.eval(higherOrderFunctions.scala:369) at org.apache.spark.sql.catalyst.expressions.GeneratedClass$SpecificPredicate.eval(Unknown Source) at org.apache.spark.sql.execution.FilterExec.$anonfun$doExecute$3(basicPhysicalOperators.scala:216) at org.apache.spark.sql.execution.FilterExec.$anonfun$doExecute$3$adapted(basicPhysicalOperators.scala:215) ... ``` because the `UnresolvedAttribute`s in `LambdaFunction` are unexpectedly resolved by the rule. This pr modified to use a placeholder `UnresolvedNamedLambdaVariable` to prevent unexpected resolution. ## How was this patch tested? Added a test and modified some tests. Closes apache#23320 from ueshin/issues/SPARK-26370/hof_resolution. Authored-by: Takuya UESHIN <ueshin@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> -
[MINOR][SQL] Some errors in the notes.
## What changes were proposed in this pull request? When using ordinals to access linked list, the time cost is O(n). ## How was this patch tested? Existing tests. Closes apache#23280 from CarolinePeng/update_Two. Authored-by: CarolinPeng <00244106@zte.intra> Signed-off-by: Sean Owen <sean.owen@databricks.com>
Commits on Dec 15, 2018
-
[SPARK-26265][CORE][FOLLOWUP] Put freePage into a finally block
## What changes were proposed in this pull request? Based on the [comment](apache#23272 (comment)), it seems to be better to put `freePage` into a `finally` block. This patch as a follow-up to do so. ## How was this patch tested? Existing tests. Closes apache#23294 from viirya/SPARK-26265-followup. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[SPARK-26362][CORE] Remove 'spark.driver.allowMultipleContexts' to di…
…sallow multiple creation of SparkContexts ## What changes were proposed in this pull request? Multiple SparkContexts are discouraged and it has been warning for last 4 years, see SPARK-4180. It could cause arbitrary and mysterious error cases, see SPARK-2243. Honestly, I didn't even know Spark still allows it, which looks never officially supported, see SPARK-2243. I believe It should be good timing now to remove this configuration. ## How was this patch tested? Each doc was manually checked and manually tested: ``` $ ./bin/spark-shell --conf=spark.driver.allowMultipleContexts=true ... scala> new SparkContext() org.apache.spark.SparkException: Only one SparkContext should be running in this JVM (see SPARK-2243).The currently running SparkContext was created at: org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:939) ... org.apache.spark.SparkContext$.$anonfun$assertNoOtherContextIsRunning$2(SparkContext.scala:2435) at scala.Option.foreach(Option.scala:274) at org.apache.spark.SparkContext$.assertNoOtherContextIsRunning(SparkContext.scala:2432) at org.apache.spark.SparkContext$.markPartiallyConstructed(SparkContext.scala:2509) at org.apache.spark.SparkContext.<init>(SparkContext.scala:80) at org.apache.spark.SparkContext.<init>(SparkContext.scala:112) ... 49 elided ``` Closes apache#23311 from HyukjinKwon/SPARK-26362. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[SPARK-26315][PYSPARK] auto cast threshold from Integer to Float in a…
…pproxSimilarityJoin of BucketedRandomProjectionLSHModel ## What changes were proposed in this pull request? If the input parameter 'threshold' to the function approxSimilarityJoin is not a float, we would get an exception. The fix is to convert the 'threshold' into a float before calling the java implementation method. ## How was this patch tested? Added a new test case. Without this fix, the test will throw an exception as reported in the JIRA. With the fix, the test passes. Please review http://spark.apache.org/contributing.html before opening a pull request. Closes apache#23313 from jerryjch/SPARK-26315. Authored-by: Jing Chen He <jinghe@us.ibm.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
Commits on Dec 16, 2018
-
[SPARK-26243][SQL] Use java.time API for parsing timestamps and dates…
… from JSON ## What changes were proposed in this pull request? In the PR, I propose to switch on **java.time API** for parsing timestamps and dates from JSON inputs with microseconds precision. The SQL config `spark.sql.legacy.timeParser.enabled` allow to switch back to previous behavior with using `java.text.SimpleDateFormat`/`FastDateFormat` for parsing/generating timestamps/dates. ## How was this patch tested? It was tested by `JsonExpressionsSuite`, `JsonFunctionsSuite` and `JsonSuite`. Closes apache#23196 from MaxGekk/json-time-parser. Lead-authored-by: Maxim Gekk <maxim.gekk@databricks.com> Co-authored-by: Maxim Gekk <max.gekk@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
-
[SPARK-26078][SQL] Dedup self-join attributes on IN subqueries
## What changes were proposed in this pull request? When there is a self-join as result of a IN subquery, the join condition may be invalid, resulting in trivially true predicates and return wrong results. The PR deduplicates the subquery output in order to avoid the issue. ## How was this patch tested? added UT Closes apache#23057 from mgaido91/SPARK-26078. Authored-by: Marco Gaido <marcogaido91@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
-
[SPARK-26372][SQL] Don't reuse value from previous row when parsing b…
…ad CSV input field ## What changes were proposed in this pull request? CSV parsing accidentally uses the previous good value for a bad input field. See example in Jira. This PR ensures that the associated column is set to null when an input field cannot be converted. ## How was this patch tested? Added new test. Ran all SQL unit tests (testOnly org.apache.spark.sql.*). Ran pyspark tests for pyspark-sql Closes apache#23323 from bersprockets/csv-bad-field. Authored-by: Bruce Robbins <bersprockets@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
Commits on Dec 17, 2018
-
[SPARK-26248][SQL] Infer date type from CSV
## What changes were proposed in this pull request? The `CSVInferSchema` class is extended to support inferring of `DateType` from CSV input. The attempt to infer `DateType` is performed after inferring `TimestampType`. ## How was this patch tested? Added new test for inferring date types from CSV . It was also tested by existing suites like `CSVInferSchemaSuite`, `CsvExpressionsSuite`, `CsvFunctionsSuite` and `CsvSuite`. Closes apache#23202 from MaxGekk/csv-date-inferring. Lead-authored-by: Maxim Gekk <max.gekk@gmail.com> Co-authored-by: Maxim Gekk <maxim.gekk@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
-
[MINOR][DOCS] Fix the "not found: value Row" error on the "programmat…
…ic_schema" example ## What changes were proposed in this pull request? Print `import org.apache.spark.sql.Row` of `SparkSQLExample.scala` on the `programmatic_schema` example to fix the `not found: value Row` error on it. ``` scala> val rowRDD = peopleRDD.map(_.split(",")).map(attributes => Row(attributes(0), attributes(1).trim)) <console>:28: error: not found: value Row val rowRDD = peopleRDD.map(_.split(",")).map(attributes => Row(attributes(0), attributes(1).trim)) ``` ## How was this patch tested? NA Closes apache#23326 from kjmrknsn/fix-sql-getting-started. Authored-by: Keiji Yoshida <kjmrknsn@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> -
Revert "[SPARK-26248][SQL] Infer date type from CSV"
This reverts commit 5217f7b.
-
[SPARK-26352][SQL] join reorder should not change the order of output…
… attributes ## What changes were proposed in this pull request? The optimizer rule `org.apache.spark.sql.catalyst.optimizer.ReorderJoin` performs join reordering on inner joins. This was introduced from SPARK-12032 (apache#10073) in 2015-12. After it had reordered the joins, though, it didn't check whether or not the output attribute order is still the same as before. Thus, it's possible to have a mismatch between the reordered output attributes order vs the schema that a DataFrame thinks it has. The same problem exists in the CBO version of join reordering (`CostBasedJoinReorder`) too. This can be demonstrated with the example: ```scala spark.sql("create table table_a (x int, y int) using parquet") spark.sql("create table table_b (i int, j int) using parquet") spark.sql("create table table_c (a int, b int) using parquet") val df = spark.sql(""" with df1 as (select * from table_a cross join table_b) select * from df1 join table_c on a = x and b = i """) ``` here's what the DataFrame thinks: ``` scala> df.printSchema root |-- x: integer (nullable = true) |-- y: integer (nullable = true) |-- i: integer (nullable = true) |-- j: integer (nullable = true) |-- a: integer (nullable = true) |-- b: integer (nullable = true) ``` here's what the optimized plan thinks, after join reordering: ``` scala> df.queryExecution.optimizedPlan.output.foreach(a => println(s"|-- ${a.name}: ${a.dataType.typeName}")) |-- x: integer |-- y: integer |-- a: integer |-- b: integer |-- i: integer |-- j: integer ``` If we exclude the `ReorderJoin` rule (using Spark 2.4's optimizer rule exclusion feature), it's back to normal: ``` scala> spark.conf.set("spark.sql.optimizer.excludedRules", "org.apache.spark.sql.catalyst.optimizer.ReorderJoin") scala> val df = spark.sql("with df1 as (select * from table_a cross join table_b) select * from df1 join table_c on a = x and b = i") df: org.apache.spark.sql.DataFrame = [x: int, y: int ... 4 more fields] scala> df.queryExecution.optimizedPlan.output.foreach(a => println(s"|-- ${a.name}: ${a.dataType.typeName}")) |-- x: integer |-- y: integer |-- i: integer |-- j: integer |-- a: integer |-- b: integer ``` Note that this output attribute ordering problem leads to data corruption, and can manifest itself in various symptoms: * Silently corrupting data, if the reordered columns happen to either have matching types or have sufficiently-compatible types (e.g. all fixed length primitive types are considered as "sufficiently compatible" in an `UnsafeRow`), then only the resulting data is going to be wrong but it might not trigger any alarms immediately. Or * Weird Java-level exceptions like `java.lang.NegativeArraySizeException`, or even SIGSEGVs. ## How was this patch tested? Added new unit test in `JoinReorderSuite` and new end-to-end test in `JoinSuite`. Also made `JoinReorderSuite` and `StarJoinReorderSuite` assert more strongly on maintaining output attribute order. Closes apache#23303 from rednaxelafx/fix-join-reorder. Authored-by: Kris Mok <rednaxelafx@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
-
[SPARK-26327][SQL][FOLLOW-UP] Refactor the code and restore the metri…
…cs name ## What changes were proposed in this pull request? - The original comment about `updateDriverMetrics` is not right. - Refactor the code to ensure `selectedPartitions ` has been set before sending the driver-side metrics. - Restore the original name, which is more general and extendable. ## How was this patch tested? The existing tests. Closes apache#23328 from gatorsmile/followupSpark-26142. Authored-by: gatorsmile <gatorsmile@gmail.com> Signed-off-by: gatorsmile <gatorsmile@gmail.com>
-
[SPARK-20636] Add the rule TransposeWindow to the optimization batch
## What changes were proposed in this pull request? This PR is a follow-up of the PR apache#17899. It is to add the rule TransposeWindow the optimizer batch. ## How was this patch tested? The existing tests. Closes apache#23222 from gatorsmile/followupSPARK-20636. Authored-by: gatorsmile <gatorsmile@gmail.com> Signed-off-by: gatorsmile <gatorsmile@gmail.com>
-
[SPARK-26243][SQL][FOLLOWUP] fix code style issues in TimestampFormat…
…ter.scala ## What changes were proposed in this pull request? 1. rename `FormatterUtils` to `DateTimeFormatterHelper`, and move it to a separated file 2. move `DateFormatter` and its implementation to a separated file 3. mark some methods as private 4. add `override` to some methods ## How was this patch tested? existing tests Closes apache#23329 from cloud-fan/minor. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[SPARK-20351][ML] Add trait hasTrainingSummary to replace the duplica…
…te code ## What changes were proposed in this pull request? Add a trait HasTrainingSummary to avoid code duplicate related to training summary. Currently all the training summary use the similar pattern which can be generalized, ``` private[ml] final var trainingSummary: Option[T] = None def hasSummary: Boolean = trainingSummary.isDefined def summary: T = trainingSummary.getOrElse... private[ml] def setSummary(summary: Option[T]): ... ``` Classes with the trait need to override `setSummry`. And for Java compatibility, they will also have to override `summary` method, otherwise the java code will regard all the summary class as Object due to a known issue with Scala. ## How was this patch tested? existing Java and Scala unit tests Closes apache#17654 from hhbyyh/hassummary. Authored-by: Yuhao Yang <yuhao.yang@intel.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[SPARK-26255][YARN] Apply user provided UI filters to SQL tab in yarn…
… mode ## What changes were proposed in this pull request? User specified filters are not applied to SQL tab in yarn mode, as it is overridden by the yarn AmIp filter. So we need to append user provided filters (spark.ui.filters) with yarn filter. ## How was this patch tested? 【Test step】: 1) Launch spark sql with authentication filter as below: 2) spark-sql --master yarn --conf spark.ui.filters=org.apache.hadoop.security.authentication.server.AuthenticationFilter --conf spark.org.apache.hadoop.security.authentication.server.AuthenticationFilter.params="type=simple" 3) Go to Yarn application list UI link 4) Launch the application master for the Spark-SQL app ID and access all the tabs by appending tab name. 5) It will display an error for all tabs including SQL tab.(before able to access SQL tab,as Authentication filter is not applied for SQL tab) 6) Also can be verified with info logs,that Authentication filter applied to SQL tab.(before it is not applied). I have attached the behaviour below in following order.. 1) Command used 2) Before fix (logs and UI) 3) After fix (logs and UI) **1) COMMAND USED**: launching spark-sql with authentication filter.  **2) BEFORE FIX:** **UI result:** able to access SQL tab.  **logs**: authentication filter not applied to SQL tab.  **3) AFTER FIX:** **UI result**: Not able to access SQL tab.  **in logs**: Both yarn filter and Authentication filter applied to SQL tab.  Closes apache#23312 from chakravarthiT/SPARK-26255_ui. Authored-by: chakravarthi <tcchakra@gmail.com> Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
-
[SPARK-26371][SS] Increase kafka ConfigUpdater test coverage.
