Releases: pyg-team/pytorch_geometric
PyG 2.6.1: Bugfixes
PyG 2.6.1 includes a bugfix in the WebQSDataset.
Bug Fixes
- Fixed a bug in the
WebQSDatasetdataset where empty edges were not treated gracefully (#9665)
Full Changelog: 2.6.0...2.6.1
PyG 2.6.0
We are excited to announce the release of PyG 2.6 🎉🎉🎉
PyG 2.6 is the culmination of work from 59 contributors who have worked on features and bug-fixes for a total of over 238 commits since torch-geometric==2.5.0.
Highlights
PyTorch 2.4 Support
PyG 2.6 is fully compatible with PyTorch 2.4, and supports the following combinations:
| PyTorch 2.2 | cpu |
cu118 |
cu121 |
cu124 |
|---|---|---|---|---|
| Linux | ✅ | ✅ | ✅ | ✅ |
| macOS | ✅ | |||
| Windows | ✅ | ✅ | ✅ | ✅ |
You can still install PyG 2.6 with an older PyTorch release up to PyTorch 1.13 in case you are not eager to update your PyTorch version.
GNNs+LLMs
In order to facilitate further research on combining GNNs with LLMs, PyG 2.6 introduces
- a new sub-package
torch_geometric.nn.nlpwith fast access toSentenceTransformermodels and LLMs - a new model
GRetrieverthat is able to co-trainLLAMA2withGATfor answering questions based on knowledge graph information - a new example folder
examples/llmthat shows how to utilize these models in practice
Index Tensor Representation
Similar to the EdgeIndex class introduced in PyG 2.5, torch-geometric==2.6.0 introduces the Index class for efficient storage of 1D indices. While Index sub-classes a general torch.Tensor, it can hold additional (meta)data, i.e.:
dim_size: The size of the underlying sparse vector, i.e. the size of a dimension that can be indexed viaIndex. By default, it is inferred asdim_size=index.max() + 1is_sorted: Whether indices are sorted in ascending order.
Additionally, Index caches data via indptr for fast CSR conversion in case its representation is sorted. Caches are filled based on demand (e.g., when calling Index.get_indptr() or when explicitly requested via Index.fill_cache_(), and are maintained and adjusted over its lifespan.
from torch_geometric import Index
index = Index([0, 1, 1, 2], dim_size=3, is_sorted=True)
assert index.dim_size == 3
assert index.is_sorted
# Flipping order:
index.flip(0)
assert not index.is_sorted
# Filtering:
mask = torch.tensor([True, True, True, False])
index[:, mask]
assert index.is_sortedEdgeIndex and Index will interact seamlessly together, e.g., edge_index[0] will now return a Index instance.
This ensures optimal computation in GNN message passing schemes, while preserving the ease-of-use of regular COO-based PyG workflows. EdgeIndex and Index will fully deprecate the usage of SparseTensor from torch-sparse in later releases, leaving us with just a single source of truth for representing graph structure information in PyG.
Breaking Changes
- Allow
Noneoutputs inFeatureStore.get_tensor()-KeyErrorshould now be raised based on the implementation inFeatureStore._get_tensor()(#9102) cugraph-based GNN layers such asCuGraphSAGEConvnow expectEdgeIndex-based inputs (#8938)
Features
Examples
- Added a multi-GPU example for training GNNs on the PCQM4M graph-level regression task (#9070)
- Added a multi-GPU
ogbn-mag240mexample (#8249) - Added support for
cugraphdata loading capabilities in thepapers100mexamples (#8173) - Improved the hyper-parameters of the [single-node](ogbn-papers100m example
](https://github.com/pyg-team/pytorch_geometric/blob/master/examples/ogbn_papers_100m.py) and [multi-node](https://github.com/pyg-team/pytorch_geometric/blob/master/examples/multi_gpu/papers100m_gcn_cugraph_multinode.py)ogbn-papers100m examples, and added evaluation on all ranks (#8823, #9386, #9445)
EdgeIndex and Index
- Added
torch_geometric.Index(#9276, #9277, #9278, #9279, #9280, #9281, #9284, #9285, #9286, #9287, #9288, #9289, #9296, #9297) - Added support for
EdgeIndexinMessagePassing(#9007, #9026, #9131) - Added support for
torch.compilein combination withEdgeIndex(#9007) - Added support for
EdgeIndex.unbind()(#9298) - Added support for
EdgeIndex.sparse_narrow()(#9291) - Added support for
EdgeIndex.sparse_resize_()(#8983)
torch_geometric.nn
- Added the
GRetrievermodel (#9480) - Added the
ClusterPoolinglayer (#9627) - Added the
PatchTransformerAggregationlayer (#9487) - Added a
residualoption inGATConvandGATv2Conv(#9515) - Added a
nlp.LLMmodel wrapper (#9462) - Added a
nlp.SentenceTransformermodel wrapper (#9350) - Added the heterogeneous
HeteroJumpingKnowledgemodule for applying jumping knowledge in heterogeneous graphs (#9380) - Added the
VariancePreservingAggregationlayer (#9075) - Added approximate
faiss-based KNN-search capabilities viaApproxKNN(#8952, #9046)
torch_geometric.metrics
- Added the
LinkPredMRRmetric (#9632)
torch_geometric.transforms
-...