## What changes were proposed in this pull request? As Kafka delegation token added logic into ConfigUpdater it would be good to test it. This PR contains the following changes: * ConfigUpdater extracted to a separate file and renamed to KafkaConfigUpdater * mockito-core dependency added to kafka-0-10-sql * Unit tests added ## How was this patch tested? Existing + new unit tests + on cluster. Closes apache#23321 from gaborgsomogyi/SPARK-26371. Authored-by: Gabor Somogyi <gabor.g.somogyi@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
-
[SPARK-24933][SS] Report numOutputRows in SinkProgress
## What changes were proposed in this pull request? SinkProgress should report similar properties like SourceProgress as long as they are available for given Sink. Count of written rows is metric availble for all Sinks. Since relevant progress information is with respect to commited rows, ideal object to carry this info is WriterCommitMessage. For brevity the implementation will focus only on Sinks with API V2 and on Micro Batch mode. Implemention for Continuous mode will be provided at later date. ### Before ``` {"description":"org.apache.spark.sql.kafka010.KafkaSourceProvider3c0bd317"} ``` ### After ``` {"description":"org.apache.spark.sql.kafka010.KafkaSourceProvider3c0bd317","numOutputRows":5000} ``` ### This PR is related to: - https://issues.apache.org/jira/browse/SPARK-24647 - https://issues.apache.org/jira/browse/SPARK-21313 ## How was this patch tested? Existing and new unit tests. Please review http://spark.apache.org/contributing.html before opening a pull request. Closes apache#21919 from vackosar/feature/SPARK-24933-numOutputRows. Lead-authored-by: Vaclav Kosar <admin@vaclavkosar.com> Co-authored-by: Kosar, Vaclav: Functions Transformation <Vaclav.Kosar@barclayscapital.com> Signed-off-by: gatorsmile <gatorsmile@gmail.com> -
[SPARK-25922][K8] Spark Driver/Executor "spark-app-selector" label mi…
…smatch ## What changes were proposed in this pull request? In K8S Cluster mode, the algorithm to generate spark-app-selector/spark.app.id of spark driver is different with spark executor. This patch makes sure spark driver and executor to use the same spark-app-selector/spark.app.id if spark.app.id is set, otherwise it will use superclass applicationId. In K8S Client mode, spark-app-selector/spark.app.id for executors will use superclass applicationId. ## How was this patch tested? Manually run." Closes apache#23322 from suxingfate/SPARK-25922. Lead-authored-by: suxingfate <suxingfate@163.com> Co-authored-by: xinglwang <xinglwang@ebay.com> Signed-off-by: Yinan Li <ynli@google.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Commits on Dec 18, 2018
-
[SPARK-24561][SQL][PYTHON] User-defined window aggregation functions …
…with Pandas UDF (bounded window) ## What changes were proposed in this pull request? This PR implements a new feature - window aggregation Pandas UDF for bounded window. #### Doc: https://docs.google.com/document/d/14EjeY5z4-NC27-SmIP9CsMPCANeTcvxN44a7SIJtZPc/edit#heading=h.c87w44wcj3wj #### Example: ``` from pyspark.sql.functions import pandas_udf, PandasUDFType from pyspark.sql.window import Window df = spark.range(0, 10, 2).toDF('v') w1 = Window.partitionBy().orderBy('v').rangeBetween(-2, 4) w2 = Window.partitionBy().orderBy('v').rowsBetween(-2, 2) pandas_udf('double', PandasUDFType.GROUPED_AGG) def avg(v): return v.mean() df.withColumn('v_mean', avg(df['v']).over(w1)).show() # +---+------+ # | v|v_mean| # +---+------+ # | 0| 1.0| # | 2| 2.0| # | 4| 4.0| # | 6| 6.0| # | 8| 7.0| # +---+------+ df.withColumn('v_mean', avg(df['v']).over(w2)).show() # +---+------+ # | v|v_mean| # +---+------+ # | 0| 2.0| # | 2| 3.0| # | 4| 4.0| # | 6| 5.0| # | 8| 6.0| # +---+------+ ``` #### High level changes: This PR modifies the existing WindowInPandasExec physical node to deal with unbounded (growing, shrinking and sliding) windows. * `WindowInPandasExec` now share the same base class as `WindowExec` and share utility functions. See `WindowExecBase` * `WindowFunctionFrame` now has two new functions `currentLowerBound` and `currentUpperBound` - to return the lower and upper window bound for the current output row. It is also modified to allow `AggregateProcessor` == null. Null aggregator processor is used for `WindowInPandasExec` where we don't have an aggregator and only uses lower and upper bound functions from `WindowFunctionFrame` * The biggest change is in `WindowInPandasExec`, where it is modified to take `currentLowerBound` and `currentUpperBound` and write those values together with the input data to the python process for rolling window aggregation. See `WindowInPandasExec` for more details. #### Discussion In benchmarking, I found numpy variant of the rolling window UDF is much faster than the pandas version: Spark SQL window function: 20s Pandas variant: ~80s Numpy variant: 10s Numpy variant with numba: 4s Allowing numpy variant of the vectorized UDFs is something I want to discuss because of the performance improvement, but doesn't have to be in this PR. ## How was this patch tested? New tests Closes apache#22305 from icexelloss/SPARK-24561-bounded-window-udf. Authored-by: Li Jin <ice.xelloss@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[SPARK-26246][SQL] Inferring TimestampType from JSON
## What changes were proposed in this pull request? The `JsonInferSchema` class is extended to support `TimestampType` inferring from string fields in JSON input: - If the `prefersDecimal` option is set to `true`, it tries to infer decimal type from the string field. - If decimal type inference fails or `prefersDecimal` is disabled, `JsonInferSchema` tries to infer `TimestampType`. - If timestamp type inference fails, `StringType` is returned as the inferred type. ## How was this patch tested? Added new test suite - `JsonInferSchemaSuite` to check date and timestamp types inferring from JSON using `JsonInferSchema` directly. A few tests were added `JsonSuite` to check type merging and roundtrip tests. This changes was tested by `JsonSuite`, `JsonExpressionsSuite` and `JsonFunctionsSuite` as well. Closes apache#23201 from MaxGekk/json-infer-time. Lead-authored-by: Maxim Gekk <maxim.gekk@databricks.com> Co-authored-by: Maxim Gekk <max.gekk@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[SPARK-26081][SQL][FOLLOW-UP] Use foreach instead of misuse of map (f…
…or Unit) ## What changes were proposed in this pull request? This PR proposes to use foreach instead of misuse of map (for Unit). This could cause some weird errors potentially and it's not a good practice anyway. See also SPARK-16694 ## How was this patch tested? N/A Closes apache#23341 from HyukjinKwon/followup-SPARK-26081. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[SPARK-24680][DEPLOY] Support spark.executorEnv.JAVA_HOME in Standalo…
…ne mode ## What changes were proposed in this pull request? spark.executorEnv.JAVA_HOME does not take effect when a Worker starting an Executor process in Standalone mode. This PR fixed this. ## How was this patch tested? Manual tests. Closes apache#21663 from stanzhai/fix-executor-env-java-home. Lead-authored-by: Stan Zhai <zhaishidan@haizhi.com> Co-authored-by: Stan Zhai <mail@stanzhai.site> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[SPARK-26384][SQL] Propagate SQL configs for CSV schema inferring
## What changes were proposed in this pull request? Currently, SQL configs are not propagated to executors while schema inferring in CSV datasource. For example, changing of `spark.sql.legacy.timeParser.enabled` does not impact on inferring timestamp types. In the PR, I propose to fix the issue by wrapping schema inferring action using `SQLExecution.withSQLConfPropagated`. ## How was this patch tested? Added logging to `TimestampFormatter`: ```patch -object TimestampFormatter { +object TimestampFormatter extends Logging { def apply(format: String, timeZone: TimeZone, locale: Locale): TimestampFormatter = { if (SQLConf.get.legacyTimeParserEnabled) { + logError("LegacyFallbackTimestampFormatter is being used") new LegacyFallbackTimestampFormatter(format, timeZone, locale) } else { + logError("Iso8601TimestampFormatter is being used") new Iso8601TimestampFormatter(format, timeZone, locale) } } ``` and run the command in `spark-shell`: ```shell $ ./bin/spark-shell --conf spark.sql.legacy.timeParser.enabled=true ``` ```scala scala> Seq("2010|10|10").toDF.repartition(1).write.mode("overwrite").text("/tmp/foo") scala> spark.read.option("inferSchema", "true").option("header", "false").option("timestampFormat", "yyyy|MM|dd").csv("/tmp/foo").printSchema() 18/12/18 10:47:27 ERROR TimestampFormatter: LegacyFallbackTimestampFormatter is being used root |-- _c0: timestamp (nullable = true) ``` Closes apache#23345 from MaxGekk/csv-schema-infer-propagate-configs. Authored-by: Maxim Gekk <maxim.gekk@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> -
[SPARK-26382][CORE] prefix comparator should handle -0.0
## What changes were proposed in this pull request? This is kind of a followup of apache#23239 The `UnsafeProject` will normalize special float/double values(NaN and -0.0), so the sorter doesn't have to handle it. However, for consistency and future-proof, this PR proposes to normalize `-0.0` in the prefix comparator, so that it's same with the normal ordering. Note that prefix comparator handles NaN as well. This is not a bug fix, but a safe guard. ## How was this patch tested? existing tests Closes apache#23334 from cloud-fan/sort. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
-
[SPARK-26394][CORE] Fix annotation error for Utils.timeStringAsMs
## What changes were proposed in this pull request? Change microseconds to milliseconds in annotation of Utils.timeStringAsMs. Closes apache#23346 from stczwd/stczwd. Authored-by: Jackey Lee <qcsd2011@163.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
Commits on Dec 19, 2018
-
[SPARK-26366][SQL] ReplaceExceptWithFilter should consider NULL as False
## What changes were proposed in this pull request? In `ReplaceExceptWithFilter` we do not consider properly the case in which the condition returns NULL. Indeed, in that case, since negating NULL still returns NULL, so it is not true the assumption that negating the condition returns all the rows which didn't satisfy it, rows returning NULL may not be returned. This happens when constraints inferred by `InferFiltersFromConstraints` are not enough, as it happens with `OR` conditions. The rule had also problems with non-deterministic conditions: in such a scenario, this rule would change the probability of the output. The PR fixes these problem by: - returning False for the condition when it is Null (in this way we do return all the rows which didn't satisfy it); - avoiding any transformation when the condition is non-deterministic. ## How was this patch tested? added UTs Closes apache#23315 from mgaido91/SPARK-26366. Authored-by: Marco Gaido <marcogaido91@gmail.com> Signed-off-by: gatorsmile <gatorsmile@gmail.com>
-
[SPARK-26390][SQL] ColumnPruning rule should only do column pruning
## What changes were proposed in this pull request? This is a small clean up. By design catalyst rules should be orthogonal: each rule should have its own responsibility. However, the `ColumnPruning` rule does not only do column pruning, but also remove no-op project and window. This PR updates the `RemoveRedundantProject` rule to remove no-op window as well, and clean up the `ColumnPruning` rule to only do column pruning. ## How was this patch tested? existing tests Closes apache#23343 from cloud-fan/column-pruning. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
Commits on Dec 20, 2018
-
[SPARK-26262][SQL] Runs SQLQueryTestSuite on mixed config sets: WHOLE…
…STAGE_CODEGEN_ENABLED and CODEGEN_FACTORY_MODE ## What changes were proposed in this pull request? For better test coverage, this pr proposed to use the 4 mixed config sets of `WHOLESTAGE_CODEGEN_ENABLED` and `CODEGEN_FACTORY_MODE` when running `SQLQueryTestSuite`: 1. WHOLESTAGE_CODEGEN_ENABLED=true, CODEGEN_FACTORY_MODE=CODEGEN_ONLY 2. WHOLESTAGE_CODEGEN_ENABLED=false, CODEGEN_FACTORY_MODE=CODEGEN_ONLY 3. WHOLESTAGE_CODEGEN_ENABLED=true, CODEGEN_FACTORY_MODE=NO_CODEGEN 4. WHOLESTAGE_CODEGEN_ENABLED=false, CODEGEN_FACTORY_MODE=NO_CODEGEN This pr also moved some existing tests into `ExplainSuite` because explain output results are different between codegen and interpreter modes. ## How was this patch tested? Existing tests. Closes apache#23213 from maropu/InterpreterModeTest. Authored-by: Takeshi Yamamuro <yamamuro@apache.org> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
-
[SPARK-25271][SQL] Hive ctas commands should use data source if it is…
… convertible ## What changes were proposed in this pull request? In Spark 2.3.0 and previous versions, Hive CTAS command will convert to use data source to write data into the table when the table is convertible. This behavior is controlled by the configs like HiveUtils.CONVERT_METASTORE_ORC and HiveUtils.CONVERT_METASTORE_PARQUET. In 2.3.1, we drop this optimization by mistake in the PR [SPARK-22977](https://github.com/apache/spark/pull/20521/files#r217254430). Since that Hive CTAS command only uses Hive Serde to write data. This patch adds this optimization back to Hive CTAS command. This patch adds OptimizedCreateHiveTableAsSelectCommand which uses data source to write data. ## How was this patch tested? Added test. Closes apache#22514 from viirya/SPARK-25271-2. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
-
[SPARK-26318][SQL] Deprecate Row.merge
## What changes were proposed in this pull request? Deprecate Row.merge ## How was this patch tested? N/A Closes apache#23271 from KyleLi1985/master. Authored-by: 李亮 <liang.li.work@outlook.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[SPARK-26308][SQL] Avoid cast of decimals for ScalaUDF
## What changes were proposed in this pull request? Currently, when we infer the schema for scala/java decimals, we return as data type the `SYSTEM_DEFAULT` implementation, ie. the decimal type with precision 38 and scale 18. But this is not right, as we know nothing about the right precision and scale and these values can be not enough to store the data. This problem arises in particular with UDF, where we cast all the input of type `DecimalType` to a `DecimalType(38, 18)`: in case this is not enough, null is returned as input for the UDF. The PR defines a custom handling for casting to the expected data types for ScalaUDF: the decimal precision and scale is picked from the input, so no casting to different and maybe wrong percision and scale happens. ## How was this patch tested? added UTs Closes apache#23308 from mgaido91/SPARK-26308. Authored-by: Marco Gaido <marcogaido91@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
-
[SPARK-24687][CORE] Avoid job hanging when generate task binary cause…
…s fatal error ## What changes were proposed in this pull request? When NoClassDefFoundError thrown,it will cause job hang. `Exception in thread "dag-scheduler-event-loop" java.lang.NoClassDefFoundError: Lcom/xxx/data/recommend/aggregator/queue/QueueName; at java.lang.Class.getDeclaredFields0(Native Method) at java.lang.Class.privateGetDeclaredFields(Class.java:2436) at java.lang.Class.getDeclaredField(Class.java:1946) at java.io.ObjectStreamClass.getDeclaredSUID(ObjectStreamClass.java:1659) at java.io.ObjectStreamClass.access$700(ObjectStreamClass.java:72) at java.io.ObjectStreamClass$2.run(ObjectStreamClass.java:480) at java.io.ObjectStreamClass$2.run(ObjectStreamClass.java:468) at java.security.AccessController.doPrivileged(Native Method) at java.io.ObjectStreamClass.<init>(ObjectStreamClass.java:468) at java.io.ObjectStreamClass.lookup(ObjectStreamClass.java:365) at java.io.ObjectOutputStream.writeClass(ObjectOutputStream.java:1212) at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1119) at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1547) at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1508) at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1431) at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177) at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1547) at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1508) at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1431) at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177) at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1547) at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1508) at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1431) at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177) at java.io.ObjectOutputStream.writeArray(ObjectOutputStream.java:1377) at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1173) at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1547) at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1508) at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1431) at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177) at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1547) at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1508) at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1431) at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177) at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1547) at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1508) at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1431) at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177) at java.io.ObjectOutputStream.writeArray(ObjectOutputStream.java:1377)` It is caused by NoClassDefFoundError will not catch up during task seriazation. `var taskBinary: Broadcast[Array[Byte]] = null try { // For ShuffleMapTask, serialize and broadcast (rdd, shuffleDep). // For ResultTask, serialize and broadcast (rdd, func). val taskBinaryBytes: Array[Byte] = stage match { case stage: ShuffleMapStage => JavaUtils.bufferToArray( closureSerializer.serialize((stage.rdd, stage.shuffleDep): AnyRef)) case stage: ResultStage => JavaUtils.bufferToArray(closureSerializer.serialize((stage.rdd, stage.func): AnyRef)) } taskBinary = sc.broadcast(taskBinaryBytes) } catch { // In the case of a failure during serialization, abort the stage. case e: NotSerializableException => abortStage(stage, "Task not serializable: " + e.toString, Some(e)) runningStages -= stage // Abort execution return case NonFatal(e) => abortStage(stage, s"Task serialization failed: $e\n${Utils.exceptionString(e)}", Some(e)) runningStages -= stage return }` image below shows that stage 33 blocked and never be scheduled. <img width="1273" alt="2018-06-28 4 28 42" src="https://user-images.githubusercontent.com/26762018/42621188-b87becca-85ef-11e8-9a0b-0ddf07504c96.png"> <img width="569" alt="2018-06-28 4 28 49" src="https://user-images.githubusercontent.com/26762018/42621191-b8b260e8-85ef-11e8-9d10-e97a5918baa6.png"> ## How was this patch tested? UT Closes apache#21664 from caneGuy/zhoukang/fix-noclassdeferror. Authored-by: zhoukang <zhoukang199191@gmail.com> Signed-off-by: Sean Owen <sean.owen@databricks.com> -