Contributors
Assets 2
PyG 2.5.3: Bugfixes
PyG 2.5.3 includes a variety of bug fixes related to the MessagePassing refactoring.
Bug Fixes
- Ensure backward compatibility in
MessagePassingviatorch.load(#9105) - Prevent model compilation on custom
propagatefunctions (#9079) - Flush template file before closing it (#9151)
- Do not set
propagatemethod twice inMessagePassingfordecomposed_layers > 1(#9198)
Full Changelog: 2.5.2...2.5.3
PyG 2.5.2: Bugfixes
PyG 2.5.2 includes a bug fix for implementing MessagePassing layers in Google Colab.
Bug Fixes
- Raise error in case
inspect.get_sourceis not supported (#9068)
Full Changelog: 2.5.1...2.5.2
PyG 2.5.1: Bugfixes
PyG 2.5.1 includes a variety of bugfixes.
Bug Fixes
- Ignore
self.propagateappearances in comments when parsingMessagePassingimplementation (#9044) - Fixed
OSErroron read-only file systems withinMessagePassing(#9032) - Made
MessagePassinginterface thread-safe (#9001) - Fixed metaclass conflict in
Dataset(#8999) - Fixed import errors on
MessagePassingmodules with nested inheritance (#8973) - Fix
OSErrorwhen downloading datasets withsimplecache(#8932)
Full Changelog: 2.5.0...2.5.1
PyG 2.5.0: Distributed training, graph tensor representation, RecSys support, native compilation
We are excited to announce the release of PyG 2.5 🎉🎉🎉
PyG 2.5 is the culmination of work from 38 contributors who have worked on features and bug-fixes for a total of over 360 commits since torch-geometric==2.4.0.
Highlights
torch_geometric.distributed
We are thrilled to announce the first in-house distributed training solution for PyG via the torch_geometric.distributed sub-package. Developers and researchers can now take full advantage of distributed training on large-scale datasets which cannot be fully loaded in memory of one machine at the same time. This implementation doesn't require any additional packages to be installed on top of the default PyG stack.
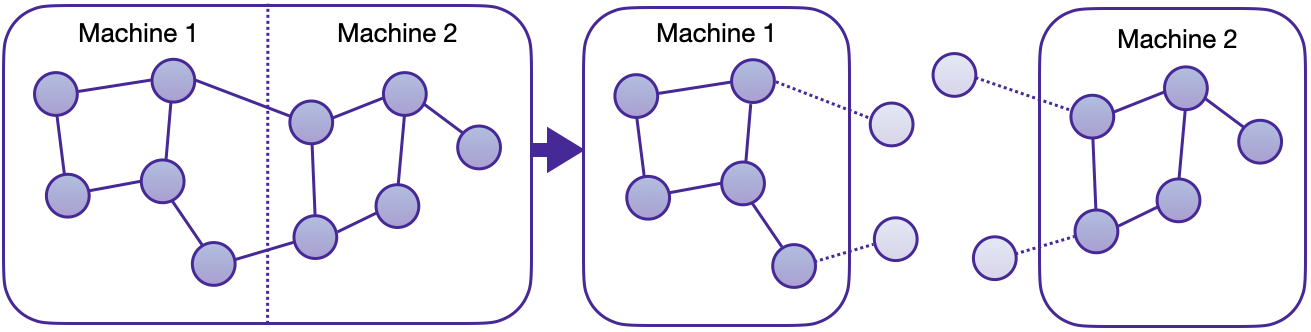
Key Advantages
- Balanced graph partitioning via METIS ensures minimal communication overhead when sampling subgraphs across compute nodes.
- Utilizing DDP for model training in conjunction with RPC for remote sampling and feature fetching routines (with TCP/IP protocol and gloo communication backend) allows for data parallelism with distinct data partitions at each node.
- The implementation via custom
GraphStoreandFeatureStoreAPIs provides a flexible and tailored interface for distributing large graph structure information and feature storage. - Distributed neighbor sampling is capable of sampling in both local and remote partitions through RPC communication channels. All advanced functionality of single-node sampling are also applicable for distributed training, e.g., heterogeneous sampling, link-level sampling, temporal sampling, etc.
- Distributed data loaders offer a high-level abstraction for managing sampler processes, ensuring simplicity and seamless integration with standard PyG data loaders.
See here for the accompanying tutorial. In addition, we provide two distributed examples in examples/distributed/pyg to get started:
- Distributed node-level classification on
ogbn-products - Distributed temporal link prediction on
MovieLens
EdgeIndex Tensor Representation
torch-geometric==2.5.0 introduces the EdgeIndex class.
EdgeIndex is a torch.Tensor, that holds an edge_index representation of shape [2, num_edges]. Edges are given as pairwise source and destination node indices in sparse COO format. While EdgeIndex sub-classes a general torch.Tensor, it can hold additional (meta)data, i.e.:
sparse_size: The underlying sparse matrix sizesort_order: The sort order (if present), either by row or columnis_undirected: Whether edges are bidirectional.
Additionally, EdgeIndex caches data for fast CSR or CSC conversion in case its representation is sorted (i.e. its rowptr or colptr). Caches are filled based on demand (e.g., when calling EdgeIndex.sort_by()), or when explicitly requested via EdgeIndex.fill_cache_(), and are maintained and adjusted over its lifespan (e.g., when calling EdgeIndex.flip()).
from torch_geometric import EdgeIndex
edge_index = EdgeIndex(
[[0, 1, 1, 2],
[1, 0, 2, 1]]
sparse_size=(3, 3),
sort_order='row',
is_undirected=True,
device='cpu',
)
>>> EdgeIndex([[0, 1, 1, 2],
... [1, 0, 2, 1]])
assert edge_index.is_sorted_by_row
assert edge_index.is_undirected
# Flipping order:
edge_index = edge_index.flip(0)
>>> EdgeIndex([[1, 0, 2, 1],
... [0, 1, 1, 2]])
assert edge_index.is_sorted_by_col
assert edge_index.is_undirected
# Filtering:
mask = torch.tensor([True, True, True, False])
edge_index = edge_index[:, mask]
>>> EdgeIndex([[1, 0, 2],
... [0, 1, 1]])
assert edge_index.is_sorted_by_col
assert not edge_index.is_undirected
# Sparse-Dense Matrix Multiplication:
out = edge_index.flip(0) @ torch.randn(3, 16)
assert out.size() == (3, 16)EdgeIndex is implemented through extending torch.Tensor via the __torch_function__ interface (see here for the highly recommended tutorial).
EdgeIndex ensures for optimal computation in GNN message passing schemes, while preserving the ease-of-use of regular COO-based PyG workflows. EdgeIndex will fully deprecate the usage of SparseTensor from torch-sparse in later releases, leaving us with just a single source of truth for representing graph structure information in PyG.
RecSys Support
Previously, all/most of our link prediction models were trained and evaluated using binary classification metrics. However, this usually requires that we have a set of candidates in advance, from which we can then infer the existence of links. This is not necessarily practical, since in most cases, we want to find the top-k most likely links from the full set of O(N^2) pairs.
torch-geometric==2.5.0 brings full support for using GNNs as a recommender system (#8452), including support for
- Maximum Inner Product Search (MIPS) via
MIPSKNNIndex - Retrieval metrics such as
f1@k,map@k,precision@k,recall@kandndcg@k, including mini-batch support
mips = MIPSKNNIndex(dst_emb)
for src_batch in src_loader:
src_emb = model(src_batch.x_dict, src_batch.edge_index_dict)
_, pred_index_mat = mips.search(src_emb, k)
for metric in retrieval_metrics:
metric.update(pred_index_mat, edge_label_index)
for metric in retrieval_metrics:
metric.compute()See here for the accompanying example.