[SPARK-26324][DOCS] Add Spark docs for Running in Mesos with SSL
## What changes were proposed in this pull request? Added docs for running spark jobs with Mesos on SSL Closes apache#23342 from jomach/master. Lead-authored-by: Jorge Machado <jorge.w.machado@hotmail.com> Co-authored-by: Jorge Machado <dxc.machado@extaccount.com> Co-authored-by: Jorge Machado <jorge.machado.ext@kiwigrid.com> Co-authored-by: Jorge Machado <JorgeWilson.Machado@ext.gfk.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[SPARK-26409][SQL][TESTS] SQLConf should be serializable in test sess…
…ions ## What changes were proposed in this pull request? `SQLConf` is supposed to be serializable. However, currently it is not serializable in `WithTestConf`. `WithTestConf` uses the method `overrideConfs` in closure, while the classes which implements it (`TestHiveSessionStateBuilder` and `TestSQLSessionStateBuilder`) are not serializable. This PR is to use a local variable to fix it. ## How was this patch tested? Add unit test. Closes apache#23352 from gengliangwang/serializableSQLConf. Authored-by: Gengliang Wang <gengliang.wang@databricks.com> Signed-off-by: gatorsmile <gatorsmile@gmail.com>
-
[SPARK-26392][YARN] Cancel pending allocate requests by taking locali…
…ty preference into account ## What changes were proposed in this pull request? Right now, we cancel pending allocate requests by its sending order. I thing we can take locality preference into account when do this to perfom least impact on task locality preference. ## How was this patch tested? N.A. Closes apache#23344 from Ngone51/dev-cancel-pending-allocate-requests-by-taking-locality-preference-into-account. Authored-by: Ngone51 <ngone_5451@163.com> Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
-
[SPARK-25970][ML] Add Instrumentation to PrefixSpan
## What changes were proposed in this pull request? Add Instrumentation to PrefixSpan ## How was this patch tested? existing tests Closes apache#22971 from zhengruifeng/log_PrefixSpan. Authored-by: zhengruifeng <ruifengz@foxmail.com> Signed-off-by: Xiangrui Meng <meng@databricks.com>
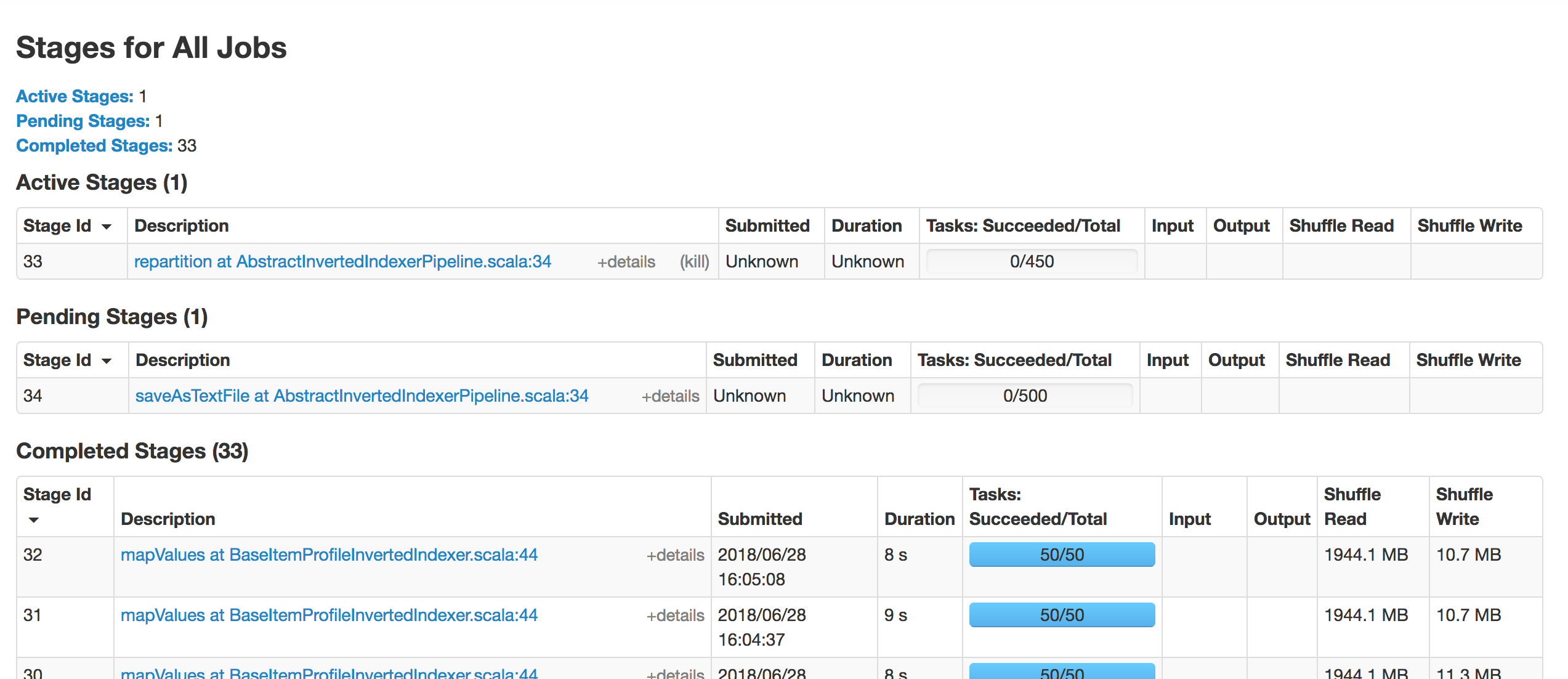{kind=link}
{kind=link}
Commits on Dec 21, 2018
-
[MINOR][SQL] Locality does not need to be implemented
## What changes were proposed in this pull request? `HadoopFileWholeTextReader` and `HadoopFileLinesReader` will be eventually called in `FileSourceScanExec`. In fact, locality has been implemented in `FileScanRDD`, even if we implement it in `HadoopFileWholeTextReader ` and `HadoopFileLinesReader`, it would be useless. So I think these `TODO` can be removed. ## How was this patch tested? N/A Closes apache#23339 from 10110346/noneededtodo. Authored-by: liuxian <liu.xian3@zte.com.cn> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
-
[SPARK-26422][R] Support to disable Hive support in SparkR even for H…
…adoop versions unsupported by Hive fork ## What changes were proposed in this pull request? Currently, even if I explicitly disable Hive support in SparkR session as below: ```r sparkSession <- sparkR.session("local[4]", "SparkR", Sys.getenv("SPARK_HOME"), enableHiveSupport = FALSE) ``` produces when the Hadoop version is not supported by our Hive fork: ``` java.lang.reflect.InvocationTargetException ... Caused by: java.lang.IllegalArgumentException: Unrecognized Hadoop major version number: 3.1.1.3.1.0.0-78 at org.apache.hadoop.hive.shims.ShimLoader.getMajorVersion(ShimLoader.java:174) at org.apache.hadoop.hive.shims.ShimLoader.loadShims(ShimLoader.java:139) at org.apache.hadoop.hive.shims.ShimLoader.getHadoopShims(ShimLoader.java:100) at org.apache.hadoop.hive.conf.HiveConf$ConfVars.<clinit>(HiveConf.java:368) ... 43 more Error in handleErrors(returnStatus, conn) : java.lang.ExceptionInInitializerError at org.apache.hadoop.hive.conf.HiveConf.<clinit>(HiveConf.java:105) at java.lang.Class.forName0(Native Method) at java.lang.Class.forName(Class.java:348) at org.apache.spark.util.Utils$.classForName(Utils.scala:193) at org.apache.spark.sql.SparkSession$.hiveClassesArePresent(SparkSession.scala:1116) at org.apache.spark.sql.api.r.SQLUtils$.getOrCreateSparkSession(SQLUtils.scala:52) at org.apache.spark.sql.api.r.SQLUtils.getOrCreateSparkSession(SQLUtils.scala) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ``` The root cause is that: ``` SparkSession.hiveClassesArePresent ``` check if the class is loadable or not to check if that's in classpath but `org.apache.hadoop.hive.conf.HiveConf` has a check for Hadoop version as static logic which is executed right away. This throws an `IllegalArgumentException` and that's not caught: https://github.com/apache/spark/blob/36edbac1c8337a4719f90e4abd58d38738b2e1fb/sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala#L1113-L1121 So, currently, if users have a Hive built-in Spark with unsupported Hadoop version by our fork (namely 3+), there's no way to use SparkR even though it could work. This PR just propose to change the order of bool comparison so that we can don't execute `SparkSession.hiveClassesArePresent` when: 1. `enableHiveSupport` is explicitly disabled 2. `spark.sql.catalogImplementation` is `in-memory` so that we **only** check `SparkSession.hiveClassesArePresent` when Hive support is explicitly enabled by short circuiting. ## How was this patch tested? It's difficult to write a test since we don't run tests against Hadoop 3 yet. See apache#21588. Manually tested. Closes apache#23356 from HyukjinKwon/SPARK-26422. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> -
[SPARK-26267][SS] Retry when detecting incorrect offsets from Kafka
## What changes were proposed in this pull request? Due to [KAFKA-7703](https://issues.apache.org/jira/browse/KAFKA-7703), Kafka may return an earliest offset when we are request a latest offset. This will cause Spark to reprocess data. As per suggestion in KAFKA-7703, we put a position call between poll and seekToEnd to block the fetch request triggered by `poll` before calling `seekToEnd`. In addition, to avoid other unknown issues, we also use the previous known offsets to audit the latest offsets returned by Kafka. If we find some incorrect offsets (a latest offset is less than an offset in `knownOffsets`), we will retry at most `maxOffsetFetchAttempts` times. ## How was this patch tested? Jenkins Closes apache#23324 from zsxwing/SPARK-26267. Authored-by: Shixiong Zhu <zsxwing@gmail.com> Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
-
[SPARK-26269][YARN] Yarnallocator should have same blacklist behaviou…
…r with yarn to maxmize use of cluster resource ## What changes were proposed in this pull request? As I mentioned in jira [SPARK-26269](https://issues.apache.org/jira/browse/SPARK-26269), in order to maxmize the use of cluster resource, this pr try to make `YarnAllocator` have the same blacklist behaviour with YARN. ## How was this patch tested? Added. Closes apache#23223 from Ngone51/dev-YarnAllocator-should-have-same-blacklist-behaviour-with-YARN. Lead-authored-by: wuyi <ngone_5451@163.com> Co-authored-by: Ngone51 <ngone_5451@163.com> Signed-off-by: Thomas Graves <tgraves@apache.org>
Commits on Dec 22, 2018
-
[SPARK-26216][SQL][FOLLOWUP] use abstract class instead of trait for …
…UserDefinedFunction ## What changes were proposed in this pull request? A followup of apache#23178 , to keep binary compability by using abstract class. ## How was this patch tested? Manual test. I created a simple app with Spark 2.4 ``` object TryUDF { def main(args: Array[String]): Unit = { val spark = SparkSession.builder().appName("test").master("local[*]").getOrCreate() import spark.implicits._ val f1 = udf((i: Int) => i + 1) println(f1.deterministic) spark.range(10).select(f1.asNonNullable().apply($"id")).show() spark.stop() } } ``` When I run it with current master, it fails with ``` java.lang.IncompatibleClassChangeError: Found interface org.apache.spark.sql.expressions.UserDefinedFunction, but class was expected ``` When I run it with this PR, it works Closes apache#23351 from cloud-fan/minor. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
-
[SPARK-26427][BUILD] Upgrade Apache ORC to 1.5.4
## What changes were proposed in this pull request? This PR aims to update Apache ORC dependency to the latest version 1.5.4 released at Dec. 20. ([Release Notes](https://issues.apache.org/jira/secure/ReleaseNote.jspa?projectId=12318320&version=12344187])) ``` [ORC-237] OrcFile.mergeFiles Specified block size is less than configured minimum value [ORC-409] Changes for extending MemoryManagerImpl [ORC-410] Fix a locale-dependent test in TestCsvReader [ORC-416] Avoid opening data reader when there is no stripe [ORC-417] Use dynamic Apache Maven mirror link [ORC-419] Ensure to call `close` at RecordReaderImpl constructor exception [ORC-432] openjdk 8 has a bug that prevents surefire from working [ORC-435] Ability to read stripes that are greater than 2GB [ORC-437] Make acid schema checks case insensitive [ORC-411] Update build to work with Java 10. [ORC-418] Fix broken docker build script ``` ## How was this patch tested? Build and pass Jenkins. Closes apache#23364 from dongjoon-hyun/SPARK-26427. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
-
[SPARK-26428][SS][TEST] Minimize deprecated
ProcessingTimeusage## What changes were proposed in this pull request? Use of `ProcessingTime` class was deprecated in favor of `Trigger.ProcessingTime` in Spark 2.2. And, [SPARK-21464](https://issues.apache.org/jira/browse/SPARK-21464) minimized it at 2.2.1. Recently, it grows again in test suites. This PR aims to clean up newly introduced deprecation warnings for Spark 3.0. ## How was this patch tested? Pass the Jenkins with existing tests and manually check the warnings. Closes apache#23367 from dongjoon-hyun/SPARK-26428. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
-
[SPARK-26430][BUILD][TEST-MAVEN] Upgrade Surefire plugin to 3.0.0-M2
## What changes were proposed in this pull request? This PR aims to upgrade Maven Surefile plugin for JDK11 support. 3.0.0-M2 is [released Dec. 9th.](https://issues.apache.org/jira/projects/SUREFIRE/versions/12344396) ``` [SUREFIRE-1568] Versions 2.21 and higher doesn't work with junit-platform for Java 9 module [SUREFIRE-1605] NoClassDefFoundError (RunNotifier) with JDK 11 [SUREFIRE-1600] Surefire Project using surefire:2.12.4 is not fully able to work with JDK 10+ on internal build system. Therefore surefire-shadefire should go with Surefire:3.0.0-M2. [SUREFIRE-1593] 3.0.0-M1 produces invalid code sources on Windows [SUREFIRE-1602] Surefire fails loading class ForkedBooter when using a sub-directory pom file and a local maven repo [SUREFIRE-1606] maven-shared-utils must not be on provider's classpath [SUREFIRE-1531] Option to switch-off Java 9 modules [SUREFIRE-1590] Deploy multiple versions of Report XSD [SUREFIRE-1591] Java 1.7 feature Diamonds replaced Generics [SUREFIRE-1594] Java 1.7 feature try-catch - multiple exceptions in one catch [SUREFIRE-1595] Java 1.7 feature System.lineSeparator() [SUREFIRE-1597] ModularClasspathForkConfiguration with debug logs (args file and its path on file system) [SUREFIRE-1596] Unnecessary check JAVA_RECENT == JAVA_1_7 in unit tests [SUREFIRE-1598] Fixed typo in assertion statement in integration test Surefire855AllowFailsafeUseArtifactFileIT [SUREFIRE-1607] Roadmap on Project Site ``` ## How was this patch tested? Pass the Jenkins. Closes apache#23370 from dongjoon-hyun/SPARK-26430. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
-
[SPARK-26285][CORE] accumulator metrics sources for LongAccumulator a…
…nd Doub… …leAccumulator ## What changes were proposed in this pull request? This PR implements metric sources for LongAccumulator and DoubleAccumulator, such that a user can register these accumulators easily and have their values be reported by the driver's metric namespace. ## How was this patch tested? Unit tests, and manual tests. Please review http://spark.apache.org/contributing.html before opening a pull request. Closes apache#23242 from abellina/SPARK-26285_accumulator_source. Lead-authored-by: Alessandro Bellina <abellina@yahoo-inc.com> Co-authored-by: Alessandro Bellina <abellina@oath.com> Co-authored-by: Alessandro Bellina <abellina@gmail.com> Signed-off-by: Thomas Graves <tgraves@apache.org>
-
[SPARK-25245][DOCS][SS] Explain regarding limiting modification on "s…
…park.sql.shuffle.partitions" for structured streaming ## What changes were proposed in this pull request? This patch adds explanation of `why "spark.sql.shuffle.partitions" keeps unchanged in structured streaming`, which couple of users already wondered and some of them even thought it as a bug. This patch would help other end users to know about such behavior before they find by theirselves and being wondered. ## How was this patch tested? No need to test because this is a simple addition on guide doc with markdown editor. Closes apache#22238 from HeartSaVioR/SPARK-25245. Lead-authored-by: Jungtaek Lim <kabhwan@gmail.com> Co-authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[SPARK-26402][SQL] Accessing nested fields with different cases in ca…
…se insensitive mode ## What changes were proposed in this pull request? GetStructField with different optional names should be semantically equal. We will use this as building block to compare the nested fields used in the plans to be optimized by catalyst optimizer. This PR also fixes a bug below that accessing nested fields with different cases in case insensitive mode will result `AnalysisException`. ``` sql("create table t (s struct<i: Int>) using json") sql("select s.I from t group by s.i") ``` which is currently failing ``` org.apache.spark.sql.AnalysisException: expression 'default.t.`s`' is neither present in the group by, nor is it an aggregate function ``` as cloud-fan pointed out. ## How was this patch tested? New tests are added. Closes apache#23353 from dbtsai/nestedEqual. Lead-authored-by: DB Tsai <d_tsai@apple.com> Co-authored-by: DB Tsai <dbtsai@dbtsai.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
Commits on Dec 24, 2018
-
[SPARK-26178][SPARK-26243][SQL][FOLLOWUP] Replacing SimpleDateFormat …
…by DateTimeFormatter in comments ## What changes were proposed in this pull request? The PRs apache#23150 and apache#23196 switched JSON and CSV datasources on new formatter for dates/timestamps which is based on `DateTimeFormatter`. In this PR, I replaced `SimpleDateFormat` by `DateTimeFormatter` to reflect the changes. Closes apache#23374 from MaxGekk/java-time-docs. Authored-by: Maxim Gekk <max.gekk@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[SPARK-14023][CORE][SQL] Don't reference 'field' in StructField error…
…s for clarity in exceptions ## What changes were proposed in this pull request? Variation of apache#20500 I cheated by not referencing fields or columns at all as this exception propagates in contexts where both would be applicable. ## How was this patch tested? Existing tests Closes apache#23373 from srowen/SPARK-14023.2. Authored-by: Sean Owen <sean.owen@databricks.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
Commits on Dec 25, 2018
-
[SPARK-26426][SQL] fix ExpresionInfo assert error in windows operatio…
…n system. ## What changes were proposed in this pull request? fix ExpresionInfo assert error in windows operation system, when running unit tests. ## How was this patch tested? unit tests Closes apache#23363 from yanlin-Lynn/unit-test-windows. Authored-by: wangyanlin01 <wangyanlin01@baidu.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
Commits on Dec 27, 2018
-
[SPARK-26424][SQL] Use java.time API in date/timestamp expressions
## What changes were proposed in this pull request? In the PR, I propose to switch the `DateFormatClass`, `ToUnixTimestamp`, `FromUnixTime`, `UnixTime` on java.time API for parsing/formatting dates and timestamps. The API has been already implemented by the `Timestamp`/`DateFormatter` classes. One of benefit is those classes support parsing timestamps with microsecond precision. Old behaviour can be switched on via SQL config: `spark.sql.legacy.timeParser.enabled` (`false` by default). ## How was this patch tested? It was tested by existing test suites - `DateFunctionsSuite`, `DateExpressionsSuite`, `JsonSuite`, `CsvSuite`, `SQLQueryTestSuite` as well as PySpark tests. Closes apache#23358 from MaxGekk/new-time-cast. Lead-authored-by: Maxim Gekk <maxim.gekk@databricks.com> Co-authored-by: Maxim Gekk <max.gekk@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
-
[SPARK-26435][SQL] Support creating partitioned table using Hive CTAS…
… by specifying partition column names ## What changes were proposed in this pull request? Spark SQL doesn't support creating partitioned table using Hive CTAS in SQL syntax. However it is supported by using DataFrameWriter API. ```scala val df = Seq(("a", 1)).toDF("part", "id") df.write.format("hive").partitionBy("part").saveAsTable("t") ``` Hive begins to support this syntax in newer version: https://issues.apache.org/jira/browse/HIVE-20241: ``` CREATE TABLE t PARTITIONED BY (part) AS SELECT 1 as id, "a" as part ``` This patch adds this support to SQL syntax. ## How was this patch tested? Added tests. Closes apache#23376 from viirya/hive-ctas-partitioned-table. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> -
[SPARK-26191][SQL] Control truncation of Spark plans via maxFields pa…