PyTorch 2.2 Support
PyG 2.5 is fully compatible with PyTorch 2.2 (#8857), and supports the following combinations:
| PyTorch 2.2 | cpu |
cu118 |
cu121 |
|---|---|---|---|
| Linux | ✅ | ✅ | ✅ |
| macOS | ✅ | ||
| Windows | ✅ | ✅ | ✅ |
You can still install PyG 2.5 with an older PyTorch release up to PyTorch 1.12 in case you are not eager to update your PyTorch version.
Native torch.compile(...) and TorchScript Support
torch-geometric==2.5.0 introduces a full re-implementation of the MessagePassing interface, which makes it natively applicable to both torch.compile and TorchScript. As such, torch_geometric.compile is now fully deprecated in favor of [torch.compile](https://pytorch.org/docs/stable/generated/tor...
Contributors
Assets 2
PyG 2.4.0: Model compilation, on-disk datasets, hierarchical sampling
We are excited to announce the release of PyG 2.4 🎉🎉🎉
PyG 2.4 is the culmination of work from 62 contributors who have worked on features and bug-fixes for a total of over 500 commits since torch-geometric==2.3.1.
Highlights
PyTorch 2.1 and torch.compile(dynamic=True) support
The long wait has an end! With the release of PyTorch 2.1, PyG 2.4 now brings full support for torch.compile to graphs of varying size via the dynamic=True option, which is especially useful for use-cases that involve the usage of DataLoader or NeighborLoader. Examples and tutorials have been updated to reflect this support accordingly (#8134), and models and layers in torch_geometric.nn have been tested to produce zero graph breaks:
import torch_geometric
model = torch_geometric.compile(model, dynamic=True)When enabling the dynamic=True option, PyTorch will up-front attempt to generate a kernel that is as dynamic as possible to avoid recompilations when sizes change across mini-batches changes. As such, you should only ever not specify dynamic=True when graph sizes are guaranteed to never change. Note that dynamic=True requires PyTorch >= 2.1.0 to be installed.
PyG 2.4 is fully compatible with PyTorch 2.1, and supports the following combinations:
| PyTorch 2.1 | cpu |
cu118 |
cu121 |
|---|---|---|---|
| Linux | ✅ | ✅ | ✅ |
| macOS | ✅ | ||
| Windows | ✅ | ✅ | ✅ |
You can still install PyG 2.4 on older PyTorch releases up to PyTorch 1.11 in case you are not eager to update your PyTorch version.
OnDiskDataset Interface
We added the OnDiskDataset base class for creating large graph datasets (e.g., molecular databases with billions of graphs), which do not easily fit into CPU memory at once (#8028, #8044, #8046, #8051, #8052, #8054, #8057, #8058, #8066, #8088, #8092, #8106). OnDiskDataset leverages our newly introduced Database backend (sqlite3 by default) for on-disk storage and access of graphs, supports DataLoader out-of-the-box, and is optimized for maximum performance.
OnDiskDataset utilizes a user-specified schema to store data as efficient as possible (instead of Python pickling). The schema can take int, float str, object or a dictionary with dtype and size keys (for specifying tensor data) as input, and can be nested as a dictionary. For example,
dataset = OnDiskDataset(root, schema={
'x': dict(dtype=torch.float, size=(-1, 16)),
'edge_index': dict(dtype=torch.long, size=(2, -1)),
'y': float,
})creates a database with three columns, where x and edge_index are stored as binary data, and y is stored as a float.
Afterwards, you can append data to the OnDiskDataset and retrieve data from it via dataset.append()/dataset.extend(), and dataset.get()/dataset.multi_get(), respectively. We added a fully working example on how to set up your own OnDiskDataset here (#8102). You can also convert in-memory dataset instances to an OnDiskDataset instance by running InMemoryDataset.to_on_disk_dataset() (#8116).
Neighbor Sampling Improvements
Hierarchical Sampling
One drawback of NeighborLoader is that it computes a representations for all sampled nodes at all depths of the network. However, nodes sampled in later hops no longer contribute to the node representations of seed nodes in later GNN layers, thus performing useless computation. NeighborLoader will be marginally slower since we are computing node embeddings for nodes we no longer need. This is a trade-off we have made to obtain a clean, modular and experimental-friendly GNN design, which does not tie the definition of the model to its utilized data loader routine.
With PyG 2.4, we introduced the option to eliminate this overhead and speed-up training and inference in mini-batch GNNs further, which we call "Hierarchical Neighborhood Sampling" (see here for the full tutorial) (#6661, #7089, #7244, #7425, #7594, #7942). Its main idea is to progressively trim the adjacency matrix of the returned subgraph before inputting it to each GNN layer, and works seamlessly across several models, both in the homogeneous and heterogeneous graph setting. To support this trimming and implement it effectively, the NeighborLoader implementation in PyG and in pyg-lib additionally return the number of nodes and edges sampled in each hop, which are then used on a per-layer basis to trim the adjacency matrix and the various feature matrices to only maintain the required amount (see the trim_to_layer method):
class GNN(torch.nn.Module):
def __init__(self, in_channels: int, out_channels: int, num_layers: int):
super().__init__()
self.convs = ModuleList([SAGEConv(in_channels, 64)])
for _ in range(num_layers - 1):
self.convs.append(SAGEConv(hidden_channels, hidden_channels))
self.lin = Linear(hidden_channels, out_channels)
def forward(
self,
x: Tensor,
edge_index: Tensor,
num_sampled_nodes_per_hop: List[int],
num_sampled_edges_per_hop: List[int],
) -> Tensor:
for i, conv in enumerate(self.convs):
# Trim edge and node information to the current layer `i`.
x, edge_index, _ = trim_to_layer(
i, num_sampled_nodes_per_hop, num_sampled_edges_per_hop,
x, edge_index)
x = conv(x, edge_index).relu()
return self.lin(x)Corresponding examples can be found here and here.
Biased Sampling
Additionally, we added support for weighted/biased sampling in NeighborLoader/LinkNeighborLoader scenarios. For this, simply specify your edge_weight attribute during NeighborLoader initialization, and PyG will pick up these weights to perform weighted/biased sampling (#8038):
data = Data(num_nodes=5, edge_index=edge_index, edge_weight=edge_weight)
loader = NeighborLoader(
data,
num_neighbors=[10, 10],
weight_attr='edge_weight',
)
batch = next(iter(loader))New models, datasets, examples & tutorials
As part of our algorithm and documentation sprints (#7892), we have added:
- **Model components:*...
Contributors
Assets 2
Pyg 2.3.1: Bugfixes
PyG 2.3.1 includes a variety of bugfixes.
Bug Fixes
- Fixed
cugraphGNN layer support forpylibcugraphops==23.04(#7023) - Removed
DeprecationWarningofTypedStorageusage inDataLoader(#7034) - Fixed a bug in
FastHGTConvthat computed values via parameters used to compute the keys (#7050) - Fixed
numpyincompatiblity when reading files inPlanetoiddatasets (#7141) - Fixed
utils.subgraphon unordered inputs (#7187) - Fixed support for
Data.num_edgesfor nativetorch.sparse.Tensoradjacency matrices (#7104)
Full Changelog: 2.3.0...2.3.1
Pyg 2.3.0: PyTorch 2.0 support, native sparse tensor support, explainability and accelerations
We are thrilled to announce the release of PyG 2.3 🎉
PyG 2.3 is the culmination of work from 59 contributors who have worked on features and bug-fixes for a total of over 470 commits since torch-geometric==2.2.0.
Highlights
PyTorch 2.0 Support
PyG 2.3 is fully compatible with the next generation release of PyTorch, bringing many new innovations and features such as torch.compile() and Python 3.11 support to PyG out-of-the-box. In particular, many PyG models and functions are speeded up significantly using torch.compile() in torch >= 2.0.0.