…rameter ## What changes were proposed in this pull request? In the PR, I propose to add `maxFields` parameter to all functions involved in creation of textual representation of spark plans such as `simpleString` and `verboseString`. New parameter restricts number of fields converted to truncated strings. Any elements beyond the limit will be dropped and replaced by a `"... N more fields"` placeholder. The threshold is bumped up to `Int.MaxValue` for `toFile()`. ## How was this patch tested? Added a test to `QueryExecutionSuite` which checks `maxFields` impacts on number of truncated fields in `LocalRelation`. Closes apache#23159 from MaxGekk/to-file-max-fields. Lead-authored-by: Maxim Gekk <max.gekk@gmail.com> Co-authored-by: Maxim Gekk <maxim.gekk@databricks.com> Signed-off-by: Herman van Hovell <hvanhovell@databricks.com>
-
[SPARK-25892][SQL] Change AttributeReference.withMetadata's return ty…
…pe to AttributeReference ## What changes were proposed in this pull request? Currently the `AttributeReference.withMetadata` method have return type `Attribute`, the rest of with methods in the `AttributeReference` return type are `AttributeReference`, as the [spark-25892](https://issues.apache.org/jira/browse/SPARK-25892?jql=project%20%3D%20SPARK%20AND%20component%20in%20(ML%2C%20PySpark%2C%20SQL)) mentioned. This PR will change `AttributeReference.withMetadata` method's return type from `Attribute` to `AttributeReference`. ## How was this patch tested? Run all `sql/test,` `catalyst/test` and `org.apache.spark.sql.execution.streaming.*` Closes apache#22918 from kevinyu98/spark-25892. Authored-by: Kevin Yu <qyu@us.ibm.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[SPARK-26451][SQL] Change lead/lag argument name from count to offset
## What changes were proposed in this pull request? Change aligns argument name with that in Scala version and documentation. ## How was this patch tested? (Please explain how this patch was tested. E.g. unit tests, integration tests, manual tests) (If this patch involves UI changes, please attach a screenshot; otherwise, remove this) Please review http://spark.apache.org/contributing.html before opening a pull request. Closes apache#23357 from deepyaman/patch-1. Authored-by: deepyaman <deepyaman.datta@utexas.edu> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
Commits on Dec 28, 2018
-
[SPARK-26446][CORE] Add cachedExecutorIdleTimeout docs at ExecutorAll…
…ocationManager ## What changes were proposed in this pull request? Add docs to describe how remove policy act while considering the property `spark.dynamicAllocation.cachedExecutorIdleTimeout` in ExecutorAllocationManager ## How was this patch tested? comment-only PR. Closes apache#23386 from TopGunViper/SPARK-26446. Authored-by: wuqingxin <wuqingxin@baidu.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
-
[SPARK-26444][WEBUI] Stage color doesn't change with it's status
## What changes were proposed in this pull request? On job page, in event timeline section, stage color doesn't change according to its status. Below are some screenshots. ACTIVE: <img width="550" alt="active" src="https://user-images.githubusercontent.com/12194089/50438844-c763e580-092a-11e9-84f6-6fc30e08d69b.png"> COMPLETE: <img width="516" alt="complete" src="https://user-images.githubusercontent.com/12194089/50438847-ca5ed600-092a-11e9-9d2e-5d79807bc1ce.png"> FAILED: <img width="325" alt="failed" src="https://user-images.githubusercontent.com/12194089/50438852-ccc13000-092a-11e9-9b6b-782b96b283b1.png"> This PR lets stage color change with it's status. The main idea is to make css style class name match the corresponding stage status. ## How was this patch tested? Manually tested locally. ``` // active/complete stage sc.parallelize(1 to 3, 3).map { n => Thread.sleep(10* 1000); n }.count // failed stage sc.parallelize(1 to 3, 3).map { n => Thread.sleep(10* 1000); throw new Exception() }.count ``` Note we need to clear browser cache to let new `timeline-view.css` take effect. Below are screenshots after this PR. ACTIVE: <img width="569" alt="active-after" src="https://user-images.githubusercontent.com/12194089/50439986-08f68f80-092f-11e9-85d9-be1c31aed13b.png"> COMPLETE: <img width="567" alt="complete-after" src="https://user-images.githubusercontent.com/12194089/50439990-0bf18000-092f-11e9-8624-723958906e90.png"> FAILED: <img width="352" alt="failed-after" src="https://user-images.githubusercontent.com/12194089/50439993-101d9d80-092f-11e9-8dfd-3e20536f2fa5.png"> Closes apache#23385 from seancxmao/timeline-stage-color. Authored-by: seancxmao <seancxmao@gmail.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[SPARK-26424][SQL][FOLLOWUP] Fix DateFormatClass/UnixTime codegen
## What changes were proposed in this pull request? This PR fixes the codegen bug introduced by apache#23358 . - https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-maven-hadoop-2.7-ubuntu-scala-2.11/158/ ``` Line 44, Column 93: A method named "apply" is not declared in any enclosing class nor any supertype, nor through a static import ``` ## How was this patch tested? Manual. `DateExpressionsSuite` should be passed with Scala-2.11. Closes apache#23394 from dongjoon-hyun/SPARK-26424. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
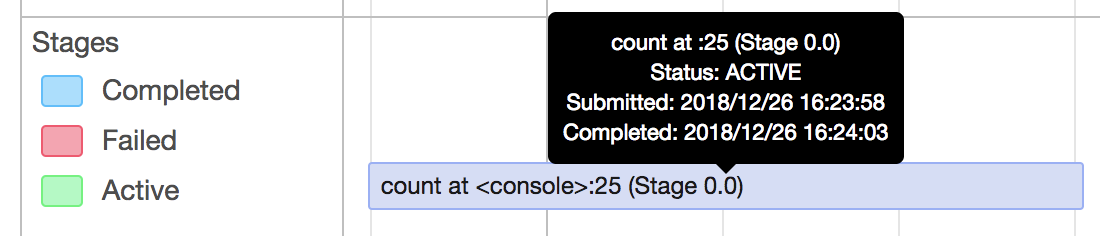{kind=link}
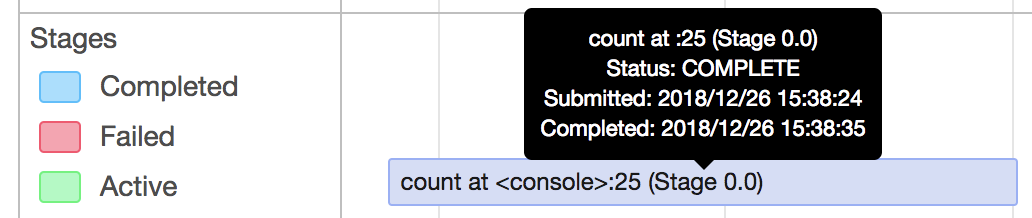{kind=link}
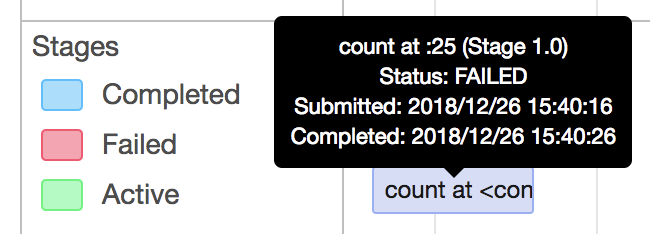{kind=link}
{kind=link}
{kind=link}
{kind=link}
Commits on Dec 29, 2018
-
[SPARK-26496][SS][TEST] Avoid to use Random.nextString in StreamingIn…
…nerJoinSuite ## What changes were proposed in this pull request? Similar with apache#21446. Looks random string is not quite safe as a directory name. ```scala scala> val prefix = Random.nextString(10); val dir = new File("/tmp", "del_" + prefix + "-" + UUID.randomUUID.toString); dir.mkdirs() prefix: String = 窽텘⒘駖ⵚ駢⡞Ρ닋 dir: java.io.File = /tmp/del_窽텘⒘駖ⵚ駢⡞Ρ닋-a3f99855-c429-47a0-a108-47bca6905745 res40: Boolean = false // nope, didn't like this one ``` ## How was this patch tested? Unit test was added, and manually. Closes apache#23405 from HyukjinKwon/SPARK-26496. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
Commits on Dec 30, 2018
-
[SPARK-26443][CORE] Use ConfigEntry for hardcoded configs for history…
… category. ## What changes were proposed in this pull request? This pr makes hardcoded "spark.history" configs to use `ConfigEntry` and put them in `History` config object. ## How was this patch tested? Existing tests. Closes apache#23384 from ueshin/issues/SPARK-26443/hardcoded_history_configs. Authored-by: Takuya UESHIN <ueshin@databricks.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
-
[SPARK-26363][WEBUI] Avoid duplicated KV store lookups in method `tas…
…kList` ## What changes were proposed in this pull request? In the method `taskList`(since apache#21688), the executor log value is queried in KV store for every task(method `constructTaskData`). This PR propose to use a hashmap for reducing duplicated KV store lookups in the method.  ## How was this patch tested? Manual check Closes apache#23310 from gengliangwang/removeExecutorLog. Authored-by: Gengliang Wang <gengliang.wang@databricks.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
{kind=link}
Commits on Dec 31, 2018
-
[SPARK-23375][SQL][FOLLOWUP][TEST] Test Sort metrics while Sort is mi…
…ssing ## What changes were proposed in this pull request? apache#20560/[SPARK-23375](https://issues.apache.org/jira/browse/SPARK-23375) introduced an optimizer rule to eliminate redundant Sort. For a test case named "Sort metrics" in `SQLMetricsSuite`, because range is already sorted, sort is removed by the `RemoveRedundantSorts`, which makes this test case meaningless. This PR modifies the query for testing Sort metrics and checks Sort exists in the plan. ## How was this patch tested? Modify the existing test case. Closes apache#23258 from seancxmao/sort-metrics. Authored-by: seancxmao <seancxmao@gmail.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[SPARK-26504][SQL] Rope-wise dumping of Spark plans
## What changes were proposed in this pull request? Proposed new class `StringConcat` for converting a sequence of strings to string with one memory allocation in the `toString` method. `StringConcat` replaces `StringBuilderWriter` in methods of dumping of Spark plans and codegen to strings. All `Writer` arguments are replaced by `String => Unit` in methods related to Spark plans stringification. ## How was this patch tested? It was tested by existing suites `QueryExecutionSuite`, `DebuggingSuite` as well as new tests for `StringConcat` in `StringUtilsSuite`. Closes apache#23406 from MaxGekk/rope-plan. Authored-by: Maxim Gekk <maxim.gekk@databricks.com> Signed-off-by: Herman van Hovell <hvanhovell@databricks.com>
-
[SPARK-26339][SQL] Throws better exception when reading files that st…
…art with underscore ## What changes were proposed in this pull request? As the description in SPARK-26339, spark.read behavior is very confusing when reading files that start with underscore, fix this by throwing exception which message is "Path does not exist". ## How was this patch tested? manual tests. Both of codes below throws exception which message is "Path does not exist". ``` spark.read.csv("/home/forcia/work/spark/_test.csv") spark.read.schema("test STRING, number INT").csv("/home/forcia/work/spark/_test.csv") ``` Closes apache#23288 from KeiichiHirobe/SPARK-26339. Authored-by: Hirobe Keiichi <keiichi_hirobe@forcia.com> Signed-off-by: Sean Owen <sean.owen@databricks.com> -
[SPARK-26495][SQL] Simplify the SelectedField extractor.
## What changes were proposed in this pull request? The current `SelectedField` extractor is somewhat complicated and it seems to be handling cases that should be handled automatically: - `GetArrayItem(child: GetStructFieldObject())` - `GetArrayStructFields(child: GetArrayStructFields())` - `GetMap(value: GetStructFieldObject())` This PR removes those cases and simplifies the extractor by passing down the data type instead of a field. ## How was this patch tested? Existing tests. Closes apache#23397 from hvanhovell/SPARK-26495. Authored-by: Herman van Hovell <hvanhovell@databricks.com> Signed-off-by: Herman van Hovell <hvanhovell@databricks.com>
-
[SPARK-26470][CORE] Use ConfigEntry for hardcoded configs for eventLo…
…g category ## What changes were proposed in this pull request? The PR makes hardcoded `spark.eventLog` configs to use `ConfigEntry` and put them in the `config` package. ## How was this patch tested? existing tests Closes apache#23395 from mgaido91/SPARK-26470. Authored-by: Marco Gaido <marcogaido91@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
Commits on Jan 1, 2019
-
[MINOR] Fix inconsistency log level among delegation token providers
## What changes were proposed in this pull request? There's some inconsistency for log level while logging error messages in delegation token providers. (DEBUG, INFO, WARNING) Given that failing to obtain token would often crash the query, I guess it would be nice to set higher log level for error log messages. ## How was this patch tested? The patch just changed the log level. Closes apache#23418 from HeartSaVioR/FIX-inconsistency-log-level-between-delegation-token-providers. Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
Revert "[SPARK-26339][SQL] Throws better exception when reading files…
… that start with underscore" This reverts commit c0b9db1.
-
[SPARK-26499][SQL] JdbcUtils.makeGetter does not handle ByteType
…Type ## What changes were proposed in this pull request? Modifed JdbcUtils.makeGetter to handle ByteType. ## How was this patch tested? Added a new test to JDBCSuite that maps ```TINYINT``` to ```ByteType```. Closes apache#23400 from twdsilva/tiny_int_support. Authored-by: Thomas D'Silva <tdsilva@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[SPARK-24544][SQL] Print actual failure cause when look up function f…
…ailed ## What changes were proposed in this pull request? When we operate as below: ` 0: jdbc:hive2://xxx/> create function funnel_analysis as 'com.xxx.hive.extend.udf.UapFunnelAnalysis'; ` ` 0: jdbc:hive2://xxx/> select funnel_analysis(1,",",1,''); Error: org.apache.spark.sql.AnalysisException: Undefined function: 'funnel_analysis'. This function is neither a registered temporary function nor a permanent function registered in the database 'xxx'.; line 1 pos 7 (state=,code=0) ` ` 0: jdbc:hive2://xxx/> describe function funnel_analysis; +-----------------------------------------------------------+--+ | function_desc | +-----------------------------------------------------------+--+ | Function: xxx.funnel_analysis | | Class: com.xxx.hive.extend.udf.UapFunnelAnalysis | | Usage: N/A. | +-----------------------------------------------------------+--+ ` We can see describe funtion will get right information,but when we actually use this funtion,we will get an undefined exception. Which is really misleading,the real cause is below: ` No handler for Hive UDF 'com.xxx.xxx.hive.extend.udf.UapFunnelAnalysis': java.lang.IllegalStateException: Should not be called directly; at org.apache.hadoop.hive.ql.udf.generic.GenericUDTF.initialize(GenericUDTF.java:72) at org.apache.spark.sql.hive.HiveGenericUDTF.outputInspector$lzycompute(hiveUDFs.scala:204) at org.apache.spark.sql.hive.HiveGenericUDTF.outputInspector(hiveUDFs.scala:204) at org.apache.spark.sql.hive.HiveGenericUDTF.elementSchema$lzycompute(hiveUDFs.scala:212) at org.apache.spark.sql.hive.HiveGenericUDTF.elementSchema(hiveUDFs.scala:212) ` This patch print the actual failure for quick debugging. ## How was this patch tested? UT Closes apache#21790 from caneGuy/zhoukang/print-warning1. Authored-by: zhoukang <zhoukang199191@gmail.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[SPARK-25765][ML] Add training cost to BisectingKMeans summary
## What changes were proposed in this pull request? The PR adds the `trainingCost` value to the `BisectingKMeansSummary`, in order to expose the information retrievable by running `computeCost` on the training dataset. This fills the gap with `KMeans` implementation. ## How was this patch tested? improved UTs Closes apache#22764 from mgaido91/SPARK-25765. Authored-by: Marco Gaido <marcogaido91@gmail.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[SPARK-26374][TEST][SQL] Enable TimestampFormatter in HadoopFsRelatio…
…nTest ## What changes were proposed in this pull request? Default timestamp pattern defined in `JSONOptions` doesn't allow saving/loading timestamps with time zones of seconds precision. Because of that, the round trip test failed for timestamps before 1582. In the PR, I propose to extend zone offset section from `XXX` to `XXXXX` which should allow to save/load zone offsets like `-07:52:48`. ## How was this patch tested? It was tested by `JsonHadoopFsRelationSuite` and `TimestampFormatterSuite`. Closes apache#23417 from MaxGekk/hadoopfsrelationtest-new-formatter. Lead-authored-by: Maxim Gekk <max.gekk@gmail.com> Co-authored-by: Maxim Gekk <maxim.gekk@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
Commits on Jan 2, 2019
-
[SPARK-26227][R] from_[csv|json] should accept schema_of_[csv|json] i…
…n R API ## What changes were proposed in this pull request? **1. Document `from_csv(..., schema_of_csv(...))` support:** ```R csv <- "Amsterdam,2018" df <- sql(paste0("SELECT '", csv, "' as csv")) head(select(df, from_csv(df$csv, schema_of_csv(csv)))) ``` ``` from_csv(csv) 1 Amsterdam, 2018 ``` **2. Allow `from_json(..., schema_of_json(...))`** Before: ```R df2 <- sql("SELECT named_struct('name', 'Bob') as people") df2 <- mutate(df2, people_json = to_json(df2$people)) head(select(df2, from_json(df2$people_json, schema_of_json(head(df2)$people_json)))) ``` ``` Error in (function (classes, fdef, mtable) : unable to find an inherited method for function ‘from_json’ for signature ‘"Column", "Column"’ ``` After: ```R df2 <- sql("SELECT named_struct('name', 'Bob') as people") df2 <- mutate(df2, people_json = to_json(df2$people)) head(select(df2, from_json(df2$people_json, schema_of_json(head(df2)$people_json)))) ``` ``` from_json(people_json) 1 Bob ``` **3. (While I'm here) Allow `structType` as schema for `from_csv` support to match with `from_json`.** Before: ```R csv <- "Amsterdam,2018" df <- sql(paste0("SELECT '", csv, "' as csv")) head(select(df, from_csv(df$csv, structType("city STRING, year INT")))) ``` ``` Error in (function (classes, fdef, mtable) : unable to find an inherited method for function ‘from_csv’ for signature ‘"Column", "structType"’ ``` After: ```R csv <- "Amsterdam,2018" df <- sql(paste0("SELECT '", csv, "' as csv")) head(select(df, from_csv(df$csv, structType("city STRING, year INT")))) ``` ``` from_csv(csv) 1 Amsterdam, 2018 ``` ## How was this patch tested? Manually tested and unittests were added. Closes apache#23184 from HyukjinKwon/SPARK-26227-1. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> -
[MINOR][R] Deduplicate RStudio setup documentation
## What changes were proposed in this pull request? This PR targets to deduplicate RStudio setup for SparkR. ## How was this patch tested? N/A Closes apache#23421 from HyukjinKwon/minor-doc. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[SPARK-26508][CORE][SQL] Address warning messages in Java reported at…
… lgtm.com ## What changes were proposed in this pull request? This PR addresses warning messages in Java files reported at [lgtm.com](https://lgtm.com). [lgtm.com](https://lgtm.com) provides automated code review of Java/Python/JavaScript files for OSS projects. [Here](https://lgtm.com/projects/g/apache/spark/alerts/?mode=list&severity=warning) are warning messages regarding Apache Spark project. This PR addresses the following warnings: - Result of multiplication cast to wider type - Implicit narrowing conversion in compound assignment - Boxed variable is never null - Useless null check NOTE: `Potential input resource leak` looks false positive for now. ## How was this patch tested? Existing UTs Closes apache#23420 from kiszk/SPARK-26508. Authored-by: Kazuaki Ishizaki <ishizaki@jp.ibm.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[SPARK-26507][CORE] Fix core tests for Java 11
## What changes were proposed in this pull request? This should make tests in core modules pass for Java 11. ## How was this patch tested? Existing tests, with modifications. Closes apache#23419 from srowen/Java11. Authored-by: Sean Owen <sean.owen@databricks.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[SPARK-26277][SQL][TEST] WholeStageCodegen metrics should be tested w…
…ith whole-stage codegen enabled ## What changes were proposed in this pull request? In `org.apache.spark.sql.execution.metric.SQLMetricsSuite`, there's a test case named "WholeStageCodegen metrics". However, it is executed with whole-stage codegen disabled. This PR fixes this by enable whole-stage codegen for this test case. ## How was this patch tested? Tested locally using exiting test cases. Closes apache#23224 from seancxmao/codegen-metrics. Authored-by: seancxmao <seancxmao@gmail.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
Commits on Jan 3, 2019
-
[SPARK-26023][SQL][FOLLOWUP] Dumping truncated plans and generated co…
…de to a file ## What changes were proposed in this pull request? `DataSourceScanExec` overrides "wrong" `treeString` method without `append`. In the PR, I propose to make `treeString`s **final** to prevent such mistakes in the future. And removed the `treeString` and `verboseString` since they both use `simpleString` with reduction. ## How was this patch tested? It was tested by `DataSourceScanExecRedactionSuite` Closes apache#23431 from MaxGekk/datasource-scan-exec-followup. Authored-by: Maxim Gekk <maxim.gekk@databricks.com> Signed-off-by: gatorsmile <gatorsmile@gmail.com>
-
[SPARK-26403][SQL] Support pivoting using array column for `pivot(col…
…umn)` API ## What changes were proposed in this pull request? This PR fixes `pivot(Column)` can accepts `collection.mutable.WrappedArray`. Note that we return `collection.mutable.WrappedArray` from `ArrayType`, and `Literal.apply` doesn't support this. We can unwrap the array and use it for type dispatch. ```scala val df = Seq( (2, Seq.empty[String]), (2, Seq("a", "x")), (3, Seq.empty[String]), (3, Seq("a", "x"))).toDF("x", "s") df.groupBy("x").pivot("s").count().show() ``` Before: ``` Unsupported literal type class scala.collection.mutable.WrappedArray$ofRef WrappedArray() java.lang.RuntimeException: Unsupported literal type class scala.collection.mutable.WrappedArray$ofRef WrappedArray() at org.apache.spark.sql.catalyst.expressions.Literal$.apply(literals.scala:80) at org.apache.spark.sql.RelationalGroupedDataset.$anonfun$pivot$2(RelationalGroupedDataset.scala:427) at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:237) at scala.collection.IndexedSeqOptimized.foreach(IndexedSeqOptimized.scala:36) at scala.collection.IndexedSeqOptimized.foreach$(IndexedSeqOptimized.scala:33) at scala.collection.mutable.WrappedArray.foreach(WrappedArray.scala:39) at scala.collection.TraversableLike.map(TraversableLike.scala:237) at scala.collection.TraversableLike.map$(TraversableLike.scala:230) at scala.collection.AbstractTraversable.map(Traversable.scala:108) at org.apache.spark.sql.RelationalGroupedDataset.pivot(RelationalGroupedDataset.scala:425) at org.apache.spark.sql.RelationalGroupedDataset.pivot(RelationalGroupedDataset.scala:406) at org.apache.spark.sql.RelationalGroupedDataset.pivot(RelationalGroupedDataset.scala:317) at org.apache.spark.sql.DataFramePivotSuite.$anonfun$new$1(DataFramePivotSuite.scala:341) at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23) ``` After: ``` +---+---+------+ | x| []|[a, x]| +---+---+------+ | 3| 1| 1| | 2| 1| 1| +---+---+------+ ``` ## How was this patch tested? Manually tested and unittests were added. Closes apache#23349 from HyukjinKwon/SPARK-26403. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org> -
[SPARK-26502][SQL] Move hiveResultString() from QueryExecution to Hiv…
…eResult ## What changes were proposed in this pull request? In the PR, I propose to move `hiveResultString()` out of `QueryExecution` and put it to a separate object. Closes apache#23409 from MaxGekk/hive-result-string. Lead-authored-by: Maxim Gekk <maxim.gekk@databricks.com> Co-authored-by: Maxim Gekk <max.gekk@gmail.com> Signed-off-by: Herman van Hovell <hvanhovell@databricks.com>
-
[SPARK-26501][CORE][TEST] Fix unexpected overriden of exitFn in Spark…
…SubmitSuite ## What changes were proposed in this pull request? The overriden of SparkSubmit's exitFn at some previous tests in SparkSubmitSuite may cause the following tests pass even they failed when they were run separately. This PR is to fix this problem. ## How was this patch tested? unittest Closes apache#23404 from liupc/Fix-SparkSubmitSuite-exitFn. Authored-by: Liupengcheng <liupengcheng@xiaomi.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[SPARK-26517][SQL][TEST] Avoid duplicate test in ParquetSchemaPruning…
…Suite ## What changes were proposed in this pull request? `testExactCaseQueryPruning` and `testMixedCaseQueryPruning` don't need to set up `PARQUET_VECTORIZED_READER_ENABLED` config. Because `withMixedCaseData` will run against both Spark vectorized reader and Parquet-mr reader. ## How was this patch tested? Existing test. Closes apache#23427 from viirya/fix-parquet-schema-pruning-test. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[SPARK-26447][SQL] Allow OrcColumnarBatchReader to return less partit…
…ion columns ## What changes were proposed in this pull request? Currently OrcColumnarBatchReader returns all the partition column values in the batch read. In data source V2, we can improve it by returning the required partition column values only. This PR is part of apache#23383 . As cloud-fan suggested, create a new PR to make review easier. Also, this PR doesn't improve `OrcFileFormat`, since in the method `buildReaderWithPartitionValues`, the `requiredSchema` filter out all the partition columns, so we can't know which partition column is required. ## How was this patch tested? Unit test Closes apache#23387 from gengliangwang/refactorOrcColumnarBatch. Lead-authored-by: Gengliang Wang <gengliang.wang@databricks.com> Co-authored-by: Gengliang Wang <ltnwgl@gmail.com> Co-authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
-
[SPARK-26489][CORE] Use ConfigEntry for hardcoded configs for python/…
…r categories ## What changes were proposed in this pull request? The PR makes hardcoded configs below to use ConfigEntry. * spark.pyspark * spark.python * spark.r This patch doesn't change configs which are not relevant to SparkConf (e.g. system properties, python source code) ## How was this patch tested? Existing tests. Closes apache#23428 from HeartSaVioR/SPARK-26489. Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com> Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
Commits on Jan 4, 2019
-
[SPARK-26526][SQL][TEST] Fix invalid test case about non-deterministi…
…c expression ## What changes were proposed in this pull request? Test case in SPARK-10316 is used to make sure non-deterministic `Filter` won't be pushed through `Project` But in current code base this test case can't cover this purpose. Change LogicalRDD to HadoopFsRelation can fix this issue. ## How was this patch tested? Modified test pass. Closes apache#23440 from LinhongLiu/fix-test. Authored-by: Liu,Linhong <liulinhong@baidu.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
-
[MINOR][NETWORK][TEST] Fix TransportFrameDecoderSuite to use ByteBuf …
…instead of ByteBuffer ## What changes were proposed in this pull request? `fireChannelRead` expects `io.netty.buffer.ByteBuf`.I checked that this is the only place which misuse `java.nio.ByteBuffer` in `network` module. ## How was this patch tested? Pass the Jenkins with the existing tests. Closes apache#23442 from dongjoon-hyun/SPARK-NETWORK-COMMON. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
-
[SPARK-26445][CORE] Use ConfigEntry for hardcoded configs for driver/…
…executor categories. ## What changes were proposed in this pull request? The PR makes hardcoded spark.driver, spark.executor, and spark.cores.max configs to use `ConfigEntry`. Note that some config keys are from `SparkLauncher` instead of defining in the config package object because the string is already defined in it and it does not depend on core module. ## How was this patch tested? Existing tests. Closes apache#23415 from ueshin/issues/SPARK-26445/hardcoded_driver_executor_configs. Authored-by: Takuya UESHIN <ueshin@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[SPARK-26306][TEST][BUILD] More memory to de-flake SorterSuite
## What changes were proposed in this pull request? Increase test memory to avoid OOM in TimSort-related tests. ## How was this patch tested? Existing tests. Closes apache#23425 from srowen/SPARK-26306. Authored-by: Sean Owen <sean.owen@databricks.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[SPARK-24421][CORE][FOLLOWUP] Use normal direct ByteBuffer allocation…
… if Cleaner can't be set ## What changes were proposed in this pull request? In Java 9+ we can't use sun.misc.Cleaner by default anymore, and this was largely handled in apache#22993 However I think the change there left a significant problem. If a DirectByteBuffer is allocated using the reflective hack in Platform, now, we by default can't set a Cleaner. But I believe this means the memory isn't freed promptly or possibly at all. If a Cleaner can't be set, I think we need to use normal APIs to allocate the direct ByteBuffer. According to comments in the code, the downside is simply that the normal APIs will check and impose limits on how much off-heap memory can be allocated. Per the original review on apache#22993 this much seems fine, as either way in this case the user would have to add a JVM setting (increase max, or allow the reflective access). ## How was this patch tested? Existing tests. This resolved an OutOfMemoryError in Java 11 from TimSort tests without increasing test heap size. (See apache#23419 (comment) ) This suggests there is a problem and that this resolves it. Closes apache#23424 from srowen/SPARK-24421.2. Authored-by: Sean Owen <sean.owen@databricks.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
Commits on Jan 5, 2019
-
[SPARK-26537][BUILD] change git-wip-us to gitbox
## What changes were proposed in this pull request? due to apache recently moving from git-wip-us.apache.org to gitbox.apache.org, we need to update the packaging scripts to point to the new repo location. this will also need to be backported to 2.4, 2.3, 2.1, 2.0 and 1.6. ## How was this patch tested? the build system will test this. Please review http://spark.apache.org/contributing.html before opening a pull request. Closes apache#23454 from shaneknapp/update-apache-repo. Authored-by: shane knapp <incomplete@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
-
[SPARK-26536][BUILD][TEST] Upgrade Mockito to 2.23.4
## What changes were proposed in this pull request? This PR upgrades Mockito from 1.10.19 to 2.23.4. The following changes are required. - Replace `org.mockito.Matchers` with `org.mockito.ArgumentMatchers` - Replace `anyObject` with `any` - Replace `getArgumentAt` with `getArgument` and add type annotation. - Use `isNull` matcher in case of `null` is invoked. ```scala saslHandler.channelInactive(null); - verify(handler).channelInactive(any(TransportClient.class)); + verify(handler).channelInactive(isNull()); ``` - Make and use `doReturn` wrapper to avoid [SI-4775](https://issues.scala-lang.org/browse/SI-4775) ```scala private def doReturn(value: Any) = org.mockito.Mockito.doReturn(value, Seq.empty: _*) ``` ## How was this patch tested? Pass the Jenkins with the existing tests. Closes apache#23452 from dongjoon-hyun/SPARK-26536. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> -
[SPARK-26541][BUILD] Add
-Pdocker-integration-teststo `dev/scalast……yle` ## What changes were proposed in this pull request? This PR makes `scalastyle` to check `docker-integration-tests` module additionally and fixes one error. ## How was this patch tested? Pass the Jenkins with the updated Scalastyle. ``` ======================================================================== Running Scala style checks ======================================================================== Scalastyle checks passed. ``` Closes apache#23459 from dongjoon-hyun/SPARK-26541. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
-
[SPARK-26078][SQL][FOLLOWUP] Remove useless import
## What changes were proposed in this pull request? While backporting the patch to 2.4/2.3, I realized that the patch introduces unneeded imports (probably leftovers from intermediate changes). This PR removes the useless import. ## How was this patch tested? NA Closes apache#23451 from mgaido91/SPARK-26078_FOLLOWUP. Authored-by: Marco Gaido <marcogaido91@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
-
[SPARK-26246][SQL][FOLLOWUP] Inferring TimestampType from JSON
## What changes were proposed in this pull request? Added new JSON option `inferTimestamp` (`true` by default) to control inferring of `TimestampType` from string values. ## How was this patch tested? Add new UT to `JsonInferSchemaSuite`. Closes apache#23455 from MaxGekk/json-infer-time-followup. Authored-by: Maxim Gekk <maxim.gekk@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[MINOR][DOC] Fix typos in the SQL migration guide
## What changes were proposed in this pull request? Fixed a few typos in the migration guide. Closes apache#23465 from MaxGekk/fix-typos-migration-guide. Authored-by: Maxim Gekk <max.gekk@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[SPARK-26545] Fix typo in EqualNullSafe's truth table comment
## What changes were proposed in this pull request? The truth table comment in EqualNullSafe incorrectly marked FALSE results as UNKNOWN. ## How was this patch tested? N/A Closes apache#23461 from rednaxelafx/fix-typo. Authored-by: Kris Mok <kris.mok@databricks.com> Signed-off-by: gatorsmile <gatorsmile@gmail.com>
Commits on Jan 6, 2019
-
[SPARK-26548][SQL] Don't hold CacheManager write lock while computing…
… executedPlan ## What changes were proposed in this pull request? Address SPARK-26548, in Spark 2.4.0, the CacheManager holds a write lock while computing the executedPlan for a cached logicalPlan. In some cases with very large query plans this can be an expensive operation, taking minutes to run. The entire cache is blocked during this time. This PR changes that so the writeLock is only obtained after the executedPlan is generated, this reduces the time the lock is held to just the necessary time when the shared data structure is being updated. gatorsmile and cloud-fan - You can committed patches in this area before. This is a small incremental change. ## How was this patch tested? Has been tested on a live system where the blocking was causing major issues and it is working well. CacheManager has no explicit unit test but is used in many places internally as part of the SharedState. Closes apache#23469 from DaveDeCaprio/optimizer-unblocked. Lead-authored-by: Dave DeCaprio <daved@alum.mit.edu> Co-authored-by: David DeCaprio <daved@alum.mit.edu> Signed-off-by: gatorsmile <gatorsmile@gmail.com>
-
[SPARK-26527][CORE] Let acquireUnrollMemory fail fast if required spa…
…ce exceeds memory limit ## What changes were proposed in this pull request? When acquiring unroll memory from `StaticMemoryManager`, let it fail fast if required space exceeds memory limit, just like acquiring storage memory. I think this may reduce some computation and memory evicting costs especially when required space(`numBytes`) is very big. ## How was this patch tested? Existing unit tests. Closes apache#23426 from SongYadong/acquireUnrollMemory_fail_fast. Authored-by: SongYadong <song.yadong1@zte.com.cn> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[SPARK-26339][SQL] Throws better exception when reading files that st…
…art with underscore ## What changes were proposed in this pull request? My pull request apache#23288 was resolved and merged to master, but it turned out later that my change breaks another regression test. Because we cannot reopen pull request, I create a new pull request here. Commit 92934b4 is only change after pull request apache#23288. `CheckFileExist` was avoided at 239cfa4 after discussing apache#23288 (comment). But, that change turned out to be wrong because we should not check if argument checkFileExist is false. Test https://github.com/apache/spark/blob/27e42c1de502da80fa3e22bb69de47fb00158174/sql/core/src/test/scala/org/apache/spark/sql/SQLQuerySuite.scala#L2555 failed when we avoided checkFileExist, but now successed after commit 92934b4 . ## How was this patch tested? Both of below tests were passed. ``` testOnly org.apache.spark.sql.execution.datasources.csv.CSVSuite testOnly org.apache.spark.sql.SQLQuerySuite ``` Closes apache#23446 from KeiichiHirobe/SPARK-26339. Authored-by: Hirobe Keiichi <keiichi_hirobe@forcia.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
Commits on Jan 7, 2019
-
[SPARK-26547][SQL] Remove duplicate toHiveString from HiveUtils
## What changes were proposed in this pull request? The `toHiveString()` and `toHiveStructString` methods were removed from `HiveUtils` because they have been already implemented in `HiveResult`. One related test was moved to `HiveResultSuite`. ## How was this patch tested? By tests from `hive-thriftserver`. Closes apache#23466 from MaxGekk/dedup-hive-result-string. Authored-by: Maxim Gekk <max.gekk@gmail.com> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
-
[SPARK-26554][BUILD] Update
release-util.shto avoid GitBox fake 20……0 headers ## What changes were proposed in this pull request? Unlike the previous Apache Git repository, new GitBox repository returns a fake HTTP 200 header instead of `404 Not Found` header. This makes release scripts out of order. This PR aims to fix it to handle the html body message instead of the fake HTTP headers. This is a release blocker. ```bash $ curl -s --head --fail "https://gitbox.apache.org/repos/asf?p=spark.git;a=commit;h=v3.0.0" HTTP/1.1 200 OK Date: Sun, 06 Jan 2019 22:42:39 GMT Server: Apache/2.4.18 (Ubuntu) Vary: Accept-Encoding Access-Control-Allow-Origin: * Access-Control-Allow-Methods: POST, GET, OPTIONS Access-Control-Allow-Headers: X-PINGOTHER Access-Control-Max-Age: 1728000 Content-Type: text/html; charset=utf-8 ``` **BEFORE** ```bash $ ./do-release-docker.sh -d /tmp/test -n Branch [branch-2.4]: Current branch version is 2.4.1-SNAPSHOT. Release [2.4.1]: RC # [1]: v2.4.1-rc1 already exists. Continue anyway [y/n]? ``` **AFTER** ```bash $ ./do-release-docker.sh -d /tmp/test -n Branch [branch-2.4]: Current branch version is 2.4.1-SNAPSHOT. Release [2.4.1]: RC # [1]: This is a dry run. Please confirm the ref that will be built for testing. Ref [v2.4.1-rc1]: ``` ## How was this patch tested? Manual. Closes apache#23476 from dongjoon-hyun/SPARK-26554. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