We have prepared a full tutorial and a set of examples to get you going with torch.compile() immediately:
import torch_geometric
from torch_geometric.nn import GraphSAGE
model = GraphSAGE(in_channels, hidden_channels, num_layers, out_channels)
model = model.to(device)
model = torch_geometric.compile(model)Overall, we observed runtime improvements of nearly up to 300%:
| Model | Mode | Forward | Backward | Total | Speedup |
|---|---|---|---|---|---|
GCN |
Eager | 2.6396s | 2.1697s | 4.8093s | |
GCN |
Compiled | 1.1082s | 0.5896s | 1.6978s | 2.83x |
GraphSAGE |
Eager | 1.6023s | 1.6428s | 3.2451s | |
GraphSAGE |
Compiled | 0.7033s | 0.7465s | 1.4498s | 2.24x |
GIN |
Eager | 1.6701s | 1.6990s | 3.3690s | |
GIN |
Compiled | 0.7320s | 0.7407s | 1.4727s | 2.29x |
Please note that torch.compile() within PyG is in beta mode and under active development. For example, currently torch.compile(model, dynamic=True) does not yet work seamlessly, but fixes are on its way. We are very eager to improve its support across the whole PyG code base, so do not hesitate to reach out if you notice anything unexpected.
Infrastructure Changes
With the recent upstreams of torch-scatter and torch-sparse to native PyTorch, we are happy to announce that any installation of the extension packages torch-scatter, torch-sparse, torch-cluster and torch-spline-conv is now fully optional.
All it takes to install PyG is now encapsulated into a single command
pip install torch-geometric
and finally resolves a lot of previous installation issues.
Extension packages are still picked up for the following use-cases (if installed):
pyg-lib: Heterogeneous GNN operators and graph sampling routines likeNeighborLoadertorch-scatter: Accelerated"min"and"max"reductionstorch-sparse:SparseTensorsupporttorch-cluster: Graph clustering routines likeknnorradiustorch-spline-conv:SplineConvsupport
We recommend to start with a minimal installation, and only install additional dependencies once you actually get notified about them being missing during PyG usage.
Native PyTorch Sparse Tensor Support
With the recent additions of torch.sparse_csr_tensor and torch.sparse_csc_tensor classes and accelerated sparse matrix multiplication routines to PyTorch, we finally enable MessagePassing on pure PyTorch sparse tensors as well. In particular, you can now use torch.sparse_csr_tensor and torch.sparse_csc_tensor as a drop-in replacement for torch_sparse.SparseTensor:
from torch_geometric.nn import GCN
import torch_geometric.transforms as T
from torch_geometric.datasets import Planetoid
transform = T.ToSparseTensor(layout=torch.sparse_csr)
dataset = Planetoid("Planetoid", name="Cora", transform=transform)
model = GCN(in_channels, hidden_channels, num_layers=2)
model = model(data.x, data.adj_t)Nearly all of the native PyG layers have been tested to work seamlessly with native PyTorch sparse tensors (#5906, #5944, #6003, #6033, #6514, #6532, #6748, #6847, #6868, #6874, #6897, #6930, #6932, #6936, #6937, #6939, #6947, #6950, #6951, #6957).
Explainability Framework
In PyG 2.2 we introduced the torch_geometric.explain package that provides a flexible interface to generate and visualize GNN explanations using various algorithms. We are happy to add the following key improvements on this front:
- Support for explaining heterogeneous GNNs via
HeteroExplanation - New visualization tools to
visualize_feature_importanceand tovisualize_graphexplanations - May new datasets and metrics to evaluate explanation algorithms
- Several new explanation algorithms such as
CaptumExplainer,PGExplainer,AttentionExplainer,PGMExplainer, andGraphMaskExplainer - Support for node-level, link-level and graph-level explanations
Using the new explainer interface is as simple as:
explainer = Explainer(
model=model,
algorithm=CaptumExplainer('IntegratedGradients'),
explanation_type='model',
model_config=dict(
mode='multiclass_classification',
task_level='node',
return_type='log_probs',
),
node_mask_type='attributes',
edge_mask_type='object',
)
explanation = explainer(data.x, data.edge_index)Read more about torch_geometric.explain in our newly added tutorial and example scripts. We also added a blog post that describes the new int...
Contributors
Assets 2
PyG 2.2.0: Accelerations and Scalability
We are excited to announce the release of PyG 2.2 🎉🎉🎉
PyG 2.2 is the culmination of work from 78 contributors who have worked on features and bug-fixes for a total of over 320 commits since torch-geometric==2.1.0.