-
[SPARK-26536][BUILD][FOLLOWUP][TEST-MAVEN] Make StreamingReadSupport …
…public for maven testing ## What changes were proposed in this pull request? `StreamingReadSupport` is designed to be a `package` interface. Mockito seems to complain during `Maven` testing. This doesn't fail in `sbt` and IntelliJ. For mock-testing purpose, this PR makes it `public` interface and adds explicit comments like `public interface ReadSupport` ```scala EpochCoordinatorSuite: *** RUN ABORTED *** java.lang.IllegalAccessError: tried to access class org.apache.spark.sql.sources.v2.reader.streaming.StreamingReadSupport from class org.apache.spark.sql.sources.v2.reader.streaming.ContinuousReadSupport$MockitoMock$58628338 at org.apache.spark.sql.sources.v2.reader.streaming.ContinuousReadSupport$MockitoMock$58628338.<clinit>(Unknown Source) at sun.reflect.GeneratedSerializationConstructorAccessor632.newInstance(Unknown Source) at java.lang.reflect.Constructor.newInstance(Constructor.java:423) at org.objenesis.instantiator.sun.SunReflectionFactoryInstantiator.newInstance(SunReflectionFactoryInstantiator.java:48) at org.objenesis.ObjenesisBase.newInstance(ObjenesisBase.java:73) at org.mockito.internal.creation.instance.ObjenesisInstantiator.newInstance(ObjenesisInstantiator.java:19) at org.mockito.internal.creation.bytebuddy.SubclassByteBuddyMockMaker.createMock(SubclassByteBuddyMockMaker.java:47) at org.mockito.internal.creation.bytebuddy.ByteBuddyMockMaker.createMock(ByteBuddyMockMaker.java:25) at org.mockito.internal.util.MockUtil.createMock(MockUtil.java:35) at org.mockito.internal.MockitoCore.mock(MockitoCore.java:69) ``` ## How was this patch tested? Pass the Jenkins with Maven build Closes apache#23463 from dongjoon-hyun/SPARK-26536-2. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
-
[MINOR][BUILD] Fix script name in
release-tag.shusage message## What changes were proposed in this pull request? This PR fixes the old script name in `release-tag.sh`. $ ./release-tag.sh --help | head -n1 usage: tag-release.sh ## How was this patch tested? Manual. $ ./release-tag.sh --help | head -n1 usage: release-tag.sh Closes apache#23477 from dongjoon-hyun/SPARK-RELEASE-TAG. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org> -
[SPARK-26559][ML][PYSPARK] ML image can't work with numpy versions pr…
…ior to 1.9 ## What changes were proposed in this pull request? Due to [API change](https://github.com/numpy/numpy/pull/4257/files#diff-c39521d89f7e61d6c0c445d93b62f7dc) at 1.9, PySpark image doesn't work with numpy version prior to 1.9. When running image test with numpy version prior to 1.9, we can see error: ``` test_read_images (pyspark.ml.tests.test_image.ImageReaderTest) ... ERROR test_read_images_multiple_times (pyspark.ml.tests.test_image.ImageReaderTest2) ... ok ====================================================================== ERROR: test_read_images (pyspark.ml.tests.test_image.ImageReaderTest) ---------------------------------------------------------------------- Traceback (most recent call last): File "/Users/viirya/docker_tmp/repos/spark-1/python/pyspark/ml/tests/test_image.py", line 36, in test_read_images self.assertEqual(ImageSchema.toImage(array, origin=first_row[0]), first_row) File "/Users/viirya/docker_tmp/repos/spark-1/python/pyspark/ml/image.py", line 193, in toImage data = bytearray(array.astype(dtype=np.uint8).ravel().tobytes()) AttributeError: 'numpy.ndarray' object has no attribute 'tobytes' ---------------------------------------------------------------------- Ran 2 tests in 29.040s FAILED (errors=1) ``` ## How was this patch tested? Manually test with numpy version prior and after 1.9. Closes apache#23484 from viirya/fix-pyspark-image. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[SPARK-26383][CORE] NPE when use DataFrameReader.jdbc with wrong URL
### What changes were proposed in this pull request? When passing wrong url to jdbc then It would throw IllegalArgumentException instead of NPE. ### How was this patch tested? Adding test case to Existing tests in JDBCSuite Closes apache#23464 from ayudovin/fixing-npe. Authored-by: ayudovin <a.yudovin6695@gmail.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[SPARK-24489][ML] Check for invalid input type of weight data in ml.P…
…owerIterationClustering ## What changes were proposed in this pull request? The test case will result the following failure. currently in ml.PIC, there is no check for the data type of weight column. ``` test("invalid input types for weight") { val invalidWeightData = spark.createDataFrame(Seq( (0L, 1L, "a"), (2L, 3L, "b") )).toDF("src", "dst", "weight") val pic = new PowerIterationClustering() .setWeightCol("weight") val result = pic.assignClusters(invalidWeightData) } ``` ``` Job aborted due to stage failure: Task 0 in stage 8077.0 failed 1 times, most recent failure: Lost task 0.0 in stage 8077.0 (TID 882, localhost, executor driver): scala.MatchError: [0,1,null] (of class org.apache.spark.sql.catalyst.expressions.GenericRowWithSchema) at org.apache.spark.ml.clustering.PowerIterationClustering$$anonfun$3.apply(PowerIterationClustering.scala:178) at org.apache.spark.ml.clustering.PowerIterationClustering$$anonfun$3.apply(PowerIterationClustering.scala:178) at scala.collection.Iterator$$anon$11.next(Iterator.scala:409) at scala.collection.Iterator$$anon$12.nextCur(Iterator.scala:434) at scala.collection.Iterator$$anon$12.hasNext(Iterator.scala:440) at scala.collection.Iterator$class.foreach(Iterator.scala:893) at scala.collection.AbstractIterator.foreach(Iterator.scala:1336) at org.apache.spark.graphx.EdgeRDD$$anonfun$1.apply(EdgeRDD.scala:107) at org.apache.spark.graphx.EdgeRDD$$anonfun$1.apply(EdgeRDD.scala:105) at org.apache.spark.rdd.RDD$$anonfun$mapPartitionsWithIndex$1$$anonfun$apply$26.apply(RDD.scala:847) ``` In this PR, added check types for weight column. ## How was this patch tested? UT added Please review http://spark.apache.org/contributing.html before opening a pull request. Closes apache#21509 from shahidki31/testCasePic. Authored-by: Shahid <shahidki31@gmail.com> Signed-off-by: Holden Karau <holden@pigscanfly.ca> -
[SPARK-25689][YARN] Make driver, not AM, manage delegation tokens.
This change modifies the behavior of the delegation token code when running on YARN, so that the driver controls the renewal, in both client and cluster mode. For that, a few different things were changed: * The AM code only runs code that needs DTs when DTs are available. In a way, this restores the AM behavior to what it was pre-SPARK-23361, but keeping the fix added in that bug. Basically, all the AM code is run in a "UGI.doAs()" block; but code that needs to talk to HDFS (basically the distributed cache handling code) was delayed to the point where the driver is up and running, and thus when valid delegation tokens are available. * SparkSubmit / ApplicationMaster now handle user login, not the token manager. The previous AM code was relying on the token manager to keep the user logged in when keytabs are used. This required some odd APIs in the token manager and the AM so that the right UGI was exposed and used in the right places. After this change, the logged in user is handled separately from the token manager, so the API was cleaned up, and, as explained above, the whole AM runs under the logged in user, which also helps with simplifying some more code. * Distributed cache configs are sent separately to the AM. Because of the delayed initialization of the cached resources in the AM, it became easier to write the cache config to a separate properties file instead of bundling it with the rest of the Spark config. This also avoids having to modify the SparkConf to hide things from the UI. * Finally, the AM doesn't manage the token manager anymore. The above changes allow the token manager to be completely handled by the driver's scheduler backend code also in YARN mode (whether client or cluster), making it similar to other RMs. To maintain the fix added in SPARK-23361 also in client mode, the AM now sends an extra message to the driver on initialization to fetch delegation tokens; and although it might not really be needed, the driver also keeps the running AM updated when new tokens are created. Tested in a kerberized cluster with the same tests used to validate SPARK-23361, in both client and cluster mode. Also tested with a non-kerberized cluster. Closes apache#23338 from vanzin/SPARK-25689. Authored-by: Marcelo Vanzin <vanzin@cloudera.com> Signed-off-by: Imran Rashid <irashid@cloudera.com>
-
[SPARK-26065][SQL] Change query hint from a
LogicalPlanto a field## What changes were proposed in this pull request? The existing query hint implementation relies on a logical plan node `ResolvedHint` to store query hints in logical plans, and on `Statistics` in physical plans. Since `ResolvedHint` is not really a logical operator and can break the pattern matching for existing and future optimization rules, it is a issue to the Optimizer as the old `AnalysisBarrier` was to the Analyzer. Given the fact that all our query hints are either 1) a join hint, i.e., broadcast hint; or 2) a re-partition hint, which is indeed an operator, we only need to add a hint field on the Join plan and that will be a good enough solution for the current hint usage. This PR is to let `Join` node have a hint for its left sub-tree and another hint for its right sub-tree and each hint is a merged result of all the effective hints specified in the corresponding sub-tree. The "effectiveness" of a hint, i.e., whether that hint should be propagated to the `Join` node, is currently consistent with the hint propagation rules originally implemented in the `Statistics` approach. Note that the `ResolvedHint` node still has to live through the analysis stage because of the `Dataset` interface, but it will be got rid of and moved to the `Join` node in the "pre-optimization" stage. This PR also introduces a change in how hints work with join reordering. Before this PR, hints would stop join reordering. For example, in "a.join(b).join(c).hint("broadcast").join(d)", the broadcast hint would stop d from participating in the cost-based join reordering while still allowing reordering from under the hint node. After this PR, though, the broadcast hint will not interfere with join reordering at all, and after reordering if a relation associated with a hint stays unchanged or equivalent to the original relation, the hint will be retained, otherwise will be discarded. For example, the original plan is like "a.join(b).hint("broadcast").join(c).hint("broadcast").join(d)", thus the join order is "a JOIN b JOIN c JOIN d". So if after reordering the join order becomes "a JOIN b JOIN (c JOIN d)", the plan will be like "a.join(b).hint("broadcast").join(c.join(d))"; but if after reordering the join order becomes "a JOIN c JOIN b JOIN d", the plan will be like "a.join(c).join(b).hint("broadcast").join(d)". ## How was this patch tested? Added new tests. Closes apache#23036 from maryannxue/query-hint. Authored-by: maryannxue <maryannxue@apache.org> Signed-off-by: gatorsmile <gatorsmile@gmail.com> -
[SPARK-26491][CORE][TEST] Use ConfigEntry for hardcoded configs for t…
…est categories ## What changes were proposed in this pull request? The PR makes hardcoded `spark.test` and `spark.testing` configs to use `ConfigEntry` and put them in the config package. ## How was this patch tested? existing UTs Closes apache#23413 from mgaido91/SPARK-26491. Authored-by: Marco Gaido <marcogaido91@gmail.com> Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
-
[SPARK-26339][SQL][FOLLOW-UP] Issue warning instead of throwing an ex…
…ception for underscore files ## What changes were proposed in this pull request? The PR apache#23446 happened to introduce a behaviour change - empty dataframes can't be read anymore from underscore files. It looks controversial to allow or disallow this case so this PR targets to fix to issue warning instead of throwing an exception to be more conservative. **Before** ```scala scala> spark.read.schema("a int").parquet("_tmp*").show() org.apache.spark.sql.AnalysisException: All paths were ignored: file:/.../_tmp file:/.../_tmp1; at org.apache.spark.sql.execution.datasources.DataSource.checkAndGlobPathIfNecessary(DataSource.scala:570) at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:360) at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:231) at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:219) at org.apache.spark.sql.DataFrameReader.parquet(DataFrameReader.scala:651) at org.apache.spark.sql.DataFrameReader.parquet(DataFrameReader.scala:635) ... 49 elided scala> spark.read.text("_tmp*").show() org.apache.spark.sql.AnalysisException: All paths were ignored: file:/.../_tmp file:/.../_tmp1; at org.apache.spark.sql.execution.datasources.DataSource.checkAndGlobPathIfNecessary(DataSource.scala:570) at org.apache.spark.sql.execution.datasources.DataSource.resolveRelation(DataSource.scala:360) at org.apache.spark.sql.DataFrameReader.loadV1Source(DataFrameReader.scala:231) at org.apache.spark.sql.DataFrameReader.load(DataFrameReader.scala:219) at org.apache.spark.sql.DataFrameReader.text(DataFrameReader.scala:723) at org.apache.spark.sql.DataFrameReader.text(DataFrameReader.scala:695) ... 49 elided ``` **After** ```scala scala> spark.read.schema("a int").parquet("_tmp*").show() 19/01/07 15:14:43 WARN DataSource: All paths were ignored: file:/.../_tmp file:/.../_tmp1 +---+ | a| +---+ +---+ scala> spark.read.text("_tmp*").show() 19/01/07 15:14:51 WARN DataSource: All paths were ignored: file:/.../_tmp file:/.../_tmp1 +-----+ |value| +-----+ +-----+ ``` ## How was this patch tested? Manually tested as above. Closes apache#23481 from HyukjinKwon/SPARK-26339. Authored-by: Hyukjin Kwon <gurwls223@apache.org> Signed-off-by: gatorsmile <gatorsmile@gmail.com>
Commits on Jan 8, 2019
-
[MINOR][K8S] add missing docs for podTemplateContainerName properties
## What changes were proposed in this pull request? Adding docs for an enhancement that came in late in this PR: apache#22146 Currently the docs state that we're going to use the first container in a pod template, which was the implementation for some time, until it was improved with 2 new properties. ## How was this patch tested? I tested that the properties work by combining pod templates with client-mode and a simple pod template. Please review http://spark.apache.org/contributing.html before opening a pull request. Closes apache#23155 from aditanase/k8s-readme. Authored-by: Adrian Tanase <atanase@adobe.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[SPARK-26554][BUILD][FOLLOWUP] Use GitHub instead of GitBox to check …
…HEADER ## What changes were proposed in this pull request? This PR uses GitHub repository instead of GitBox because GitHub repo returns HTTP header status correctly. ## How was this patch tested? Manual. ``` $ ./do-release-docker.sh -d /tmp/test -n Branch [branch-2.4]: Current branch version is 2.4.1-SNAPSHOT. Release [2.4.1]: RC # [1]: This is a dry run. Please confirm the ref that will be built for testing. Ref [v2.4.1-rc1]: ``` Closes apache#23482 from dongjoon-hyun/SPARK-26554-2. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
-
[SPARK-24196][SQL] Implement Spark's own GetSchemasOperation
## What changes were proposed in this pull request? This PR fix SQL Client tools can't show DBs by implementing Spark's own `GetSchemasOperation`. ## How was this patch tested? unit tests and manual tests   Closes apache#22903 from wangyum/SPARK-24196. Authored-by: Yuming Wang <yumwang@ebay.com> Signed-off-by: gatorsmile <gatorsmile@gmail.com>
-
[SPARK-26323][SQL] Scala UDF should still check input types even if s…
…ome inputs are of type Any ## What changes were proposed in this pull request? For Scala UDF, when checking input nullability, we will skip inputs with type `Any`, and only check the inputs that provide nullability info. We should do the same for checking input types. ## How was this patch tested? new tests Closes apache#23275 from cloud-fan/udf. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[MINOR][WEBUI] Modify the name of the column named "shuffle spill" in…
… the StagePage ## What changes were proposed in this pull request?  For this DAG, it has no shuffle operation, only sorting, and sorting leads to spill.  So I think the name of the column named "shuffle spill" is not all right in the StagePage ## How was this patch tested? Manual testing Closes apache#23483 from 10110346/shufflespillwebui. Authored-by: liuxian <liu.xian3@zte.com.cn> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[SPARK-26002][SQL] Fix day of year calculation for Julian calendar days
## What changes were proposed in this pull request? Fixing leap year calculations for date operators (year/month/dayOfYear) where the Julian calendars are used (before 1582-10-04). In a Julian calendar every years which are multiples of 4 are leap years (there is no extra exception for years multiples of 100). ## How was this patch tested? With a unit test ("SPARK-26002: correct day of year calculations for Julian calendar years") which focuses to these corner cases. Manually: ``` scala> sql("select year('1500-01-01')").show() +------------------------------+ |year(CAST(1500-01-01 AS DATE))| +------------------------------+ | 1500| +------------------------------+ scala> sql("select dayOfYear('1100-01-01')").show() +-----------------------------------+ |dayofyear(CAST(1100-01-01 AS DATE))| +-----------------------------------+ | 1| +-----------------------------------+ ``` Closes apache#23000 from attilapiros/julianOffByDays. Authored-by: “attilapiros” <piros.attila.zsolt@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> -
[SPARK-24522][UI] Create filter to apply HTTP security checks consist…