Highlights
pyg-lib Integration
We are proud to release and integrate pyg-lib==0.1.0 into PyG, the first stable version of our new low-level Graph Neural Network library to drive all CPU and GPU acceleration needs of PyG (#5330, #5347, #5384, #5388).
You can install pyg-lib as described in our README.md:
pip install pyg-lib -f https://data.pyg.org/whl/torch-${TORCH}+${CUDA}.html
import pyg_libOnce pyg-lib is installed, it will get automatically picked up by PyG, e.g., to accelerate neighborhood sampling routines or to accelerate heterogeneous GNN execution:
pyg-libprovides fast and optimized CPU routines to iteratively sample neighbors in homogeneous and heterogeneous graphs, and heavily improves upon the previously used neighborhood sampling techniques utilized in PyG.

pyg-libprovides efficient GPU-based routines to parallelize workloads in heterogeneous graphs across different node types and edge types. We achieve this by leveraging type-dependent transformations via NVIDIA CUTLASS integration, which is flexible to implement most heterogeneous GNNs with, and efficient, even for sparse edge types or a large number of different node types.

GraphStore and FeatureStore Abstractions
PyG 2.2 includes numerous primitives to easily integrate with simple paradigms for scalable graph machine learning, enabling users to train GNNs on graphs far larger than the size of their machine's available memory. It does so by introducing simple, easy-to-use, and extensible abstractions of a FeatureStore and a GraphStore that plug directly into existing familiar PyG interfaces (see here for the accompanying tutorial).
feature_store = CustomFeatureStore()
feature_store['paper', 'x', None] = ... # Add paper features
feature_store['author', 'x', None] = ... # Add author features
graph_store = CustomGraphStore()
graph_store['edge', 'coo'] = ... # Add edges in "COO" format
# `CustomGraphSampler` knows how to sample on `CustomGraphStore`:
graph_sampler = CustomGraphSampler(
graph_store=graph_store,
num_neighbors=[10, 20],
...
)
from torch_geometric.loader import NodeLoader
loader = NodeLoader(
data=(feature_store, graph_store),
node_sampler=graph_sampler,
batch_size=20,
input_nodes='paper',
)
for batch in loader:
passData loading and sampling routines are refactored and decomposed into torch_geometric.loader and torch_geometric.sampler modules, respectively (#5563, #5820, #5456, #5457, #5312, #5365, #5402, #5404, #5418).
Optimized and Fused Aggregations
PyG 2.2 further accelerates scatter aggregations based on CPU/GPU and with/without backward computation paths (requires torch>=1.12.0 and torch-scatter>=2.1.0) (#5232, #5241, #5353, #5386, #5399, #6051, #6052).
We also optimized the usage of nn.aggr.MultiAggregation by fusing the computation of multiple aggregations together (see here for more details) (#6036, #6040).
Here are some benchmarking results on PyTorch 1.12 (summed over 1000 runs):
| Aggregators | Vanilla | Fusion |
|---|---|---|
[sum, mean] |
0.3325s | 0.1996s |
[sum, mean, min, max] |
0.7139s | 0.5037s |
[sum, mean, var] |
0.6849s | 0.3871s |
[sum, mean, var, std] |
1.0955s | 0.3973s |
Lastly, we have incorporated "fused" GNN operators via the dgNN package, starting with a FusedGATConv implementation (#5140).
Community Sprint: Type Hints and TorchScript Support
We are running regular community sprints to get our community more involved in building PyG. Whether you are just beginning to use graph learning or have been leveraging GNNs in research or production, the community sprints welcome members of all levels with different types of projects.
We had our first community sprint on 10/12 to fully-incorporate type hints and TorchScript support over the entire code base. The goal was to improve usability and cleanliness of our codebase. We had 20 contributors participating, contributing to 120 type hints within 2 weeks, adding around 2400 lines of code (#5842, #5603, #5659, #5664, #5665, #5666, #5667, #5668, #5669, #5673, #5675, #5673, #5678, #5682, #5683, #5684, #5685, #5687, #5688, #5695, #5699, #5701, #5702, #5703, #5706, #5707, #5710, #5714, #5715, #5716, #5722, #5724, #5725, #5726, #5729, #5730, #5731, #5732, [#5733](https://github.com/pyg-team/pyt...