…ently. Currently there is code scattered in a bunch of places to do different things related to HTTP security, such as access control, setting security-related headers, and filtering out bad content. This makes it really easy to miss these things when writing new UI code. This change creates a new filter that does all of those things, and makes sure that all servlet handlers that are attached to the UI get the new filter and any user-defined filters consistently. The extent of the actual features should be the same as before. The new filter is added at the end of the filter chain, because authentication is done by custom filters and thus needs to happen first. This means that custom filters see unfiltered HTTP requests - which is actually the current behavior anyway. As a side-effect of some of the code refactoring, handlers added after the initial set also get wrapped with a GzipHandler, which didn't happen before. Tested with added unit tests and in a history server with SPNEGO auth configured. Closes apache#23302 from vanzin/SPARK-24522. Authored-by: Marcelo Vanzin <vanzin@cloudera.com> Signed-off-by: Imran Rashid <irashid@cloudera.com>
-
[SPARK-24920][CORE] Allow sharing Netty's memory pool allocators
## What changes were proposed in this pull request? Introducing shared polled ByteBuf allocators. This feature can be enabled via the "spark.network.sharedByteBufAllocators.enabled" configuration. When it is on then only two pooled ByteBuf allocators are created: - one for transport servers where caching is allowed and - one for transport clients where caching is disabled This way the cache allowance remains as before. Both shareable pools are created with numCores parameter set to 0 (which defaults to the available processors) as conf.serverThreads() and conf.clientThreads() are module dependant and the lazy creation of this allocators would lead to unpredicted behaviour. When "spark.network.sharedByteBufAllocators.enabled" is false then a new allocator is created for every transport client and server separately as was before this PR. ## How was this patch tested? Existing unit tests. Closes apache#23278 from attilapiros/SPARK-24920. Authored-by: “attilapiros” <piros.attila.zsolt@gmail.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[SPARK-26349][PYSPARK] Forbid insecure py4j gateways
Spark always creates secure py4j connections between java and python, but it also allows users to pass in their own connection. This ensures that even passed in connections are secure. Added test cases verifying the failure with a (mocked) insecure gateway. This is closely related to SPARK-26019, but this entirely forbids the insecure connection, rather than creating the "escape-hatch". Closes apache#23441 from squito/SPARK-26349. Authored-by: Imran Rashid <irashid@cloudera.com> Signed-off-by: Bryan Cutler <cutlerb@gmail.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Commits on Jan 9, 2019
-
[SPARK-26571][SQL] Update Hive Serde mapping with canonical name of P…
…arquet and Orc FileFormat ## What changes were proposed in this pull request? Currently Spark table maintains Hive catalog storage format, so that Hive client can read it. In `HiveSerDe.scala`, Spark uses a mapping from its data source to HiveSerde. The mapping is old, we need to update with latest canonical name of Parquet and Orc FileFormat. Otherwise the following queries will result in wrong Serde value in Hive table(default value `org.apache.hadoop.mapred.SequenceFileInputFormat`), and Hive client will fail to read the output table: ``` df.write.format("org.apache.spark.sql.execution.datasources.parquet.ParquetFileFormat").saveAsTable(..) ``` ``` df.write.format("org.apache.spark.sql.execution.datasources.orc.OrcFileFormat").saveAsTable(..) ``` This minor PR is to fix the mapping. ## How was this patch tested? Unit test. Closes apache#23491 from gengliangwang/fixHiveSerdeMap. Authored-by: Gengliang Wang <gengliang.wang@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com> -
[SPARK-26529] Add debug logs for confArchive when preparing local res…
…ource ## What changes were proposed in this pull request? Currently, `Client#createConfArchive` do not handle IOException, and some detail info is not provided in logs. Sometimes, this may delay the time of locating the root cause of io error. This PR will add debug logs for confArchive when preparing local resource. ## How was this patch tested? unittest Closes apache#23444 from liupc/Add-logs-for-IOException-when-preparing-local-resource. Authored-by: Liupengcheng <liupengcheng@xiaomi.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[SPARK-26549][PYSPARK] Fix for python worker reuse take no effect for…
… parallelize lazy iterable range ## What changes were proposed in this pull request? During the follow-up work(apache#23435) for PySpark worker reuse scenario, we found that the worker reuse takes no effect for `sc.parallelize(xrange(...))`. It happened because of the specialize rdd.parallelize logic for xrange(introduced in apache#3264) generated data by lazy iterable range, which don't need to use the passed-in iterator. But this will break the end of stream checking in python worker and finally cause worker reuse takes no effect. See more details in [SPARK-26549](https://issues.apache.org/jira/browse/SPARK-26549) description. We fix this by force using the passed-in iterator. ## How was this patch tested? New UT in test_worker.py. Closes apache#23470 from xuanyuanking/SPARK-26549. Authored-by: Yuanjian Li <xyliyuanjian@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[SPARK-25484][SQL][TEST] Refactor ExternalAppendOnlyUnsafeRowArrayBen…
…chmark ## What changes were proposed in this pull request? Refactor ExternalAppendOnlyUnsafeRowArrayBenchmark to use main method. ## How was this patch tested? Manually tested and regenerated results. Please note that `spark.memory.debugFill` setting has a huge impact on this benchmark. Since it is set to true by default when running the benchmark from SBT, we need to disable it: ``` SPARK_GENERATE_BENCHMARK_FILES=1 build/sbt ";project sql;set javaOptions in Test += \"-Dspark.memory.debugFill=false\";test:runMain org.apache.spark.sql.execution.ExternalAppendOnlyUnsafeRowArrayBenchmark" ``` Closes apache#22617 from peter-toth/SPARK-25484. Lead-authored-by: Peter Toth <peter.toth@gmail.com> Co-authored-by: Peter Toth <ptoth@hortonworks.com> Co-authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
3 people committedJan 9, 2019 -
[SPARK-26448][SQL] retain the difference between 0.0 and -0.0
## What changes were proposed in this pull request? In apache#23043 , we introduced a behavior change: Spark users are not able to distinguish 0.0 and -0.0 anymore. This PR proposes an alternative fix to the original bug, to retain the difference between 0.0 and -0.0 inside Spark. The idea is, we can rewrite the window partition key, join key and grouping key during logical phase, to normalize the special floating numbers. Thus only operators care about special floating numbers need to pay the perf overhead, and end users can distinguish -0.0. ## How was this patch tested? existing test Closes apache#23388 from cloud-fan/minor. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: gatorsmile <gatorsmile@gmail.com>
-
[SPARK-26065][FOLLOW-UP][SQL] Fix the Failure when having two Consecu…
…tive Hints ## What changes were proposed in this pull request? This is to fix a bug in apache#23036, which would lead to an exception in case of two consecutive hints. ## How was this patch tested? Added a new test. Closes apache#23501 from maryannxue/query-hint-followup. Authored-by: maryannxue <maryannxue@apache.org> Signed-off-by: gatorsmile <gatorsmile@gmail.com>
Commits on Jan 10, 2019
-
[SPARK-26493][SQL] Allow multiple spark.sql.extensions
## What changes were proposed in this pull request? Allow multiple spark.sql.extensions to be specified in the configuration. ## How was this patch tested? New tests are added. Closes apache#23398 from jamisonbennett/SPARK-26493. Authored-by: Jamison Bennett <jamison.bennett@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[SPARK-26546][SQL] Caching of java.time.format.DateTimeFormatter
## What changes were proposed in this pull request? Added a cache for java.time.format.DateTimeFormatter instances with keys consist of pattern and locale. This should allow to avoid parsing of timestamp/date patterns each time when new instance of `TimestampFormatter`/`DateFormatter` is created. ## How was this patch tested? By existing test suites `TimestampFormatterSuite`/`DateFormatterSuite` and `JsonFunctionsSuite`/`JsonSuite`. Closes apache#23462 from MaxGekk/time-formatter-caching. Lead-authored-by: Maxim Gekk <max.gekk@gmail.com> Co-authored-by: Maxim Gekk <maxim.gekk@databricks.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[SPARK-26491][K8S][FOLLOWUP] Fix compile failure
## What changes were proposed in this pull request? This fixes the compilation error. ``` $ cd resource-managers/kubernetes/integration-tests $ mvn test-compile [ERROR] /Users/dongjoon/APACHE/spark/resource-managers/kubernetes/integration-tests/src/test/scala/org/apache/spark/deploy/k8s/integrationtest/KubernetesTestComponents.scala:71: type mismatch; found : org.apache.spark.internal.config.OptionalConfigEntry[Boolean] required: String [ERROR] .set(IS_TESTING, false) [ERROR] ^ ``` ## How was this patch tested? Pass the Jenkins K8S Integration test or Manual. Closes apache#23505 from dongjoon-hyun/SPARK-26491. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
-
[SPARK-22128][CORE][BUILD] Add
paranamerdependency tocoremodule## What changes were proposed in this pull request? With Scala-2.12 profile, Spark application fails while Spark is okay. For example, our documented `SimpleApp` Java example succeeds to compile but it fails at runtime because it doesn't use `paranamer 2.8` and hits [SPARK-22128](https://issues.apache.org/jira/browse/SPARK-22128). This PR aims to declare it explicitly for the Spark applications. Note that this doesn't introduce new dependency to Spark itself. https://dist.apache.org/repos/dist/dev/spark/3.0.0-SNAPSHOT-2019_01_09_13_59-e853afb-docs/_site/quick-start.html The following is the dependency tree from the Spark application. **BEFORE** ``` $ mvn dependency:tree -Dincludes=com.thoughtworks.paranamer [INFO] --- maven-dependency-plugin:2.8:tree (default-cli) simple --- [INFO] my.test:simple:jar:1.0-SNAPSHOT [INFO] \- org.apache.spark:spark-sql_2.12:jar:3.0.0-SNAPSHOT:compile [INFO] \- org.apache.spark:spark-core_2.12:jar:3.0.0-SNAPSHOT:compile [INFO] \- org.apache.avro:avro:jar:1.8.2:compile [INFO] \- com.thoughtworks.paranamer:paranamer:jar:2.7:compile ``` **AFTER** ``` [INFO] --- maven-dependency-plugin:2.8:tree (default-cli) simple --- [INFO] my.test:simple:jar:1.0-SNAPSHOT [INFO] \- org.apache.spark:spark-sql_2.12:jar:3.0.0-SNAPSHOT:compile [INFO] \- org.apache.spark:spark-core_2.12:jar:3.0.0-SNAPSHOT:compile [INFO] \- com.thoughtworks.paranamer:paranamer:jar:2.8:compile ``` ## How was this patch tested? Pass the Jenkins. And manually test with the sample app is running. Closes apache#23502 from dongjoon-hyun/SPARK-26583. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
-
[SPARK-26459][SQL] replace UpdateNullabilityInAttributeReferences wit…
…h FixNullability ## What changes were proposed in this pull request? This is a followup of apache#18576 The newly added rule `UpdateNullabilityInAttributeReferences` does the same thing the `FixNullability` does, we only need to keep one of them. This PR removes `UpdateNullabilityInAttributeReferences`, and use `FixNullability` to replace it. Also rename it to `UpdateAttributeNullability` ## How was this patch tested? existing tests Closes apache#23390 from cloud-fan/nullable. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Takeshi Yamamuro <yamamuro@apache.org>
-
[SPARK-26539][CORE] Remove spark.memory.useLegacyMode and StaticMemor…
…yManager ## What changes were proposed in this pull request? Remove spark.memory.useLegacyMode and StaticMemoryManager. Update tests that used the StaticMemoryManager to equivalent use of UnifiedMemoryManager. ## How was this patch tested? Existing tests, with modifications to make them work with a different mem manager. Closes apache#23457 from srowen/SPARK-26539. Authored-by: Sean Owen <sean.owen@databricks.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[SPARK-26584][SQL] Remove
spark.sql.orc.copyBatchToSparkinternal conf## What changes were proposed in this pull request? This PR aims to remove internal ORC configuration to simplify the code path for Spark 3.0.0. This removes the configuration `spark.sql.orc.copyBatchToSpark` and related ORC codes including tests and benchmarks. ## How was this patch tested? Pass the Jenkins with the reduced test coverage. Closes apache#23503 from dongjoon-hyun/SPARK-26584. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
Commits on Jan 11, 2019
-
[SPARK-25921][FOLLOW UP][PYSPARK] Fix barrier task run without Barrie…
…rTaskContext while python worker reuse ## What changes were proposed in this pull request? It's the follow-up PR for apache#22962, contains the following works: - Remove `__init__` in TaskContext and BarrierTaskContext. - Add more comments to explain the fix. - Rewrite UT in a new class. ## How was this patch tested? New UT in test_taskcontext.py Closes apache#23435 from xuanyuanking/SPARK-25921-follow. Authored-by: Yuanjian Li <xyliyuanjian@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[SPARK-26580][SQL] remove Scala 2.11 hack for Scala UDF
## What changes were proposed in this pull request? In apache#22732 , we tried our best to keep the behavior of Scala UDF unchanged in Spark 2.4. However, since Spark 3.0, Scala 2.12 is the default. The trick that was used to keep the behavior unchanged doesn't work with Scala 2.12. This PR proposes to remove the Scala 2.11 hack, as it's not useful. ## How was this patch tested? existing tests. Closes apache#23498 from cloud-fan/udf. Authored-by: Wenchen Fan <wenchen@databricks.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
-
-
-
-
Avoid the prepareExecuteStage#QueryStage method is executed multi-tim…
…es when call executeCollect, executeToIterator and executeTake action multi-times (apache#70) * Avoid the prepareExecuteStage#QueryStage method is executed multi-times when call executeCollect, executeToIterator and executeTake action multi-times * only add the check in prepareExecuteStage method to avoid duplicate check in other methods * small fix
-
[SPARK-26503][CORE] Get rid of spark.sql.legacy.timeParser.enabled
## What changes were proposed in this pull request? Per discussion in apache#23391 (comment) this proposes to just remove the old pre-Spark-3 time parsing behavior. This is a rebase of apache#23411 ## How was this patch tested? Existing tests. Closes apache#23495 from srowen/SPARK-26503.2. Authored-by: Sean Owen <sean.owen@databricks.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[SPARK-26482][CORE] Use ConfigEntry for hardcoded configs for ui cate…
…gories ## What changes were proposed in this pull request? The PR makes hardcoded configs below to use `ConfigEntry`. * spark.ui * spark.ssl * spark.authenticate * spark.master.rest * spark.master.ui * spark.metrics * spark.admin * spark.modify.acl This patch doesn't change configs which are not relevant to SparkConf (e.g. system properties). ## How was this patch tested? Existing tests. Closes apache#23423 from HeartSaVioR/SPARK-26466. Authored-by: Jungtaek Lim (HeartSaVioR) <kabhwan@gmail.com> Signed-off-by: Marcelo Vanzin <vanzin@cloudera.com>
-
[SPARK-26551][SQL] Fix schema pruning error when selecting one comple…
…x field and having is not null predicate on another one ## What changes were proposed in this pull request? Schema pruning has errors when selecting one complex field and having is not null predicate on another one: ```scala val query = sql("select * from contacts") .where("name.middle is not null") .select( "id", "name.first", "name.middle", "name.last" ) .where("last = 'Jones'") .select(count("id")) ``` ``` java.lang.IllegalArgumentException: middle does not exist. Available: last [info] at org.apache.spark.sql.types.StructType.$anonfun$fieldIndex$1(StructType.scala:303) [info] at scala.collection.immutable.Map$Map1.getOrElse(Map.scala:119) [info] at org.apache.spark.sql.types.StructType.fieldIndex(StructType.scala:302) [info] at org.apache.spark.sql.execution.ProjectionOverSchema.$anonfun$getProjection$6(ProjectionOverSchema.scala:58) [info] at scala.Option.map(Option.scala:163) [info] at org.apache.spark.sql.execution.ProjectionOverSchema.getProjection(ProjectionOverSchema.scala:56) [info] at org.apache.spark.sql.execution.ProjectionOverSchema.unapply(ProjectionOverSchema.scala:32) [info] at org.apache.spark.sql.execution.datasources.parquet.ParquetSchemaPruning$$anonfun$$nestedInanonfun$buildNewProjection$1$1.applyOrElse(Parque tSchemaPruning.scala:153) ``` ## How was this patch tested? Added tests. Closes apache#23474 from viirya/SPARK-26551. Authored-by: Liang-Chi Hsieh <viirya@gmail.com> Signed-off-by: DB Tsai <d_tsai@apple.com> -
[SPARK-26586][SS] Fix race condition that causes streams to run with …
…unexpected confs ## What changes were proposed in this pull request? Fix race condition where streams can have unexpected conf values. New streaming queries should run with isolated SparkSessions so that they aren't affected by conf updates after they are started. In StreamExecution, the parent SparkSession is cloned and used to run each batch, but this cloning happens in a separate thread and may happen after DataStreamWriter.start() returns. If a stream is started and a conf key is set immediately after, the stream is likely to have the new value. ## How was this patch tested? New unit test that fails prior to the production change and passes with it. Please review http://spark.apache.org/contributing.html before opening a pull request. Closes apache#23513 from mukulmurthy/26586. Authored-by: Mukul Murthy <mukul.murthy@gmail.com> Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
Commits on Jan 12, 2019
-
[SPARK-25692][TEST] Increase timeout in fetchBothChunks test
## What changes were proposed in this pull request? `ChunkFetchIntegrationSuite.fetchBothChunks` fails frequently due to timeout in Apache Spark Jenkins environments. ```scala org.apache.spark.network.ChunkFetchIntegrationSuite [ERROR] fetchBothChunks(org.apache.spark.network.ChunkFetchIntegrationSuite) Time elapsed: 5.015 s <<< FAILURE! java.lang.AssertionError: Timeout getting response from the server at org.apache.spark.network.ChunkFetchIntegrationSuite.fetchChunks(ChunkFetchIntegrationSuite.java:176) at org.apache.spark.network.ChunkFetchIntegrationSuite.fetchBothChunks(ChunkFetchIntegrationSuite.java:210) ``` The followings are the recent failures on `amp-jenkins-worker-05`. The timeout seems to be too sensitive in low-end machines. This PR increases the timeout from 5 seconds to 60 seconds in order to be more robust. - [master 5856](https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-maven-hadoop-2.7/5856/) - [master 5837](https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-maven-hadoop-2.7/5837/testReport) - [master 5835](https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-maven-hadoop-2.7/5835/testReport) - [master 5829](https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-maven-hadoop-2.7/5829/testReport) - [master 5828](https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-maven-hadoop-2.7/5828/testReport) - [master 5822](https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-maven-hadoop-2.7/5822/testReport) - [master 5814](https://amplab.cs.berkeley.edu/jenkins/view/Spark%20QA%20Test%20(Dashboard)/job/spark-master-test-maven-hadoop-2.7/5814/testReport) - [SparkPullRequestBuilder 100784](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/100784/consoleFull) - [SparkPullRequestBuilder 100785](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/100785/consoleFull) - [SparkPullRequestBuilder 100787](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/100787/consoleFull) - [SparkPullRequestBuilder 100788](https://amplab.cs.berkeley.edu/jenkins/job/SparkPullRequestBuilder/100788/consoleFull) ## How was this patch tested? N/A (Monitor the Jenkins on `amp-jenkins-worker-05` machine) Closes apache#23522 from dongjoon-hyun/SPARK-25692. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
-
[SPARK-26482][K8S][TEST][FOLLOWUP] Fix compile failure
## What changes were proposed in this pull request? This fixes K8S integration test compilation failure introduced by apache#23423 . ```scala $ build/sbt -Pkubernetes-integration-tests test:package ... [error] /Users/dongjoon/APACHE/spark/resource-managers/kubernetes/integration-tests/src/test/scala/org/apache/spark/deploy/k8s/integrationtest/KubernetesTestComponents.scala:71: type mismatch; [error] found : org.apache.spark.internal.config.OptionalConfigEntry[Boolean] [error] required: String [error] .set(IS_TESTING, false) [error] ^ [error] /Users/dongjoon/APACHE/spark/resource-managers/kubernetes/integration-tests/src/test/scala/org/apache/spark/deploy/k8s/integrationtest/KubernetesTestComponents.scala:71: type mismatch; [error] found : Boolean(false) [error] required: String [error] .set(IS_TESTING, false) [error] ^ [error] two errors found ``` ## How was this patch tested? Pass the K8S integration test. Closes apache#23527 from dongjoon-hyun/SPARK-26482. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
-
[SPARK-26607][SQL][TEST] Remove Spark 2.2.x testing from HiveExternal…
…CatalogVersionsSuite ## What changes were proposed in this pull request? The vote of final release of `branch-2.2` passed and the branch goes EOL. This PR removes Spark 2.2.x from the testing coverage. ## How was this patch tested? Pass the Jenkins. Closes apache#23526 from dongjoon-hyun/SPARK-26607. Authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
-
[SPARK-26538][SQL] Set default precision and scale for elements of po…
…stgres numeric array ## What changes were proposed in this pull request? When determining CatalystType for postgres columns with type `numeric[]` set the type of array element to `DecimalType(38, 18)` instead of `DecimalType(0,0)`. ## How was this patch tested? Tested with modified `org.apache.spark.sql.jdbc.JDBCSuite`. Ran the `PostgresIntegrationSuite` manually. Closes apache#23456 from a-shkarupin/postgres_numeric_array. Lead-authored-by: Oleksii Shkarupin <a.shkarupin@gmail.com> Co-authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
-
[SPARK-26564] Fix wrong assertions and error messages for parameter c…
…hecking ## What changes were proposed in this pull request? If users set equivalent values to spark.network.timeout and spark.executor.heartbeatInterval, they get the following message: ``` java.lang.IllegalArgumentException: requirement failed: The value of spark.network.timeout=120s must be no less than the value of spark.executor.heartbeatInterval=120s. ``` But it's misleading since it can be read as they could be equal. So this PR replaces "no less than" with "greater than". Also, it fixes similar inconsistencies found in MLlib and SQL components. ## How was this patch tested? Ran Spark with equivalent values for them manually and confirmed that the revised message was displayed. Closes apache#23488 from sekikn/SPARK-26564. Authored-by: Kengo Seki <sekikn@apache.org> Signed-off-by: Sean Owen <sean.owen@databricks.com>
Commits on Jan 13, 2019
-
[SPARK-26503][CORE][DOC][FOLLOWUP] Get rid of spark.sql.legacy.timePa…
…rser.enabled ## What changes were proposed in this pull request? The SQL config `spark.sql.legacy.timeParser.enabled` was removed by apache#23495. The PR cleans up the SQL migration guide and the comment for `UnixTimestamp`. Closes apache#23529 from MaxGekk/get-rid-off-legacy-parser-followup. Authored-by: Maxim Gekk <max.gekk@gmail.com> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
[SPARK-23182][CORE] Allow enabling TCP keep alive on the RPC connections
## What changes were proposed in this pull request? Make it possible for the master to enable TCP keep alive on the RPC connections with clients. ## How was this patch tested? Manually tested. Added the following: ``` spark.rpc.io.enableTcpKeepAlive true ``` to spark-defaults.conf. Observed the following on the Spark master: ``` $ netstat -town | grep 7077 tcp6 0 0 10.240.3.134:7077 10.240.1.25:42851 ESTABLISHED keepalive (6736.50/0/0) tcp6 0 0 10.240.3.134:44911 10.240.3.134:7077 ESTABLISHED keepalive (4098.68/0/0) tcp6 0 0 10.240.3.134:7077 10.240.3.134:44911 ESTABLISHED keepalive (4098.68/0/0) ``` Which proves that the keep alive setting is taking effect. It's currently possible to enable TCP keep alive on the worker / executor, but is not possible to configure on other RPC connections. It's unclear to me why this could be the case. Keep alive is more important for the master to protect it against suddenly departing workers / executors, thus I think it's very important to have it. Particularly this makes the master resilient in case of using preemptible worker VMs in GCE. GCE has the concept of shutdown scripts, which it doesn't guarantee to execute. So workers often don't get shutdown gracefully and the TCP connections on the master linger as there's nothing to close them. Thus the need of enabling keep alive. This enables keep-alive on connections besides the master's connections, but that shouldn't cause harm. Closes apache#20512 from peshopetrov/master. Authored-by: Petar Petrov <petar.petrov@leanplum.com> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[SPARK-26450][SQL] Avoid rebuilding map of schema for every column in…
… projection ## What changes were proposed in this pull request? When creating some unsafe projections, Spark rebuilds the map of schema attributes once for each expression in the projection. Some file format readers create one unsafe projection per input file, others create one per task. ProjectExec also creates one unsafe projection per task. As a result, for wide queries on wide tables, Spark might build the map of schema attributes hundreds of thousands of times. This PR changes two functions to reuse the same AttributeSeq instance when creating BoundReference objects for each expression in the projection. This avoids the repeated rebuilding of the map of schema attributes. ### Benchmarks The time saved by this PR depends on size of the schema, size of the projection, number of input files (or number of file splits), number of tasks, and file format. I chose a couple of example cases. In the following tests, I ran the query ```sql select * from table where id1 = 1 ``` Matching rows are about 0.2% of the table. #### Orc table 6000 columns, 500K rows, 34 input files baseline | pr | improvement ----|----|---- 1.772306 min | 1.487267 min | 16.082943% #### Orc table 6000 columns, 500K rows, *17* input files baseline | pr | improvement ----|----|---- 1.656400 min | 1.423550 min | 14.057595% #### Orc table 60 columns, 50M rows, 34 input files baseline | pr | improvement ----|----|---- 0.299878 min | 0.290339 min | 3.180926% #### Parquet table 6000 columns, 500K rows, 34 input files baseline | pr | improvement ----|----|---- 1.478306 min | 1.373728 min | 7.074165% Note: The parquet reader does not create an unsafe projection. However, the filter operation in the query causes the planner to add a ProjectExec, which does create an unsafe projection for each task. So these results have nothing to do with Parquet itself. #### Parquet table 60 columns, 50M rows, 34 input files baseline | pr | improvement ----|----|---- 0.245006 min | 0.242200 min | 1.145099% #### CSV table 6000 columns, 500K rows, 34 input files baseline | pr | improvement ----|----|---- 2.390117 min | 2.182778 min | 8.674844% #### CSV table 60 columns, 50M rows, 34 input files baseline | pr | improvement ----|----|---- 1.520911 min | 1.510211 min | 0.703526% ## How was this patch tested? SQL unit tests Python core and SQL test Closes apache#23392 from bersprockets/norebuild. Authored-by: Bruce Robbins <bersprockets@gmail.com> Signed-off-by: Herman van Hovell <hvanhovell@databricks.com>
-
[SPARK-26065][FOLLOW-UP][SQL] Revert hint behavior in join reordering
## What changes were proposed in this pull request? This is to fix a bug in apache#23036 that would cause a join hint to be applied on node it is not supposed to after join reordering. For example, ``` val join = df.join(df, "id") val broadcasted = join.hint("broadcast") val join2 = join.join(broadcasted, "id").join(broadcasted, "id") ``` There should only be 2 broadcast hints on `join2`, but after join reordering there would be 4. It is because the hint application in join reordering compares the attribute set for testing relation equivalency. Moreover, it could still be problematic even if the child relations were used in testing relation equivalency, due to the potential exprId conflict in nested self-join. As a result, this PR simply reverts the join reorder hint behavior change introduced in apache#23036, which means if a join hint is present, the join node itself will not participate in the join reordering, while the sub-joins within its children still can. ## How was this patch tested? Added new tests Closes apache#23524 from maryannxue/query-hint-followup-2. Authored-by: maryannxue <maryannxue@apache.org> Signed-off-by: gatorsmile <gatorsmile@gmail.com>
-
[SPARK-26576][SQL] Broadcast hint not applied to partitioned table
## What changes were proposed in this pull request? Make sure broadcast hint is applied to partitioned tables. ## How was this patch tested? - A new unit test in PruneFileSourcePartitionsSuite - Unit test suites touched by SPARK-14581: JoinOptimizationSuite, FilterPushdownSuite, ColumnPruningSuite, and PruneFiltersSuite Closes apache#23507 from jzhuge/SPARK-26576. Closes apache#23530 from jzhuge/SPARK-26576-master. Authored-by: John Zhuge <jzhuge@apache.org> Signed-off-by: gatorsmile <gatorsmile@gmail.com>
Commits on Jan 14, 2019
-
-
-
[SPARK-26456][SQL] Cast date/timestamp to string by Date/TimestampFor…
…matter ## What changes were proposed in this pull request? In the PR, I propose to switch on `TimestampFormatter`/`DateFormatter` in casting dates/timestamps to strings. The changes should make the date/timestamp casting consistent to JSON/CSV datasources and time-related functions like `to_date`, `to_unix_timestamp`/`from_unixtime`. Local formatters are moved out from `DateTimeUtils` to where they are actually used. It allows to avoid re-creation of new formatter instance per-each call. Another reason is to have separate parser for `PartitioningUtils` because default parsing pattern cannot be used (expected optional section `[.S]`). ## How was this patch tested? It was tested by `DateTimeUtilsSuite`, `CastSuite` and `JDBC*Suite`. Closes apache#23391 from MaxGekk/thread-local-date-format. Lead-authored-by: Maxim Gekk <maxim.gekk@databricks.com> Co-authored-by: Maxim Gekk <max.gekk@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
-
[SPARK-26350][SS] Allow to override group id of the Kafka consumer
## What changes were proposed in this pull request? This PR allows the user to override `kafka.group.id` for better monitoring or security. The user needs to make sure there are not multiple queries or sources using the same group id. It also fixes a bug that the `groupIdPrefix` option cannot be retrieved. ## How was this patch tested? The new added unit tests. Closes apache#23301 from zsxwing/SPARK-26350. Authored-by: Shixiong Zhu <zsxwing@gmail.com> Signed-off-by: Shixiong Zhu <zsxwing@gmail.com>
Commits on Jan 15, 2019
-
[MINOR][BUILD] Remove binary license/notice files in a source release…
… for branch-2.4+ only ## What changes were proposed in this pull request? To skip some steps to remove binary license/notice files in a source release for branch2.3 (these files only exist in master/branch-2.4 now), this pr checked a Spark release version in `dev/create-release/release-build.sh`. ## How was this patch tested? Manually checked. Closes apache#23538 from maropu/FixReleaseScript. Authored-by: Takeshi Yamamuro <yamamuro@apache.org> Signed-off-by: Sean Owen <sean.owen@databricks.com>
-
[SPARK-25935][SQL] Allow null rows for bad records from JSON/CSV parsers
## What changes were proposed in this pull request? This PR reverts apache#22938 per discussion in apache#23325 Closes apache#23325 Closes apache#23543 from MaxGekk/return-nulls-from-json-parser. Authored-by: Maxim Gekk <max.gekk@gmail.com> Signed-off-by: Wenchen Fan <wenchen@databricks.com>
-
-
[CORE][MINOR] Fix some typos about MemoryMode
## What changes were proposed in this pull request? Fix typos in comments by replacing "in-heap" with "on-heap". ## How was this patch tested? Existing Tests. Closes apache#23533 from SongYadong/typos_inheap_to_onheap. Authored-by: SongYadong <song.yadong1@zte.com.cn> Signed-off-by: Hyukjin Kwon <gurwls223@apache.org>
-
-
[SPARK-26203][SQL][TEST] Benchmark performance of In and InSet expres…
…sions ## What changes were proposed in this pull request? This PR contains benchmarks for `In` and `InSet` expressions. They cover literals of different data types and will help us to decide where to integrate the switch-based logic for bytes/shorts/ints. As discussed in [PR-23171](apache#23171), one potential approach is to convert `In` to `InSet` if all elements are literals independently of data types and the number of elements. According to the results of this PR, we might want to keep the threshold for the number of elements. The if-else approach approach might be faster for some data types on a small number of elements (structs? arrays? small decimals?). ### byte / short / int / long Unless the number of items is really big, `InSet` is slower than `In` because of autoboxing . Interestingly, `In` scales worse on bytes/shorts than on ints/longs. For example, `InSet` starts to match the performance on around 50 bytes/shorts while this does not happen on the same number of ints/longs. This is a bit strange as shorts/bytes (e.g., `(byte) 1`, `(short) 2`) are represented as ints in the bytecode. ### float / double Use cases on floats/doubles also suffer from autoboxing. Therefore, `In` outperforms `InSet` on 10 elements. Similarly to shorts/bytes, `In` scales worse on floats/doubles than on ints/longs because the equality condition is more complicated (e.g., `java.lang.Float.isNaN(filter_valueArg_0) && java.lang.Float.isNaN(9.0F)) || filter_valueArg_0 == 9.0F`). ### decimal The reason why we have separate benchmarks for small and large decimals is that Spark might use longs to represent decimals in some cases. If this optimization happens, then `equals` will be nothing else as comparing longs. If this does not happen, Spark will create an instance of `scala.BigDecimal` and use it for comparisons. The latter is more expensive. `Decimal$hashCode` will always use `scala.BigDecimal$hashCode` even if the number is small enough to fit into a long variable. As a consequence, we see that use cases on small decimals are faster with `In` as they are using long comparisons under the hood. Large decimal values are always faster with `InSet`. ### string `UTF8String$equals` is not cheap. Therefore, `In` does not really outperform `InSet` as in previous use cases. ### timestamp / date Under the hood, timestamp/date values will be represented as long/int values. So, `In` allows us to avoid autoboxing. ### array Arrays are working as expected. `In` is faster on 5 elements while `InSet` is faster on 15 elements. The benchmarks are using `UnsafeArrayData`. ### struct `InSet` is always faster than `In` for structs. These benchmarks use `GenericInternalRow`. Closes apache#23291 from aokolnychyi/spark-26203. Lead-authored-by: Anton Okolnychyi <aokolnychyi@apple.com> Co-authored-by: Dongjoon Hyun <dongjoon@apache.org> Signed-off-by: Dongjoon Hyun <dongjoon@apache.org>
-
-
Commits on Jan 22, 2019
-
* do not re-implement exchange reuse * simplify QueryStage * add comments * new idea * polish * address comments * improve QueryStageTrigger
Commits on Jan 31, 2019
-
insert query stages dynamically (#6)
* insert query stages dynamically * add comment * address comments